
Airflow 做 ETL,真不是“排个 DAG 就完事儿”:那些年我踩过的坑与悟出的道
大家好,我是 Echo_Wish,一个在大数据 ETL 世界里摸爬滚打多年、见过无数 Airflow“惨案”的人。
很多同学以为 Airflow = 画个 DAG + 写个 Operator + 放到生产跑,图简单、逻辑清晰、界面也漂亮,看起来“稳得一批”。
但真上生产后你会发现:
Airflow 好用,但绝对不会自动变好用。
配置不合理、调度不规范、任务不隔离、Operator 滥用、XCom 滥发消息……这些问题不踩上几次,根本意识不到它们有多“致命”。
今天我就跟你聊聊:
怎么用 Airflow 搭一个真的能扛生产的 ETL 系统 —— 并顺便告诉你哪些坑必须绕开。
一、Airflow 最容易犯的错误:把它当“任务执行器”而不是“调度编排器”
我见过不少项目把 Airflow 当成“万能胶”:
- 数据清洗写在 PythonOperator
- 数据加工写在 BashOperator
- 数据入仓也写在 PythonOperator
- 拖个 DockerOperator 跑 Spark 任务
- 甚至有团队把 MySQL 的小 SQL 都塞到 PythonOperator 里执行…
结果 DAG 看起来像一大坨年糕,谁也不敢动,改一个节点要跪十分钟祈祷不爆炸。
正确做法应该是:
✔ Airflow 做 编排 —— 决定什么任务什么时候跑
✔ 真正的数据处理任务交给 Spark / Flink / 任务脚本
✔ Airflow 只负责触发 & 监控,不负责计算
所以 在 DAG 里偷懒写大量逻辑,是最不应该的行为。
二、上生产前必须具备的 ETL DAG 基本形态
话不多说,给你一个能上生产的基础 DAG 模版,里面包含了一些最佳实践。
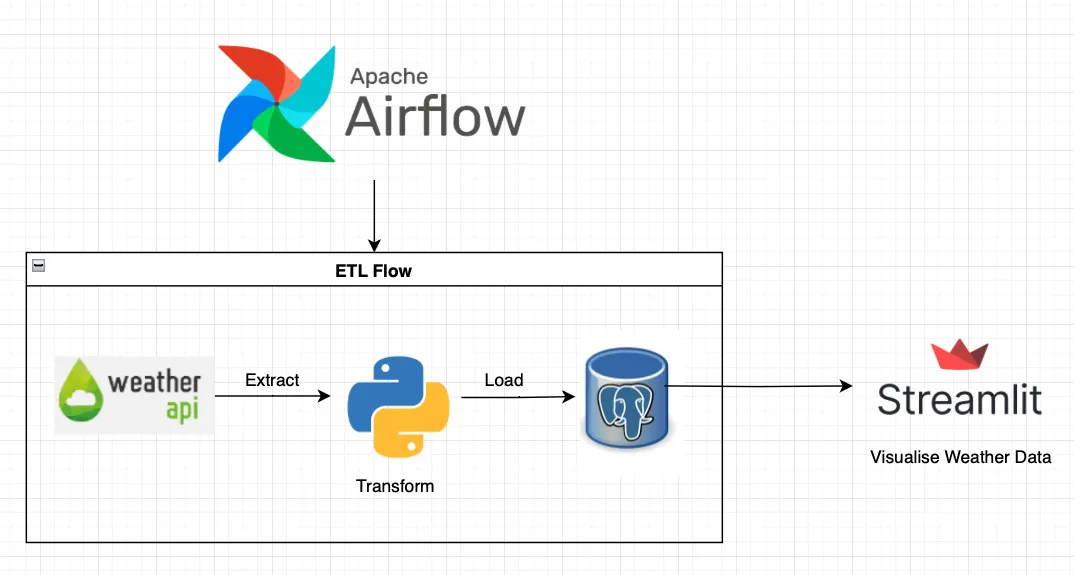
示范代码:带重试、隔离、任务边界清晰的 ETL DAG
from datetime import datetime, timedelta
from airflow import DAG
from airflow.providers.cncf.kubernetes.operators.kubernetes_pod import KubernetesPodOperator
from airflow.operators.empty import EmptyOperator
default_args = {
"owner": "echo_wish",
"email": ["alert@datapipeline.com"],
"email_on_failure": True,
"retries": 2, # 必须要有重试
"retry_delay": timedelta(minutes=5),
"depends_on_past": False, # ETL 不推荐依赖过去状态
}
with DAG(
dag_id="etl_sales_daily",
start_date=datetime(2024, 1, 1),
schedule_interval="0 1 * * *", # 每天凌晨1点跑
catchup=False, # 避免一次补几千天的“悲剧”
default_args=default_args
) as dag:
start = EmptyOperator(task_id="start")
extract = KubernetesPodOperator(
task_id="extract_raw_data",
name="extract-task",
namespace="airflow-jobs",
image="etl/extract:latest",
cmds=["python", "extract.py"],
arguments=["--date", "{
{ ds }}"],
is_delete_operator_pod=True
)
transform = KubernetesPodOperator(
task_id="transform_data",
name="transform-task",
namespace="airflow-jobs",
image="etl/transform:latest",
cmds=["python", "transform.py"],
arguments=["--date", "{
{ ds }}"],
is_delete_operator_pod=True
)
load = KubernetesPodOperator(
task_id="load_to_dwh",
name="load-task",
namespace="airflow-jobs",
image="etl/load:latest",
cmds=["python", "load.py"],
arguments=["--date", "{
{ ds }}"],
is_delete_operator_pod=True
)
end = EmptyOperator(task_id="end")
start >> extract >> transform >> load >> end
你会发现几个核心点:
- 用 KubernetesPodOperator 跑任务,真正做到完全隔离
- 每一步都拆开,逻辑清晰明了
- ETL 代码不写在 DAG 里,Airflow 只是个 orchestrator
- 重试、邮件、调度、任务边界全部规范
如果你现在的 DAG 长得不像这样,那大概率有优化空间。
三、Airflow 搭 ETL 经常被忽视的关键设计
1. DAG 要小,不要大
很多项目喜欢弄一个“大而全”的 DAG,每天跑几十个节点。
出了问题根本不知道是哪个子流程挂了。
更优解:
✔ 一条业务链路一个 DAG
✔ 一个表一个 DAG(特别是快照/宽表)
✔ 公共依赖拆成子 DAG 或者单独维护
越小越好管理,这是真理。
2. XCom 慎用:不要把大对象丢进去
我见过最魔幻的 Airflow 事故:
某同事把一个 100MB 的 Pandas DataFrame 通过 XCom 往下游传……
Airflow 的 metadata DB(MySQL/Postgres)瞬间爆炸。
原则:XCom 只能传 Metadata、小量字符串,不传数据本体。
怎么传数据?
✔ 上传到 OSS/S3/HDFS
✔ XCom 里只放路径
3. 不要把 Airflow 当成“查询引擎”
反模式例子:
# 千万不要这样写
def really_bad_task():
import pandas as pd
df = pd.read_sql("SELECT * FROM big_table", conn)
... # 本地处理
你会让 scheduler / worker 直接打 DB,造成:
- DB 压力飙升
- Worker 内存打爆
- 性能惨不忍睹
正确姿势:
✔ DB → 外部脚本/Spark 处理
✔ Airflow 只触发脚本,不做 heavy load
4. 所有 ETL 镜像必须可重复执行、幂等、安全回滚
为什么?
因为 Airflow 的哲学是:
任务可以失败,但不能留下脏数据。
所以你的 ETL 脚本必须遵守:
- 同一天跑多少次,结果必须一致
- 如果失败要能回滚
- load 阶段要么全成功,要么全部失败
四、我踩过最痛的坑:依赖管理混乱
Airflow 里依赖一旦搞乱,你会看到:
- 任务 A 明明成功了,但任务 B 不跑
- 因为一个节点卡住,整个 DAG 挂在那里十小时
- 新增节点导致循环依赖,直接跑不起来
最糟糕的“反面教材”就是写成树状 + 多个分支互相引用。
正确思路:它必须是一条链,或者清晰的树,而不是蜘蛛网。
如果 DAG 长这样,那你就成功打造了生产事故:
[外链图片转存中...(img-cNI7A7JU-1765548424463)]

五、关于监控:Airflow 不等于运维系统
Airflow 自带的监控并不够,它只告诉你:
- 成功
- 失败
- 超时
- 重试
但真正的生产 ETL 需要:
✔ 数据量监控(比如今天入库 100W,昨天 200W,是不是异常?)
✔ 数据质量监控(空值、重复、业务约束)
✔ 延迟监控(下游 SLA)
✔ 元数据记录(血缘、字段变更)
所以 Airflow 不能独立支撑所有需求,必须补上:
- Prometheus + Grafana
- 数据质量工具(Great Expectations、Deequ)
- 元数据管理(DataHub、Amundsen)
六、写在最后:Airflow 本质上是“纪律工具”
这么多年用下来我有一个特别深的感受:
Airflow 的根问题不在技术,而在团队习惯。
- 如果大家喜欢把逻辑塞到 DAG 里 → DAG 会腐烂
- 如果大家不遵守幂等、分离职责、轻逻辑原则 → ETL 会混乱
- 如果业务不愿意规范数据结构 → 后端永远在救火
Airflow 是个非常成熟、强大、稳定的调度系统。
真正让它变得“不稳定”的,是使用它的人。
只要记住一句话:
Airflow 做 ETL,不是搭一个系统,而是培养一套团队工程文化。

