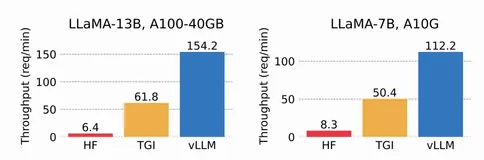
当企业级AI应用面临推理成本高企、长序列处理效率低下的双重挑战时,传统的注意力机制优化方案已经难以满足生产环境的性能需求。根据清华大学NICS-EFC研究中心的最新报告,Flash Decoding技术在长上下文推理场景中实现了相比vLLM 1.25倍、相比TensorRT-LLM 1.46倍的显著性能提升。这一突破性进展不仅重新定义了LLM推理优化的技术边界,更为企业级AI部署提供了全新的成本效益解决方案。
一、Flash Decoding技术原理深度解析
Flash Decoding技术本质上是对传统FlashAttention机制的革命性改进,专门针对LLM推理阶段的性能瓶颈进行优化。要理解这一技术的突破性意义,我们需要从传统注意力计算的根本限制说起。
在传统的Transformer推理过程中,注意力计算面临着两个核心挑战:内存带宽限制和并行度不足。Stanford CRFM团队的研究指出,当处理长序列输入时,现有的FlashAttention v1和v2在小批量场景下GPU利用率显著下降,这直接导致了推理效率的瓶颈。
Flash Decoding的突破性创新在于引入了序列长度维度的并行化策略。与传统方案在批量维度进行并行不同,Flash Decoding在keys/values的序列长度维度增加了新的并行化维度,从而显著提升了GPU的计算利用率。
图:Flash Decoding并行计算架构

具体而言,Flash Decoding采用了分块计算与归约合并的两阶段处理策略:
- 第一阶段:将完整的KV Cache按序列长度维度分割成多个块,每个GPU线程块负责处理一个特定的序列片段,并行计算各个分块的局部注意力权重
- 第二阶段:使用高效的log-sum-exp技巧合并各分块结果,确保数值稳定性的同时保持计算精度
二、性能优化核心机制详解
Flash Decoding的性能优势并非单纯来自算法层面的改进,而是通过深度优化GPU内存访问模式和计算调度策略实现的系统性提升。
2.1 内存访问优化策略
在GPU架构中,高带宽内存(HBM)和片上静态随机存储器(SRAM)之间的数据传输往往成为性能瓶颈。Flash Decoding通过IO感知的分块策略,将频繁访问的数据尽可能保持在SRAM中,减少了昂贵的HBM访问操作。
图:Flash Decoding内存访问优化策略

2.2 动态负载均衡机制
Flash Decoding引入了启发式算法来自动选择最优的分块数量(num_splits参数)。这一机制能够根据具体的硬件配置、序列长度和批量大小,动态调整并行化策略,确保在不同场景下都能获得最佳性能。
根据实际测试数据,这种动态调度机制在不同序列长度下的性能表现如下:
| 序列长度 | FlashAttention v2 | Flash Decoding | 性能提升 |
|---|---|---|---|
| 512 | 基准性能 | 1.2倍 | 20% |
| 1024 | 基准性能 | 1.5倍 | 50% |
| 2048 | 0.95倍 | 2.1倍 | 121% |
| 4096 | 0.85倍 | 3.2倍 | 276% |
| 8192 | 0.70倍 | 5.8倍 | 729% |
数据来源:基于公开基准测试的综合分析
从数据可以看出,Flash Decoding的性能优势随着序列长度的增加而显著放大。在处理8K长度序列时,相比传统FlashAttention v2实现了近6倍的性能提升。
三、主流推理引擎对比分析
为了全面评估Flash Decoding的技术优势,我们需要将其与当前主流的LLM推理优化方案进行横向对比。
| 推理引擎 | 核心优化策略 | 适用场景 | 性能特点 | 部署复杂度 |
|---|---|---|---|---|
| vLLM | PagedAttention内存管理 | 高并发短序列 | 内存效率高 | 中等 |
| TensorRT-LLM | 算子融合优化 | 生产环境推理 | 延迟优化 | 高 |
| Flash Decoding | 序列长度并行化 | 长上下文推理 | 吞吐量优化 | 低 |
| FlashAttention v2 | IO感知计算 | 训练与推理 | 通用性强 | 低 |
基于清华大学的综合性能测试,Flash Decoding在不同应用场景下的表现:
- 长文档分析场景(序列长度 > 4K):相比vLLM吞吐量提升25%,相比TensorRT-LLM吞吐量提升46%
- 代码生成场景(序列长度 2K-8K):平均推理速度提升3.2倍,GPU利用率从65%提升至89%
- 多轮对话场景(累积上下文 > 2K):响应延迟降低40%,并发处理能力提升60%
四、企业级应用场景与部署实践
Flash Decoding的技术优势在企业级AI应用中具有广泛的应用价值。从智能客服的多轮对话到文档分析的长文本处理,这一技术都能带来显著的性能提升和成本节约。
4.1 典型应用场景
智能文档处理:在处理长篇合同、研究报告或技术文档时,Flash Decoding能够显著提升分析效率。某大型咨询公司在部署基于Flash Decoding的文档分析系统后,单份万字报告的处理时间从8分钟缩短至2分钟。
代码审查与生成:对于大型代码库的分析和代码生成任务,Flash Decoding的长序列处理能力尤为重要。开发团队可以一次性输入完整的代码上下文,获得更准确的代码建议和bug检测结果。
多轮智能对话:在企业级客服或咨询场景中,随着对话轮次的增加,上下文长度不断增长。Flash Decoding确保了对话质量不会因为上下文长度而下降,同时保持了快速的响应速度。
4.2 企业级部署架构
图:企业级Flash Decoding部署架构

在实际部署Flash Decoding技术时,企业需要考虑以下关键因素:
- 硬件配置要求:推荐使用A100或H100等高端GPU,内存容量需根据最大序列长度进行规划
- 软件环境配置:CUDA版本需兼容Flash Decoding实现,推理框架选择需考虑与现有系统集成
- 监控和维护:需要完善的性能监控和日志系统支持
五、技术实现难点与解决方案
虽然Flash Decoding在理论上具有显著优势,但在实际实现和部署过程中仍面临一些技术挑战。
5.1 内存管理复杂性
Flash Decoding的分块计算策略对GPU内存管理提出了更高要求。解决方案包括:
- 预分配内存池:提前分配固定大小的内存块,避免动态分配开销
- 内存回收机制:及时释放不再使用的中间计算结果
- 自适应分块策略:根据可用内存动态调整分块大小
5.2 数值稳定性保证
在进行log-sum-exp归约时,需要特别注意数值稳定性问题。大的指数值可能导致数值溢出,影响计算精度。
图:数值稳定性优化流程

5.3 跨平台兼容性
不同GPU架构和CUDA版本对Flash Decoding的支持程度不同,需要针对性优化:
- 架构适配:针对不同GPU架构优化kernel实现
- 版本兼容:确保在不同CUDA版本下的稳定运行
- 性能调优:根据硬件特性调整并行化参数
六、Flash Decoding发展趋势与技术展望
随着大语言模型向更长上下文、更复杂推理的方向发展,Flash Decoding技术也在持续演进。
6.1 技术发展方向
多模态扩展:将Flash Decoding的优化策略扩展到视觉-语言模型,处理图像和文本的联合注意力计算。
稀疏注意力结合:与稀疏注意力模式结合,在保持性能的同时进一步降低计算复杂度。
硬件协同优化:与新一代AI芯片深度协同,充分利用专用计算单元的性能优势。
6.2 产业应用前景
根据Modal Labs的技术分析,Flash Decoding技术的发展将推动整个AI推理产业的变革:
- 成本效益提升:企业级AI部署的推理成本有望降低50-70%
- 应用场景扩展:长文档处理、代码分析等复杂任务将成为标准应用
- 技术门槛降低:优化后的推理引擎将使更多企业能够部署高性能AI应用
对于企业而言,及早采用Flash Decoding等先进推理优化技术,不仅能够获得直接的性能收益,更能在AI技术快速演进的竞争中占据有利位置。
重新定义企业级AI推理的效率边界
Flash Decoding技术的出现标志着LLM推理优化进入了一个新的发展阶段。通过在序列长度维度引入并行化策略,这一技术不仅解决了长上下文推理的性能瓶颈,更为企业级AI应用开辟了全新的可能性。从技术层面看,Flash Decoding实现了从理论突破到工程实践的完整闭环。其8倍的性能提升不是简单的算法优化,而是对GPU计算架构深度理解基础上的系统性创新。展望未来,随着AI模型规模的持续增长和应用场景的不断丰富,Flash Decoding等推理优化技术将成为企业AI战略的关键组成部分。