

一、为什么要了解Transformer?
Transformer 是现代大模型(如 GPT、BERT、Claude、Gemini)的基石。 它不是“神秘黑箱”,而是一组高度模块化、可验证、可测的数学与工程结构。 对测试开发从业者来说,理解 Transformer 的原理不仅能帮助你:
更好地理解大模型推理、微调和RAG机制;
设计针对 AI 模块的自动化测试策略;
分析和排查 AI 模型在不同输入分布下的异常表现;
甚至能帮助构建更智能的“AI测试智能体”。
这篇文章我们整理了 21 个高频 Transformer 面试题,并结合测试开发视角给出理解路径。 不是背答案,而是理解逻辑。
二、Transformer 核心原理与思维导图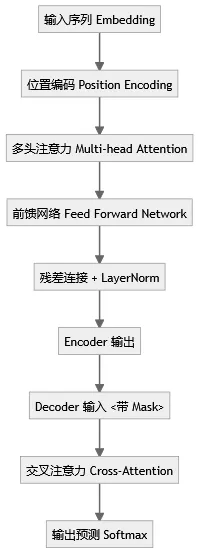
三、21个高频面试题精讲与思路指引
为什么使用多头注意力机制?
一个注意力头容易只“关注”输入的某个维度信息(比如句法关系),多头机制能从多个子空间并行捕捉不同的依赖模式。 从测试角度看,多头意味着并行子空间的可分测试单元,可在不同 head 输出之间做一致性或信息熵对比测试。Q、K 为什么使用不同权重矩阵?
如果 Q 和 K 使用相同权重,模型的“自注意”会退化成自相关匹配,失去语义可分性。 分开权重相当于给模型提供了“提问者”和“被提问者”的不同视角。点乘注意力 vs 加法注意力?
点乘注意力计算快(矩阵乘法可并行),而加法注意力计算量大但在低维场景下更稳。 Transformer 选择点乘,是为了在 GPU 计算下优化并行度。为什么要除以 √dk?
点乘后数值容易过大,Softmax梯度趋于平坦,导致训练不稳定。 除以 √dk 是对方差进行归一化,让梯度处于合适区间。 这是经典的数值稳定性优化点,测试时要关注溢出与下溢风险。如何对 padding 做 mask?
在 attention score 上添加 mask,将 padding 部分赋值为 -∞,保证 Softmax 后概率接近 0。 测试开发时,这属于典型的“边界输入覆盖”场景。为什么每个 head 要降维?
如果不降维,多头拼接后维度会爆炸。降维是为了控制参数规模,同时确保每个 head 在有限维度内学习特征。Transformer Encoder 模块结构?
Encoder = 多头注意力 + 前馈网络 + 残差 + LayerNorm。 测试点:注意力权重矩阵维度对齐性、残差路径梯度流。为什么 embedding 要乘以 √dmodel?
Embedding 取值一般较小,乘以 √dmodel 能保持与位置编码的数值尺度一致。Transformer 的位置编码?
通过正弦余弦函数生成一组固定频率的编码,让模型能感知词序。 这是 Transformer 摒弃 RNN 的关键创新。了解哪些位置编码改进?
如可学习位置编码、旋转位置编码(RoPE)、ALiBi等。 测试场景:不同位置编码在长文本截断或padding场景下的性能差异。Transformer 的残差结构意义?
残差能避免梯度消失,并保持信息跨层流动,是稳定训练的关键。 可测试点:残差路径梯度流是否在多层累积时衰减。为什么使用 LayerNorm 而非 BatchNorm?
因为 Transformer 在序列任务中每个样本长度不一,BatchNorm 不稳定。 LayerNorm 对每个样本独立归一化,数值更平稳。BatchNorm 技术优缺点?
优点:加快收敛,防止梯度爆炸。 缺点:依赖 batch 统计量,不适用于变长序列。 在测试部署时,BatchNorm 还会导致推理与训练分布不一致问题。前馈神经网络结构?
两层线性层 + 激活函数(ReLU/GELU)。 测试时可关注激活函数在不同数值区间的梯度饱和现象。Encoder 与 Decoder 的交互?
Decoder 在计算时会使用 Encoder 输出的上下文向量进行 cross-attention。 测试重点:mask机制正确性、上下文对齐性。Transformer 的并行化体现在哪?
Encoder 内部结构可完全并行,Decoder 因自回归依赖而部分串行。 测试可关注“缓存机制”是否有效加速推理。WordPiece 与 BPE?
两者都是子词分词算法,前者基于统计概率,后者基于频率合并规则。 测试时常用于验证 token 一致性与反向解码准确率。Dropout 如何设定?
一般在 attention 输出、前馈层输出、embedding 后使用。 测试时要注意 eval 模式下 Dropout 是否被关闭。学习率设定?
Transformer 通常使用 warmup + decay 策略,即前期升温、后期指数衰减。 测试可关注学习率曲线是否正确实现。Decoder 可以完全并行吗?
不可以。Decoder 是自回归生成,每个 token 依赖前一个输出。 但可使用缓存机制(如 KV cache)加速推理。测试开发者关注点:如何测 Transformer?
维度正确性测试:Q、K、V矩阵维度对齐;
梯度稳定性测试:残差路径、归一化层输出分布;
mask正确性测试:Padding与未来token屏蔽是否有效;
性能测试:多头并行、GPU显存占用、推理吞吐量。
四、如何入门Transformer测试?
对于测试开发同学,不需要立刻啃论文。建议路线:
从 Attention公式 开始,用 NumPy 手写一遍;
用 PyTorch 实现简化版 TransformerBlock;
学会在 forward 中插入 Hook,捕获中间层输出;
写出第一个 “Transformer 模型验证脚本”,验证 mask、维度、梯度稳定性;
再理解微调(Fine-tune)与推理阶段(Inference)差异。
五、写在最后
Transformer 不仅是大模型的心脏,也是 AI 测试开发的“试金石”。 能理解它的工程逻辑,你就能测任何大模型系统。 未来测试工程师,不只是写用例的执行者,而是 AI 系统的结构验证者。
