引言
随着大型语言模型(LLM)规模的不断扩大和应用场景的日益复杂,推理性能已成为制约模型实际部署和应用的关键因素。尽管大模型在各项任务上展现出了令人惊艳的能力,但其庞大的参数量和计算需求也带来了严峻的性能挑战。在资源受限的环境中,如何在保持模型效果的同时,最大化推理性能,成为了研究人员和工程师们亟待解决的核心问题。
推理优化技术通过各种方法减少计算量、降低内存占用、提高并行效率,从而显著提升模型的推理速度和吞吐量。本文将深入探讨LLM推理优化的核心技术,包括KV缓存优化、子图融合、模型量化、批处理策略等,并分析它们的原理、实现方法和性能影响。我们将结合最新的研究成果和工业实践,为读者提供全面而实用的LLM推理优化指南。
推理优化的重要性
在实际应用中,推理性能直接影响用户体验和系统成本:
- 响应延迟:对于实时应用,如聊天机器人、语音助手等,低延迟是保证良好用户体验的关键
- 吞吐量:高吞吐量意味着系统可以同时服务更多用户,提高资源利用率
- 资源消耗:优化推理性能可以显著降低GPU/TPU等硬件资源的消耗,减少运行成本
- 部署灵活性:优化后的模型可以在更广泛的设备上部署,包括边缘设备和移动终端
- 能源效率:提高推理效率意味着更低的能源消耗,符合绿色计算的发展趋势
优化挑战与目标
LLM推理优化面临着多重挑战:
- 模型规模庞大:现代LLM通常包含数百亿甚至数千亿参数,远超单个设备的内存容量
- 自回归生成机制:LLM的逐token生成机制限制了并行性
- 内存带宽瓶颈:频繁的内存访问成为制约性能的主要因素
- 精度与性能的权衡:过度优化可能导致模型效果下降
- 硬件多样性:需要针对不同硬件平台(GPU、CPU、专用加速器等)进行优化
推理优化的主要目标包括:
- 降低延迟:减少单个推理请求的响应时间
- 提高吞吐量:增加单位时间内可处理的请求数量
- 减少内存占用:降低模型运行所需的内存空间
- 提高能源效率:降低单位计算的能源消耗
- 保持模型效果:在优化的同时,尽量维持模型的性能和质量
KV缓存原理与优化
KV缓存概述
KV缓存(Key-Value Cache)是LLM推理优化中最基础也最重要的技术之一。在Transformer架构中,自注意力机制需要计算每个token与其他所有token之间的注意力分数,这是一个计算密集型操作。KV缓存通过存储中间计算结果,避免了重复计算,显著提高了推理效率。
基本原理
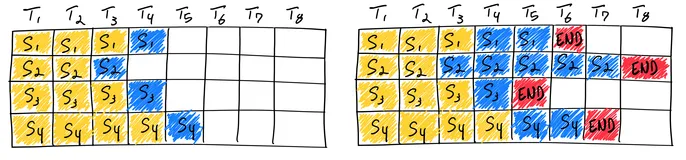
在自回归生成过程中,每次生成新的token时,都需要使用所有已生成的token重新计算注意力。KV缓存通过存储之前token的key和value表示,使得在生成新token时,只需要计算新token的query与所有token的key/value之间的注意力,从而将时间复杂度从O(n²)降低到O(n),其中n是序列长度。
标准自回归生成过程:
第1步:计算 token1 → 生成 token2
第2步:重新计算 token1, token2 → 生成 token3
第3步:重新计算 token1, token2, token3 → 生成 token4
...
使用KV缓存后的生成过程:
第1步:计算 token1 → 缓存 K1, V1 → 生成 token2
第2步:使用缓存 K1, V1 + 计算 token2 的 K2, V2 → 生成 token3
第3步:使用缓存 K1, V1, K2, V2 + 计算 token3 的 K3, V3 → 生成 token4
...
内存占用分析
KV缓存的内存占用与模型大小、批处理大小和序列长度密切相关。以一个具有h个注意力头、隐藏状态大小为d的模型为例,KV缓存的内存占用大约为:
内存占用 = 2 × 批大小 × 序列长度 × h × (d/h) × 数据类型大小
= 2 × 批大小 × 序列长度 × d × 数据类型大小
对于大型模型和长序列,KV缓存的内存占用可能达到数十GB甚至数百GB,成为内存瓶颈的主要来源。
KV缓存优化技术
1. 动态KV缓存管理
动态KV缓存管理通过智能分配和释放内存,提高内存利用率:
- 懒加载策略:仅在需要时才为新序列分配KV缓存空间
- 早期释放:对于已完成推理的序列,及时释放其KV缓存
- 优先级调度:基于请求优先级,动态调整KV缓存的分配
class DynamicKVCache:
def __init__(self, max_cache_size):
self.max_cache_size = max_cache_size
self.current_size = 0
self.cache_pool = {
}
self.priority_queue = []
def allocate(self, request_id, seq_len, priority=1):
# 计算所需空间
required_size = seq_len * self.size_per_token
# 如果空间不足,释放低优先级请求的缓存
while self.current_size + required_size > self.max_cache_size and self.cache_pool:
self._evict_low_priority()
# 分配缓存空间
self.cache_pool[request_id] = {
'keys': torch.zeros(...), # 初始化keys张量
'values': torch.zeros(...), # 初始化values张量
'current_length': 0,
'priority': priority
}
self.current_size += required_size
heapq.heappush(self.priority_queue, (priority, request_id))
def _evict_low_priority(self):
# 释放优先级最低的请求的缓存
lowest_priority = float('inf')
evict_id = None
for request_id, cache_info in self.cache_pool.items():
if cache_info['priority'] < lowest_priority:
lowest_priority = cache_info['priority']
evict_id = request_id
if evict_id:
evict_size = self.cache_pool[evict_id]['current_length'] * self.size_per_token
self.current_size -= evict_size
del self.cache_pool[evict_id]
2. 稀疏注意力与KV缓存压缩
通过稀疏注意力机制减少需要缓存的KV对数量:
- 局部注意力:只计算和缓存与当前token相邻的一定范围内的KV对
- 分块注意力:将序列分成多个块,只在块内和跨块的有限窗口内计算注意力
- Longformer等稀疏注意力变体:通过滑动窗口、全局token等机制减少计算量
3. KV量化与压缩
对KV缓存进行量化和压缩,减少内存占用:
- INT8/INT4量化:将KV缓存从FP16/FP32降至更低精度
- 知识蒸馏:训练更小的注意力头来近似原始注意力计算
- 降维技术:使用主成分分析(PCA)等技术压缩KV表示
# KV缓存量化示例
def quantize_kv_cache(keys, values, bits=8):
# 计算量化参数
key_min, key_max = keys.min(), keys.max()
value_min, value_max = values.min(), values.max()
# 量化到指定位宽
key_scale = (key_max - key_min) / (2**bits - 1)
value_scale = (value_max - value_min) / (2**bits - 1)
key_zp = -key_min / key_scale
value_zp = -value_min / value_scale
# 执行量化
keys_quant = torch.round(keys / key_scale + key_zp).to(torch.int8)
values_quant = torch.round(values / value_scale + value_zp).to(torch.int8)
return keys_quant, values_quant, key_scale, key_zp, value_scale, value_zp
def dequantize_kv_cache(keys_quant, values_quant, key_scale, key_zp, value_scale, value_zp):
# 反量化
keys = (keys_quant - key_zp) * key_scale
values = (values_quant - value_zp) * value_scale
return keys, values
4. 连续批处理(Continuous Batching)
连续批处理(也称为动态批处理或迭代级批处理)允许多个请求共享计算资源,同时优化KV缓存的使用:
- 请求调度器:根据序列长度、优先级等因素动态调度请求
- 填充与修剪:最小化填充开销,提高批处理效率
- 迭代级并行:在每个生成步骤动态调整批组成员
连续批处理可以显著提高GPU利用率,据报道可以在不增加延迟的情况下将吞吐量提高23倍2。
KV缓存的内存优化实践
1. 内存池管理
实现专用的KV缓存内存池,避免频繁的内存分配和释放:
class KVCacheMemoryPool:
def __init__(self, device, dtype=torch.float16):
self.device = device
self.dtype = dtype
self.pool = {
}
def get(self, size):
# 查找适合大小的可用缓存块
for available_size, blocks in sorted(self.pool.items()):
if available_size >= size and blocks:
return blocks.pop()
# 如果没有合适的块,分配新的
return torch.zeros(size, dtype=self.dtype, device=self.device)
def release(self, tensor):
# 将张量释放回内存池
size = tensor.numel()
if size not in self.pool:
self.pool[size] = []
self.pool[size].append(tensor)
2. 缓存分片与并行
对于分布式推理,将KV缓存分散到多个设备上:
- 张量并行:将KV缓存按注意力头维度分片
- 流水线并行:将不同层的KV缓存分布到不同设备
- 混合并行:结合多种并行策略,优化大型模型的分布式推理
3. 长上下文处理优化
针对超长上下文处理的KV缓存优化:
- 滑动窗口缓存:只保留最近的K个token的KV缓存
- 重要性采样:基于注意力权重,只缓存重要的KV对
- 层次化缓存:使用不同精度或压缩率存储不同部分的KV缓存
子图融合技术
子图融合原理
子图融合是一种通过合并多个计算操作来减少Kernel调用和内存访问的技术。在LLM推理过程中,大量的时间消耗在小算子的计算和内存读写上,子图融合通过将多个小算子合并成一个大算子,显著减少了这些开销。
基本概念
在深度学习框架中,模型通常被表示为计算图,其中节点代表操作(算子),边代表数据流。子图融合的核心思想是识别计算图中可以合并的子图,并用一个融合后的算子替代,从而减少Kernel启动和内存访问的开销。
原始计算图:
Input → LayerNorm → Linear1 → GELU → Linear2 → Output
融合后计算图:
Input → FusedLayerNormLinearGELULinear → Output
主要融合技术
1. NVIDIA FasterTransformer
NVIDIA的FasterTransformer是一个专注于Transformer模型推理加速的库,其中子图融合是其核心优化技术之一2。
主要融合模式:
- Multi-Head Attention融合:将Q、K、V的线性变换、缩放点积注意力计算、输出投影等操作融合为一个大算子
- 前馈网络融合:将两个线性变换和激活函数(如GELU)融合为一个算子
- Layer Norm融合:将Layer Normalization与前后的操作融合
- 残差连接融合:将残差连接操作与相邻操作融合
实现方式:
FasterTransformer使用CUDA C++实现了高度优化的融合算子,充分利用了GPU的并行计算能力和内存层次结构。它支持多种硬件平台,包括Ampere、Hopper等NVIDIA GPU架构。
2. Microsoft DeepSpeed Inference
Microsoft的DeepSpeed Inference提供了另一种高效的子图融合实现2。
融合策略:
DeepSpeed Inference将Transformer层分为四个主要部分进行融合:
- 输入层融合:LayerNorm + Q/K/V线性变换 + 偏置加法
- 注意力层融合:注意力计算 + 输出投影
- 中间层融合:第一个线性变换 + GELU激活
- 输出层融合:第二个线性变换 + 残差连接 + LayerNorm
性能优势:
通过这种分层融合策略,DeepSpeed Inference能够显著减少内存访问次数和Kernel启动开销,提高计算效率。
自定义融合算子开发
对于特定的模型架构和硬件平台,开发自定义融合算子可以获得更好的性能。以下是开发自定义融合算子的基本步骤:
1. 算子识别与分析
首先,需要识别模型中计算密集且频繁调用的操作序列:
- 性能分析:使用性能分析工具(如NVIDIA Nsight)识别性能瓶颈
- 算子依赖分析:分析操作之间的依赖关系,确定可以融合的子图
- 内存访问模式分析:分析数据流动模式,设计最优的数据访问策略
2. CUDA实现示例
以下是一个简化的融合算子实现示例,用于融合LayerNorm和线性变换:
__global__ void fused_layernorm_linear_kernel(
const float* input,
const float* weight,
const float* bias,
const float* gamma,
const float* beta,
float* output,
int batch_size,
int seq_len,
int hidden_size) {
// 每个线程处理一个batch中的一个token
int token_idx = blockIdx.x * blockDim.x + threadIdx.x;
if (token_idx >= batch_size * seq_len) return;
// LayerNorm计算
float mean = 0.0f;
float var = 0.0f;
for (int i = 0; i < hidden_size; ++i) {
float val = input[token_idx * hidden_size + i];
mean += val;
var += val * val;
}
mean /= hidden_size;
var /= hidden_size;
var -= mean * mean;
float rstd = rsqrtf(var + 1e-5f);
// 线性变换计算
for (int i = 0; i < hidden_size; ++i) {
float ln_val = (input[token_idx * hidden_size + i] - mean) * rstd;
ln_val = ln_val * gamma[i] + beta[i];
output[token_idx * hidden_size + i] = 0.0f;
for (int j = 0; j < hidden_size; ++j) {
output[token_idx * hidden_size + i] +=
ln_val * weight[i * hidden_size + j];
}
output[token_idx * hidden_size + i] += bias[i];
}
}
3. 自动融合框架
为了简化融合算子的开发,出现了一些自动融合框架:
- TensorRT:NVIDIA的深度学习推理优化器和运行时,支持自动算子融合
- ONNX Runtime:跨平台推理引擎,提供自动图优化和算子融合
- TVM:开源机器学习编译器框架,支持自定义算子融合策略
这些框架可以自动识别计算图中可以融合的部分,并生成优化的代码。
子图融合的性能影响
子图融合对LLM推理性能的影响主要体现在以下几个方面:
- 减少Kernel调用:合并多个算子减少了Kernel启动开销
- 降低内存带宽压力:减少了中间结果的内存读写
- 提高计算密度:增加了每个Kernel的计算量,提高了GPU利用率
- 优化数据局部性:数据可以在寄存器或共享内存中停留更长时间,减少全局内存访问
根据实际测试,子图融合可以将推理性能提高2-5倍,具体取决于模型架构和硬件平台。
模型量化技术
量化原理与类型
量化是通过降低数值表示的精度来减少模型大小和计算复杂度的技术。在LLM推理中,量化可以显著减少内存占用和计算量,提高推理速度。
基本原理
量化的基本原理是将浮点数映射到有限的整数集合,从而减少存储和计算所需的位数。量化过程通常包括以下步骤:
- 参数校准:确定量化范围(最小值和最大值)
- 量化映射:将浮点数值映射到整数值
- 反量化:在需要时将整数值转换回浮点数
主要量化类型
1. 权重量化:
只对模型权重进行量化,激活值保持浮点精度。这种方法实现简单,但效果有限。
2. 激活量化:
对输入和中间激活值进行量化,通常与权重量化结合使用。
3. 量化感知训练(QAT):
在训练过程中模拟量化效果,使模型适应量化带来的精度损失。
4. 后训练量化(PTQ):
在训练完成后对模型进行量化,无需重新训练。
量化技术详解
1. INT8量化
INT8量化是目前最成熟、应用最广泛的量化技术,将模型参数和激活值从FP32/FP16量化到INT8。
对称量化:
def quantize_symmetric(tensor, bits=8):
# 计算量化参数
scale = tensor.abs().max() / (2**(bits-1) - 1)
# 执行量化
quantized = torch.round(tensor / scale).to(torch.int8)
return quantized, scale
def dequantize_symmetric(quantized, scale):
# 反量化
return quantized.to(torch.float32) * scale
非对称量化:
def quantize_asymmetric(tensor, bits=8):
# 计算量化参数
min_val = tensor.min()
max_val = tensor.max()
scale = (max_val - min_val) / (2**bits - 1)
zero_point = -torch.round(min_val / scale)
# 确保zero_point在有效范围内
zero_point = torch.clamp(zero_point, 0, 2**bits - 1)
# 执行量化
quantized = torch.round(tensor / scale + zero_point).to(torch.uint8)
return quantized, scale, zero_point
def dequantize_asymmetric(quantized, scale, zero_point):
# 反量化
return (quantized.to(torch.float32) - zero_point) * scale
2. 低比特量化
为了进一步减少内存占用和计算量,研究人员开发了更低精度的量化技术:
INT4量化:
将参数量化到4位整数,内存占用减少到INT8的一半。由于量化范围更小,INT4量化对模型精度的影响更大,通常需要更复杂的校准和优化技术。
混合精度量化:
对模型的不同部分使用不同的量化精度。例如,对不太敏感的层使用INT4量化,对敏感层使用INT8或FP16。
def mixed_precision_quantize(model):
# 对不同层应用不同的量化策略
for name, module in model.named_modules():
if 'attention' in name:
# 注意力层使用INT8量化
quantize_module_int8(module)
elif 'ffn' in name:
# 前馈网络使用INT4量化
quantize_module_int4(module)
# 其他配置...
3. 量化感知训练
量化感知训练通过在训练过程中模拟量化效果,提高量化模型的精度:
class QuantizationAwareModule(torch.nn.Module):
def __init__(self, module, bits=8):
super().__init__()
self.module = module
self.bits = bits
self.register_buffer('weight_scale', None)
def forward(self, x):
# 模拟权重量化
weight = self.module.weight
# 计算量化参数
if self.weight_scale is None:
with torch.no_grad():
self.weight_scale = weight.abs().max() / (2**(self.bits-1) - 1)
# 模拟量化和反量化过程
quantized_weight = torch.round(weight / self.weight_scale)
quantized_weight = torch.clamp(quantized_weight,
-(2**(self.bits-1)),
2**(self.bits-1) - 1)
dequantized_weight = quantized_weight * self.weight_scale
# 使用量化后的权重进行前向传播
return F.linear(x, dequantized_weight, self.module.bias)
量化优化技术
1. 分组量化
将张量分成多个组,对每个组独立进行量化,提高量化精度:
def group_quantization(tensor, num_groups=1, bits=8):
batch_size, channels = tensor.shape[0], tensor.shape[1]
group_size = channels // num_groups
quantized = torch.zeros_like(tensor, dtype=torch.int8)
scales = torch.zeros(num_groups, dtype=torch.float32, device=tensor.device)
for i in range(num_groups):
start_idx = i * group_size
end_idx = start_idx + group_size
# 对每个组独立量化
group = tensor[:, start_idx:end_idx]
scale = group.abs().max() / (2**(bits-1) - 1)
scales[i] = scale
# 量化
quantized[:, start_idx:end_idx] = torch.round(group / scale).to(torch.int8)
return quantized, scales
2. 量化校准优化
精心选择校准数据集和校准方法,提高量化精度:
- 代表性校准集:选择能够代表推理数据分布的校准样本
- 逐层校准:对每个层独立进行校准,考虑激活值的分布差异
- 百分位校准:使用特定百分位(如99.9%)的值作为量化范围,避免异常值影响
3. 量化专用硬件加速
利用硬件的量化加速指令,提高量化模型的执行效率:
- NVIDIA Tensor Cores:支持INT8/INT4计算加速
- ARM NEON:移动设备上的SIMD指令集,支持整数运算加速
- Intel AVX-512:支持向量化整数运算
量化对LLM的影响
量化对LLM的影响主要体现在以下几个方面:
- 模型大小:INT8量化可以将模型大小减少75%(相比FP32),INT4量化可以减少87.5%
- 内存占用:减少了模型权重和激活值的内存占用
- 计算速度:在支持量化加速的硬件上,量化可以显著提高计算速度
- 模型精度:过度量化可能导致模型精度下降,需要在精度和性能之间进行权衡
批处理策略优化
批处理原理与类型
批处理是提高LLM推理吞吐量的关键技术,通过同时处理多个请求,充分利用GPU的并行计算能力。
基本原理
批处理的核心思想是将多个独立的推理请求组合成一个批次,共享计算资源,从而提高GPU利用率和吞吐量。
单请求处理:
请求1 → 计算 → 响应1
请求2 → 计算 → 响应2
...
批处理:
请求1 + 请求2 + ... → 批计算 → 响应1 + 响应2 + ...
主要批处理类型
1. 静态批处理:
在推理开始前固定批次大小,所有请求必须等待批次填满才能开始处理。
2. 动态批处理:
根据请求到达情况动态调整批次大小和组成,提高资源利用率。
3. 连续批处理(Continuous Batching):
在每个生成步骤动态调整批次成员,一个请求完成后立即将新请求加入批次。
连续批处理技术
连续批处理(也称为迭代级批处理或动态批处理)是当前最先进的批处理技术,能够显著提高LLM推理的吞吐量2。
工作原理
连续批处理的关键创新在于打破了传统批处理的限制,允许多个请求在不同时间加入和离开批次:
- 请求调度器:维护一个请求队列,根据优先级和资源需求调度请求
- 迭代级并行:在每个token生成步骤动态重组批次
- 早期退出:当一个请求完成生成时,立即将其从批次中移除,释放资源
实现示例
class ContinuousBatchingScheduler:
def __init__(self, max_batch_size, max_sequence_length):
self.max_batch_size = max_batch_size
self.max_sequence_length = max_sequence_length
self.waiting_queue = []
self.active_batch = {
}
self.request_id_counter = 0
def add_request(self, prompt, max_new_tokens):
request_id = self.request_id_counter
self.request_id_counter += 1
request = {
'id': request_id,
'prompt': prompt,
'max_new_tokens': max_new_tokens,
'generated_tokens': [],
'current_length': len(prompt),
'status': 'waiting'
}
self.waiting_queue.append(request)
return request_id
def schedule_next_batch(self):
# 尝试将等待队列中的请求加入活跃批次
while self.waiting_queue and len(self.active_batch) < self.max_batch_size:
request = self.waiting_queue.pop(0)
# 检查是否有足够的资源
if request['current_length'] + request['max_new_tokens'] <= self.max_sequence_length:
request['status'] = 'active'
self.active_batch[request['id']] = request
def process_step(self):
# 处理当前活跃批次的一个生成步骤
if not self.active_batch:
return [], False
# 准备输入(这里简化处理)
inputs = [req['prompt'] + req['generated_tokens'] for req in self.active_batch.values()]
# 执行模型前向传播,生成下一个token(这里简化处理)
new_tokens = generate_next_tokens(inputs)
# 更新请求状态
completed_requests = []
for i, (req_id, request) in enumerate(self.active_batch.items()):
request['generated_tokens'].append(new_tokens[i])
request['current_length'] += 1
# 检查是否完成
if (len(request['generated_tokens']) >= request['max_new_tokens'] or
new_tokens[i] == EOS_TOKEN):
request['status'] = 'completed'
completed_requests.append(req_id)
# 移除已完成的请求
for req_id in completed_requests:
del self.active_batch[req_id]
# 尝试添加新请求
self.schedule_next_batch()
return completed_requests, len(self.active_batch) > 0
批处理优化策略
1. 请求调度优化
智能调度策略可以提高批处理效率:
- 优先级调度:为不同类型的请求分配不同优先级
- 长度感知调度:根据序列长度进行分组,避免长短序列混合导致的资源浪费
- 预测性调度:基于历史数据预测请求的资源需求和完成时间
2. 内存优化
批处理会增加内存需求,需要相应的优化策略:
- 内存共享:多个请求共享只读的模型权重
- 动态内存分配:根据批处理大小动态调整内存分配
- 梯度累积优化:在不支持动态内存分配的框架中,使用梯度累积技术
3. 填充与修剪优化
批处理中不同长度的序列需要填充到相同长度,这会带来额外的计算开销:
- 自适应分组:将相似长度的序列分到同一批次
- 梯度掩码:在计算时忽略填充token的影响
- 变长批处理:在可能的情况下使用变长批处理,避免填充
批处理的性能影响
批处理对LLM推理性能的影响主要体现在以下几个方面:
- 吞吐量提升:通过并行处理多个请求,显著提高吞吐量
- 延迟权衡:批处理可能会增加单个请求的延迟,需要在吞吐量和延迟之间进行权衡
- 资源利用率:提高GPU等计算资源的利用率
- 内存需求增加:需要更多的内存来存储批次数据和中间结果
根据实际测试,连续批处理可以在保持延迟不变的情况下,将吞吐量提高20倍以上,是目前最有效的批处理技术。
分布式推理技术
分布式推理架构
对于超大规模LLM,单个设备无法容纳整个模型,需要采用分布式推理技术,将模型分散到多个设备甚至多个节点上。
并行策略
1. 张量并行(Tensor Parallelism):
将模型的张量(如权重矩阵)分割到多个设备上,每个设备处理一部分计算。
实现方式:
- 输入并行:分割输入张量
- 权重并行:分割权重矩阵
- 输出并行:分割输出张量
适用场景:适用于单一层的权重超过单个设备内存的情况。
2. 流水线并行(Pipeline Parallelism):
将模型的不同层分配到不同设备上,数据按照层顺序在设备间流动。
实现方式:
- 简单流水线:每层分配到一个设备
- 分段流水线:多层分配到一个设备
适用场景:适用于模型层数很多,但单一层可以放入单个设备的情况。
3. 序列并行(Sequence Parallelism):
将序列维度分割到多个设备上,减少每个设备的内存需求。
实现方式:
- 按序列长度分割输入
- 在不同设备上并行计算不同部分的序列
适用场景:适用于处理超长序列的情况。
4. 混合并行:
结合多种并行策略,充分利用硬件资源。
混合并行架构示例:
节点1 节点2
+-------+ +-------+
| 层1-10 |<-------->| 层11-20|
| TP=4 | | TP=4 |
+-------+ +-------+
分布式推理框架
1. NVIDIA FasterTransformer
FasterTransformer支持多种分布式推理策略,包括张量并行和流水线并行2。
主要特点:
- 支持多达1024路张量并行
- 支持流水线并行
- 高度优化的通信原语
- 支持多种模型架构(GPT、BERT等)
配置示例:
# FasterTransformer分布式配置
def setup_distributed_model(model_name, tensor_parallel_size, pipeline_parallel_size):
# 初始化分布式环境
init_distributed_environment()
# 加载模型配置
config = get_model_config(model_name)
# 设置并行参数
config.tensor_parallel_size = tensor_parallel_size
config.pipeline_parallel_size = pipeline_parallel_size
# 创建分布式模型
model = FasterTransformerModel(config)
# 加载权重
load_model_weights(model, model_name)
return model
2. Microsoft DeepSpeed
DeepSpeed提供了全面的分布式训练和推理解决方案,包括零冗余优化器(ZeRO)等技术。
主要特点:
- ZeRO-Inference:减少推理过程中的内存占用
- 支持多种并行策略
- 高效的通信优化
- 与PyTorch生态系统集成
3. Megatron-LM
Megatron-LM是NVIDIA开发的大规模语言模型训练和推理框架,专为超大规模模型设计。
主要特点:
- 支持万亿参数规模的模型推理
- 优化的分布式通信
- 与FasterTransformer集成
- 支持模型并行和流水线并行
通信优化
分布式推理中的通信开销是性能瓶颈之一,需要专门的优化技术:
1. 通信压缩
减少节点间传输的数据量:
- 梯度压缩:使用稀疏化、量化等技术压缩通信数据
- 异步通信:重叠计算和通信,隐藏通信延迟
- 通信融合:合并多个小型通信操作,减少通信次数
2. 拓扑感知调度
根据集群拓扑优化通信路径:
- 就近原则:优先在物理距离近的节点间通信
- 异构网络优化:充分利用高速网络(如InfiniBand)
- 通信优先级:为关键路径的通信设置高优先级
3. 模型并行优化
针对特定并行策略的优化:
- 张量并行优化:使用NCCL等高效通信库
- 流水线并行优化:使用微批次和通信-计算重叠
- 序列并行优化:优化跨序列的通信模式
分布式推理的挑战与解决方案
1. 负载不均衡
问题:不同设备的计算负载不均衡,导致整体性能下降。
解决方案:
- 动态负载均衡:实时监控各设备负载,动态调整任务分配
- 分层优化:针对不同层的计算复杂度,合理分配设备资源
- 预测性调度:基于历史数据预测负载,提前调整
2. 通信开销
问题:节点间频繁通信导致性能下降。
解决方案:
- 通信压缩:减少通信数据量
- 通信合并:合并多个通信操作
- 异步通信:重叠计算和通信
3. 容错性
问题:分布式环境中单点故障可能导致整个推理过程失败。
解决方案:
- 检查点机制:定期保存中间状态
- 故障检测与恢复:快速检测故障并恢复
- 冗余计算:关键路径上使用冗余计算确保可靠性
新兴优化技术
稀疏激活与注意力优化
稀疏激活和注意力优化通过减少计算和内存访问的数量,提高LLM推理效率。
1. 条件计算
根据输入动态激活部分网络:
- MoE(Mixture of Experts):使用路由器选择部分专家网络进行计算
- 稀疏激活:只激活对当前输入重要的神经元
- 动态计算路径:根据输入复杂度动态调整计算深度
2. 高效注意力机制
优化注意力计算,减少计算量和内存占用:
- 线性注意力:将注意力计算复杂度从O(n²)降低到O(n)
- 局部注意力:只计算局部窗口内的注意力
- Flash Attention:利用GPU内存层次结构优化注意力计算
# 线性注意力实现示例
def linear_attention(q, k, v):
# 计算线性注意力
q = F.elu(q) + 1
k = F.elu(k) + 1
# 计算上下文向量
context = torch.matmul(k.transpose(-2, -1), v)
# 计算注意力输出
attn = torch.matmul(q, context)
return attn
编译优化与自动代码生成
编译优化通过静态分析和代码转换,生成更高效的执行代码。
1. 算子融合与优化
自动识别和优化计算图中的算子:
- TVM:开源机器学习编译器,支持自动代码优化
- TensorRT:NVIDIA的深度学习推理优化器
- ONNX Runtime:跨平台推理引擎,支持自动优化
2. 静态分析与优化
通过静态分析识别优化机会:
- 常量折叠:在编译时计算常量表达式
- 死代码消除:移除不会被执行的代码
- 内存访问优化:重新排序内存访问,提高缓存命中率
硬件感知优化
针对特定硬件平台的优化,可以充分发挥硬件性能。
1. GPU优化技术
充分利用GPU架构特性:
- Tensor Core利用:使用Tensor Core加速矩阵运算
- 内存层次优化:合理利用寄存器、共享内存和全局内存
- 线程块调度:优化线程块大小和网格维度
2. 专用加速器优化
针对AI专用加速器的优化:
- TPU优化:针对Google TPU架构的优化
- ASIC优化:针对专用集成电路的优化
- FPGA优化:使用FPGA实现自定义加速逻辑
未来发展方向
LLM推理优化技术正在快速发展,以下是一些未来的发展方向:
- 硬件-软件协同设计:针对LLM特性设计专用硬件和优化软件栈
- 自适应优化:根据输入特性和系统状态动态调整优化策略
- 端到端优化:从模型设计到部署的全流程优化
- 绿色计算:降低推理能耗,实现可持续发展
性能评估与基准测试
评估指标
评估LLM推理性能的关键指标包括:
1. 延迟指标
- P50延迟:50%请求的响应时间
- P90延迟:90%请求的响应时间
- P99延迟:99%请求的响应时间
- 首token延迟:生成第一个token的时间
- token生成速率:每秒生成的token数量(tokens/s)
2. 吞吐量指标
- 请求吞吐量:每秒处理的请求数量(requests/s)
- token吞吐量:每秒处理的token总数(tokens/s)
3. 资源利用率指标
- GPU利用率:GPU计算单元的使用率
- 内存带宽利用率:内存带宽的使用情况
- 功耗效率:每瓦功耗处理的token数量(tokens/W)
4. 质量指标
- 困惑度:衡量生成文本的质量
- BLEU/ROUGE:评估生成文本与参考文本的相似度
- 人工评价分数:人工评估生成结果的质量
基准测试方法
1. 标准测试集
使用标准测试集进行性能评估:
- LAMBADA:评估长文本理解能力
- GLUE:通用语言理解评估基准
- MMLU:大规模多任务语言理解基准
- 自定义测试集:针对特定应用场景设计的测试集
2. 测试环境设置
标准化的测试环境对于公平比较至关重要:
- 硬件配置:详细记录CPU、GPU、内存等硬件配置
- 软件环境:操作系统、CUDA版本、深度学习框架版本等
- 测试参数:批大小、序列长度、精度设置等
3. 性能分析工具
使用专业工具进行性能分析:
- NVIDIA Nsight Systems:GPU性能分析工具
- PyTorch Profiler:PyTorch内置的性能分析工具
- TensorBoard Profiler:可视化性能分析工具
实际优化案例
案例一:GPT-3 175B模型优化
优化前:
- 单GPU推理延迟:> 10秒/请求
- 内存占用:> 350GB
- 吞吐量:< 1 request/s
优化后(使用张量并行+流水线并行+KV缓存优化):
- 分布式推理延迟:< 1秒/请求
- 内存占用:每个GPU < 50GB
- 吞吐量:> 10 requests/s
案例二:BERT-large模型优化
优化前:
- 批大小:32
- 延迟:12ms/样本
- 吞吐量:2667 samples/s
优化后(使用INT8量化+子图融合):
- 批大小:128
- 延迟:4ms/样本
- 吞吐量:32000 samples/s
最佳实践与建议
推理优化的系统方法
优化LLM推理性能需要系统的方法,从多个层面进行优化:
1. 模型层面
- 模型剪枝:移除不重要的权重和神经元
- 知识蒸馏:训练更小的模型模拟大模型的行为
- 架构优化:设计更高效的模型架构,如FlashAttention、ALiBi等
2. 算法层面
- 量化:降低数值表示精度,减少内存占用和计算量
- KV缓存优化:减少注意力计算的重复工作
- 稀疏计算:只计算必要的部分,减少计算量
3. 系统层面
- 子图融合:合并多个算子,减少Kernel调用和内存访问
- 批处理优化:通过并行处理提高吞吐量
- 分布式推理:将模型分散到多个设备上
4. 部署层面
- 硬件选择:根据需求选择合适的硬件平台
- 软件栈优化:选择高效的深度学习框架和运行时
- 监控与调优:持续监控和优化系统性能
常见优化误区
在LLM推理优化过程中,需要避免以下常见误区:
1. 过度优化
问题:过度优化可能导致模型精度显著下降,或者增加系统复杂性。
解决方案:
- 设定明确的性能目标和精度要求
- 进行全面的性能-精度权衡分析
- 优先应用成熟、稳定的优化技术
2. 忽视实际应用场景
问题:优化策略没有考虑实际应用的特性和需求。
解决方案:
- 深入了解目标应用的性能瓶颈和需求
- 设计针对性的优化策略
- 在真实环境中进行测试和验证
3. 过早优化
问题:在系统设计早期就进行优化,可能导致设计受限。
解决方案:
- 先确保系统功能正确性和可维护性
- 使用性能分析工具识别真正的瓶颈
- 针对性地应用优化技术
4. 忽视可维护性
问题:过度优化导致代码难以理解和维护。
解决方案:
- 保持代码的清晰性和可读性
- 添加详细的注释和文档
- 模块化设计,便于维护和扩展
未来优化建议
随着LLM技术的不断发展,推理优化也需要持续演进:
1. 关注硬件发展
密切关注AI硬件的发展,及时利用新硬件的特性:
- 新型GPU架构:如NVIDIA Hopper、AMD CDNA等
- 专用AI加速器:如TPU、ASIC等
- 内存技术进步:如HBM、CXL等
2. 跟踪研究前沿
关注学术研究和工业界的最新进展:
- 新型注意力机制:如FlashAttention-2、Linear Attention等
- 高效架构设计:如MoE、GQA等
- 压缩技术:如稀疏化、结构化剪枝等
3. 建立优化流程
建立系统化的优化流程和最佳实践:
- 性能基准测试:建立标准的性能测试流程
- 自动化调优:使用自动化工具寻找最佳配置
- 持续监控:实时监控系统性能,及时发现问题
结论
LLM推理优化是一个复杂而重要的领域,需要综合应用多种技术和方法。本文详细介绍了KV缓存优化、子图融合、模型量化、批处理策略和分布式推理等核心技术,分析了它们的原理、实现方法和性能影响。
随着大模型在各个领域的广泛应用,推理优化技术将继续快速发展。未来,硬件-软件协同设计、自适应优化、端到端优化等方向将成为研究热点。同时,绿色计算和可持续发展也将成为推理优化的重要考虑因素。
对于开发者和研究人员来说,理解和掌握LLM推理优化技术不仅可以提高系统性能,降低运行成本,还可以推动AI技术的更广泛应用。通过持续学习和实践,我们可以不断提升推理优化的能力,为构建高效、可靠的AI系统贡献力量。