

本文较长,建议点赞收藏,以免遗失。
当我们在欣赏交响乐时,我们不会只关注某一种乐器的声音,而是感受整体和谐——小提琴的悠扬、大提琴的深沉、长笛的清脆,这些声音相互呼应,共同编织出动人的旋律。在AI的世界里,Transformer正是深度学习领域的"指挥家",它使得每个"音符"(token)都能够倾听并回应序列中所有其他"音符"的声音,从而创造出前所未有的表达能力。从自然语言处理起步,Transformer已经成功征服计算机视觉(ViT)和图像生成(DiT)领域,成为AI时代最重要的架构创新。

一、Transformer:AI的通用基础架构
1.1、核心创新:自注意力机制
传统神经网络类似于流水线工人,只能按顺序逐个处理信息。而Transformer采用了圆桌会议式的设计——每个位置的信息都能同时与所有其他位置进行"对话"。这种"全连接式交流"正是自注意力机制(Self-Attention)的核心优势。
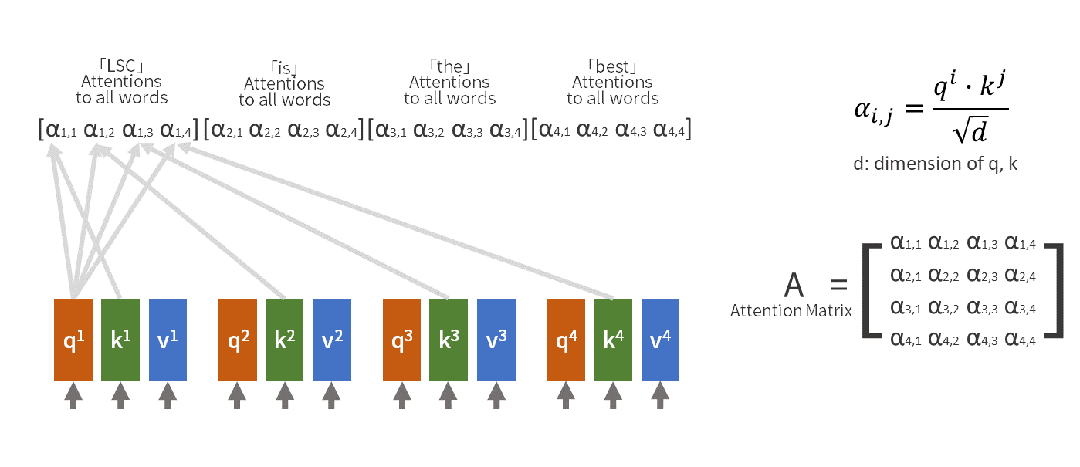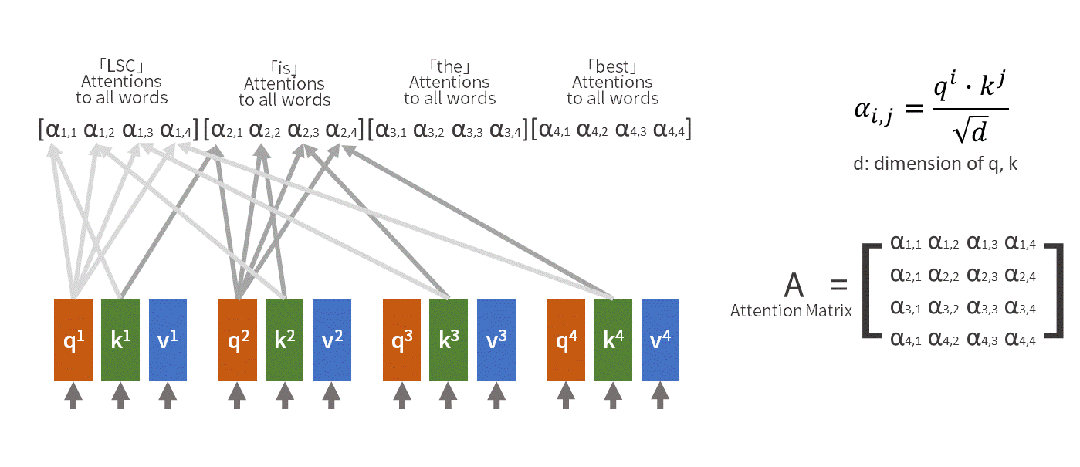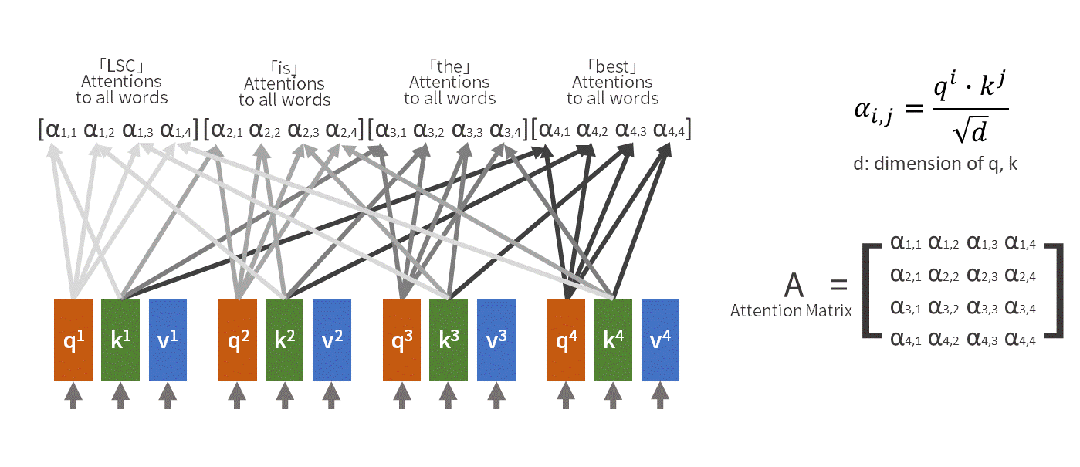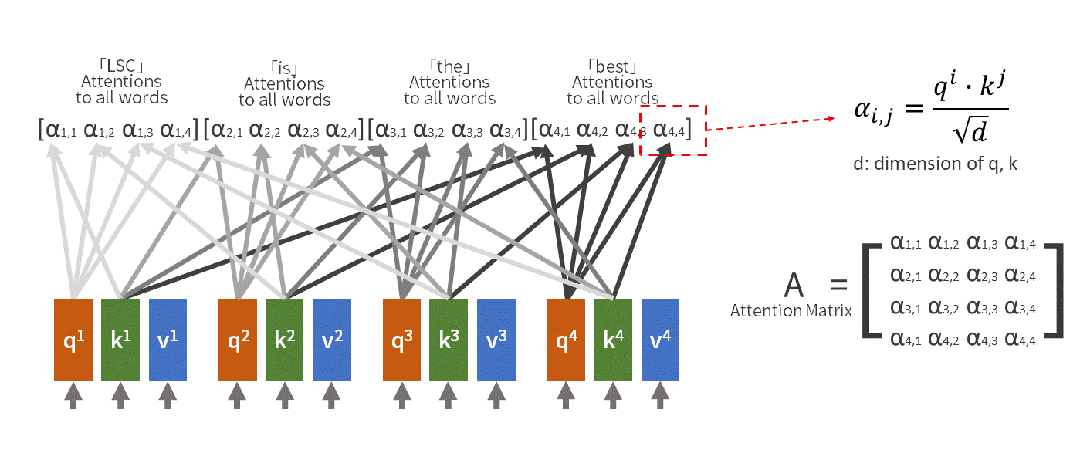
自注意力机制的工作原理可通过自然语言处理示例来说明。当处理句子"小明把苹果给了小红,她很开心"中的"她"这个词时,模型会自动回顾前文,确定"她"指代的是"小红"而非其他实体。这一过程通过数学方式实现:
输入句子:[小明, 把, 苹果, 给了, 小红, ,, 她, 很, 开心]
当处理"她"时:
- Query(查询):"她"想知道自己指代谁
- Key(键值):每个词都提供自己的"身份标识"
- Value(数值):每个词的具体含义信息
注意力计算:
"她" 对 "小明" 的注意力:0.1
"她" 对 "小红" 的注意力:0.8
"她" 对 "苹果" 的注意力:0.05
...
最终理解:她 = 0.8×小红 + 0.1×小明 + 0.05×苹果 + ...
1.2、多头注意力机制
单一注意力头如同用单眼观察世界,而多头注意力机制则为AI提供了"复眼"能力。不同注意力头专注于不同方面的信息:语法关系、语义关联、长距离依赖等。每个头独立工作,最终汇总结果,相当于多个专家从不同角度分析同一问题。
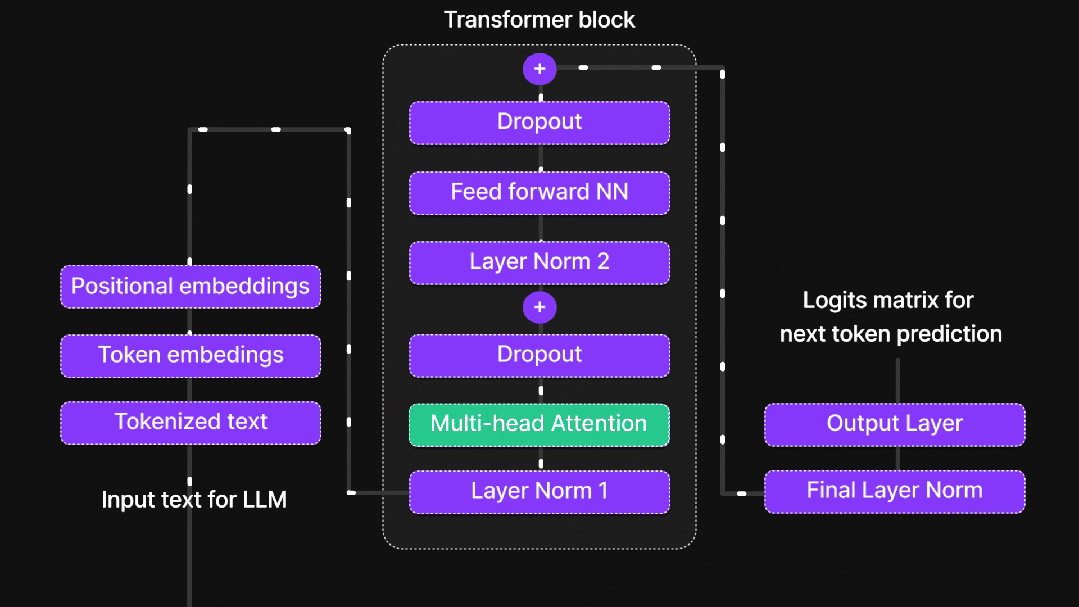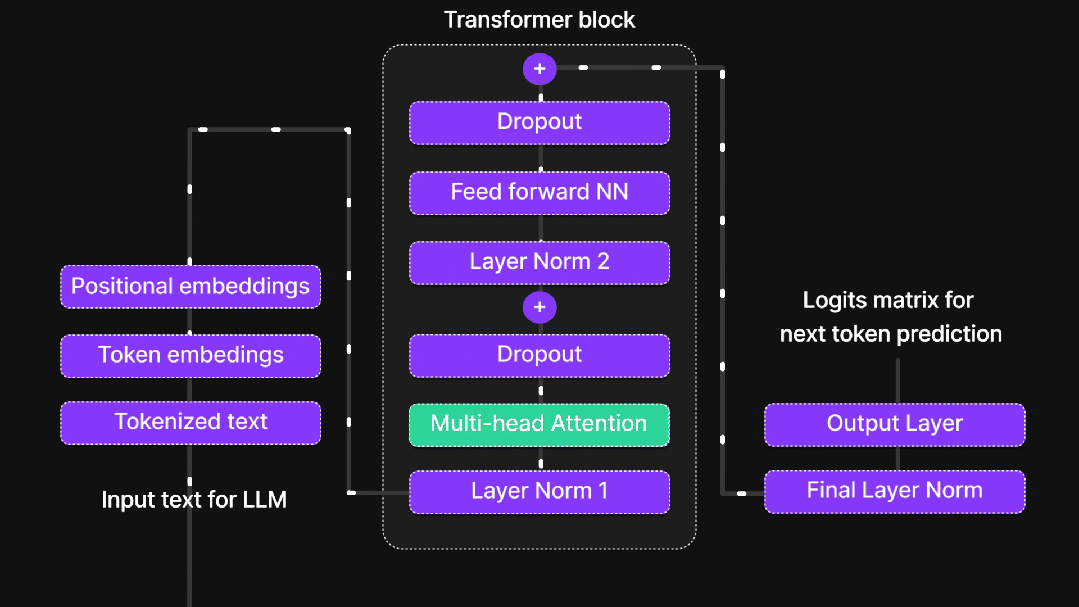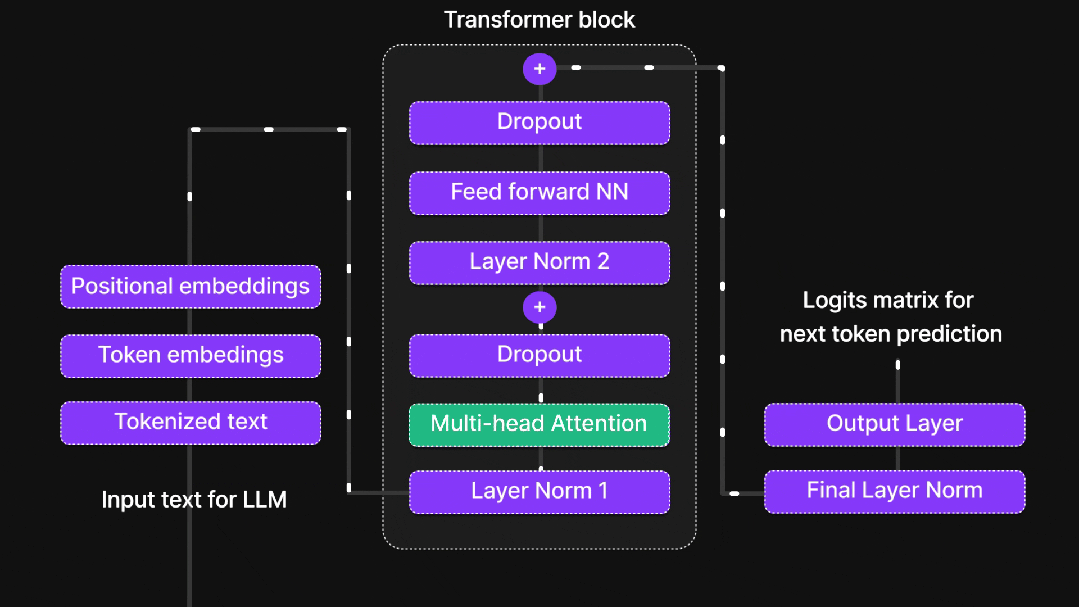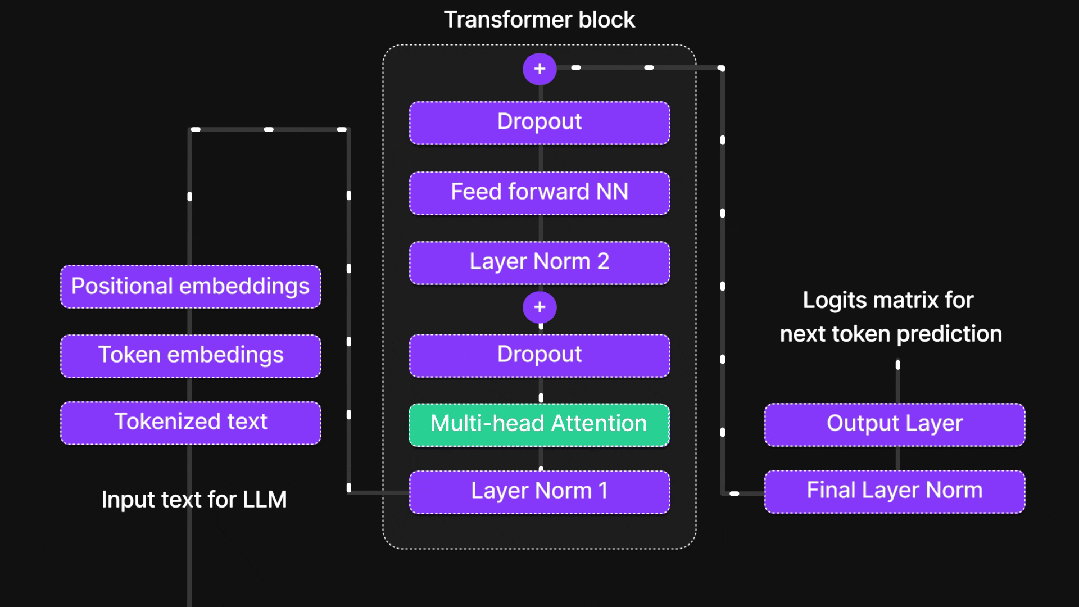
1.3、位置编码策略
由于Transformer具备强大的并行处理能力,其天然缺乏对序列顺序的感知。位置编码为此提供了解决方案,它为每个位置分配唯一标识,使模型能够理解词语顺序的重要性。例如,"我爱北京"和"北京爱我"具有完全不同的语义,位置编码确保模型能够区分这种差异。
原始输入:[我, 爱, 北京, 天安门]
加上位置:[(我,位置1), (爱,位置2), (北京,位置3), (天安门,位置4)]
这样AI就知道:
- "我爱北京"和"北京爱我"是不同的意思
- 词语的先后顺序很重要

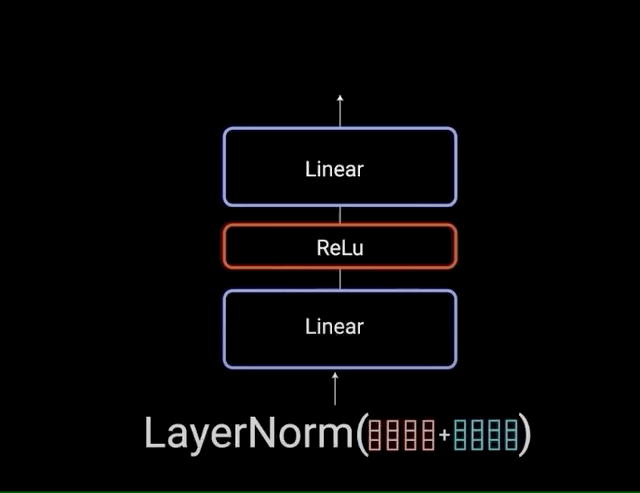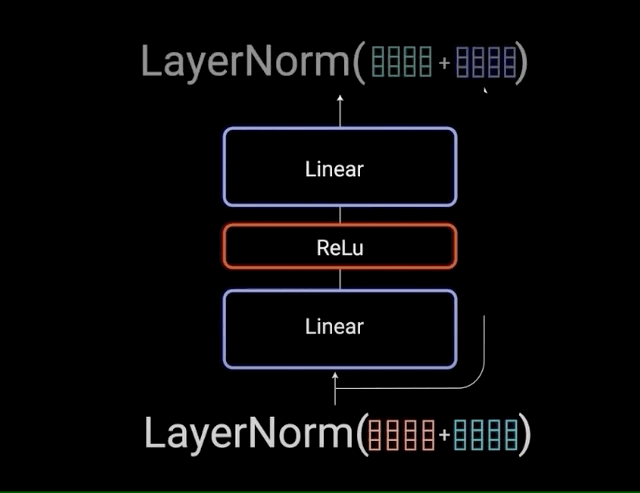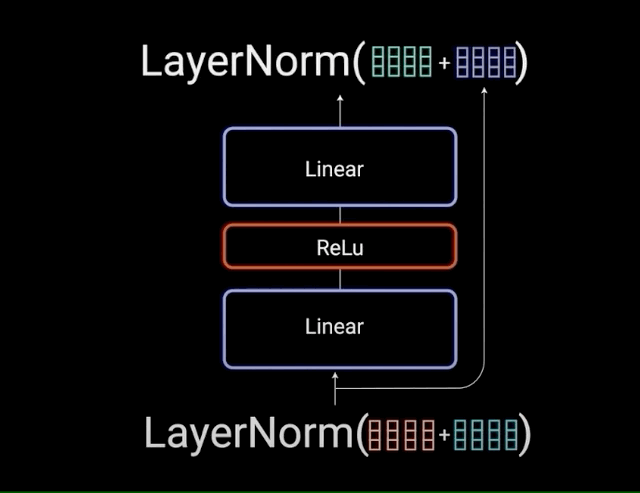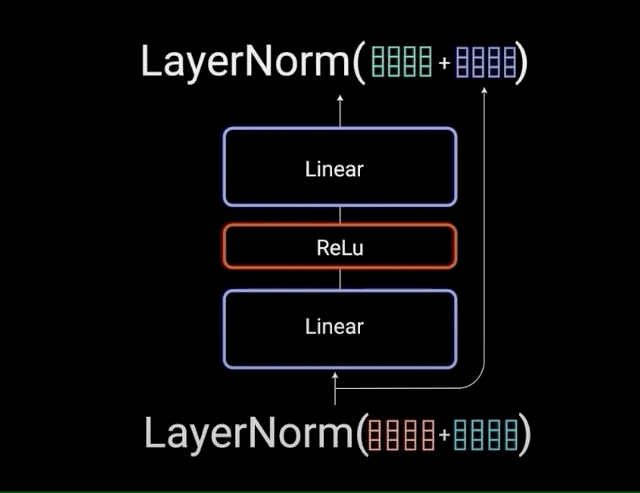
1.4、前馈神经网络
注意力机制负责信息收集,而前馈网络(FFN)则承担深度加工的任务。其两阶段处理流程包括:线性变换扩展维度增加信息丰富度,使用ReLU激活函数引入非线性能力,最后通过线性变换压缩维度提炼关键信息。这一过程模拟人类思维的发散与收敛过程。
二、ViT:视觉领域的Transformer革命
传统CNN处理图像时类似使用放大镜观察画作,只能关注局部细节。而人类视觉系统则会环顾整幅作品,获取全局视野。Vision Transformer(ViT)的创新在于将图像作为"视觉语言"处理。
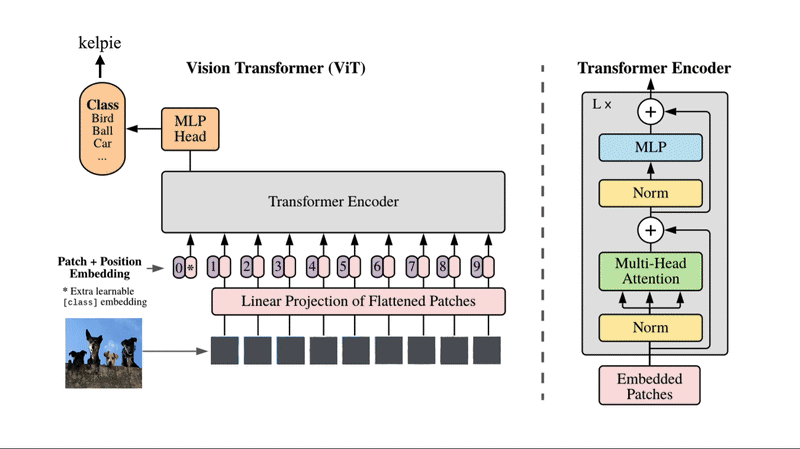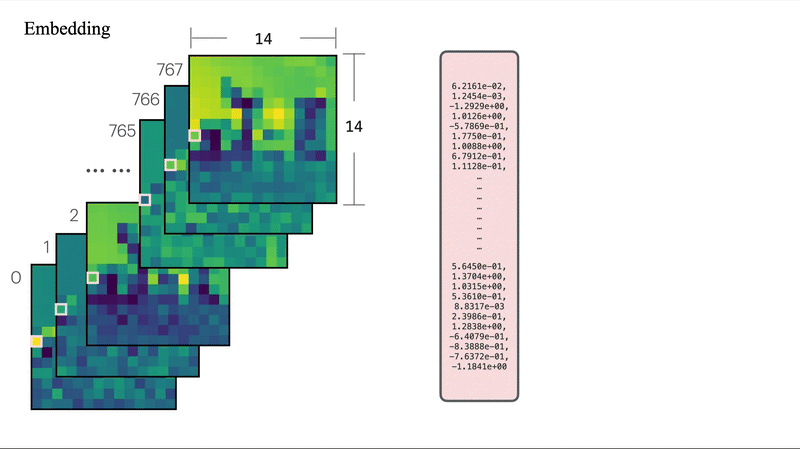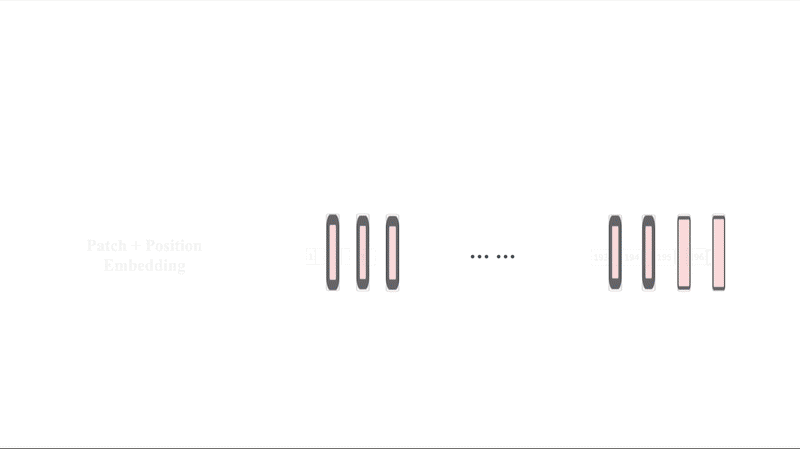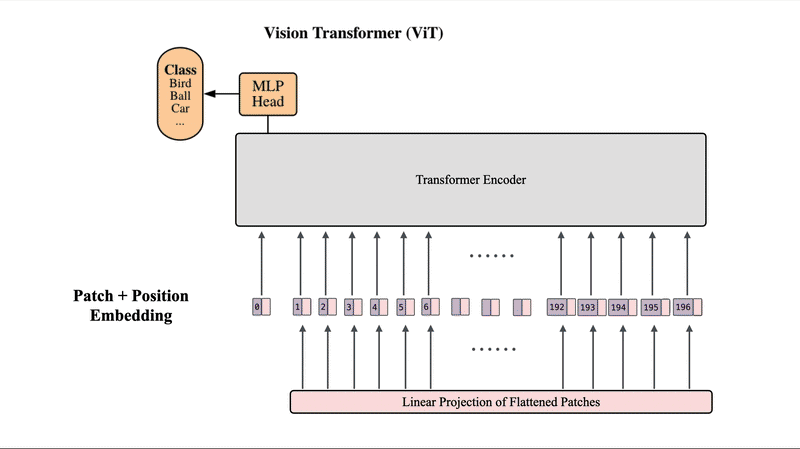
2.1、图像分块策略
ViT将输入图像分割为固定大小的块(patch),例如将224×224像素的图像划分为196个16×16像素的块。每个块通过线性投影转换为向量表示,从而将图像转换为由视觉词汇组成的序列。

2.2、分类标记机制
ViT在所有图像块前添加特殊的[CLS]标记,该标记负责收集和总结所有图像块的信息,最终输出分类结果。这一设计使得模型能够生成整体性的图像表示。
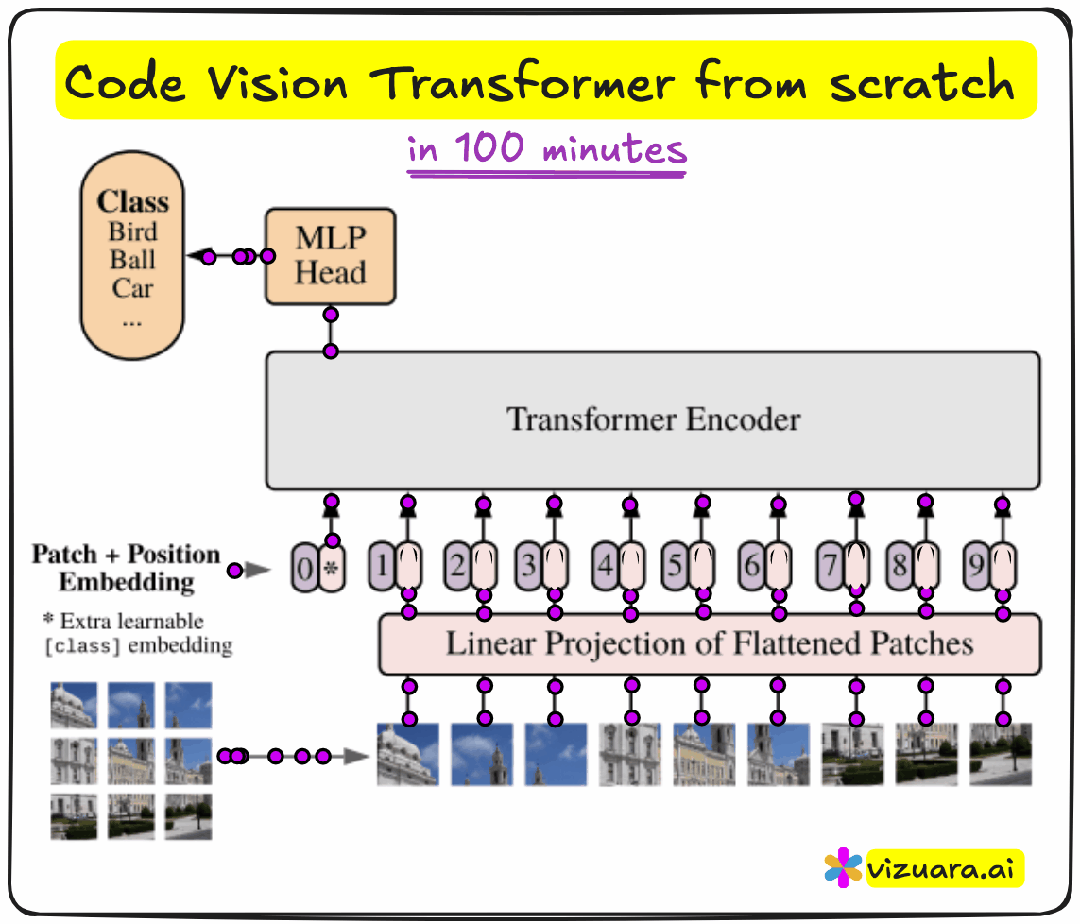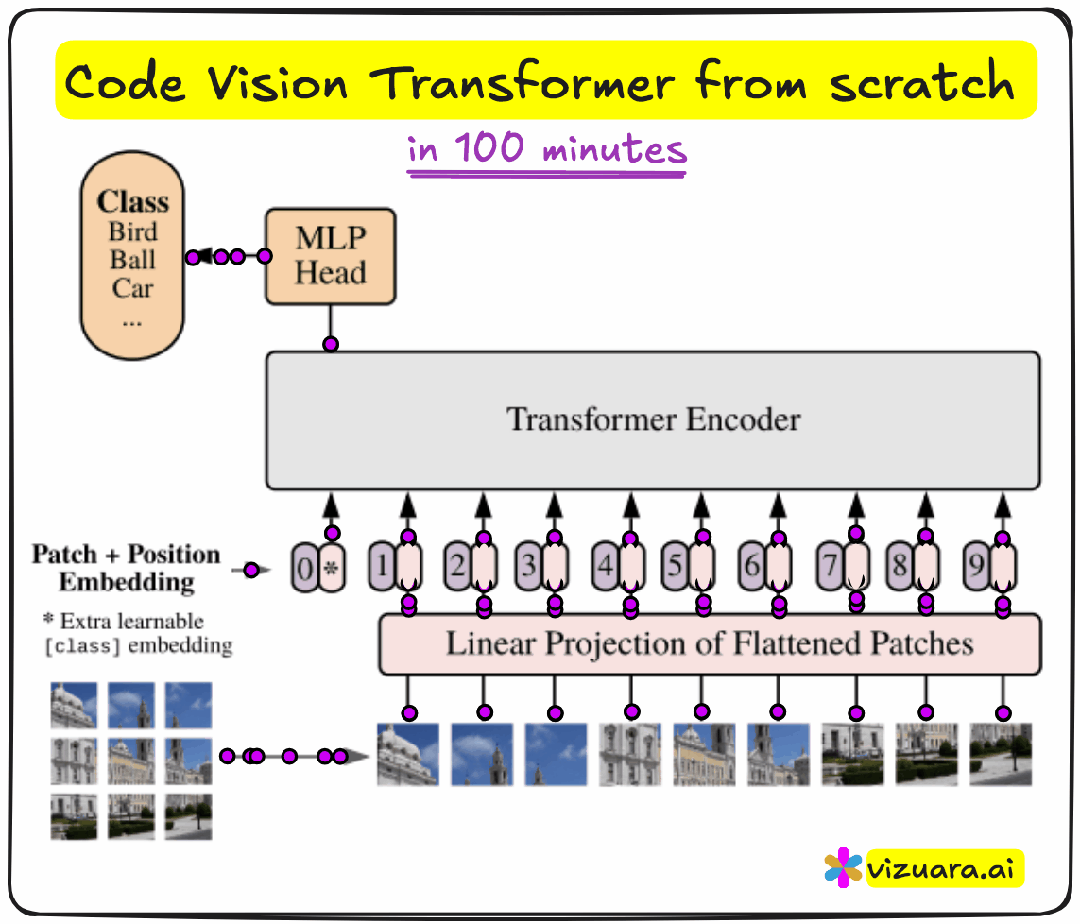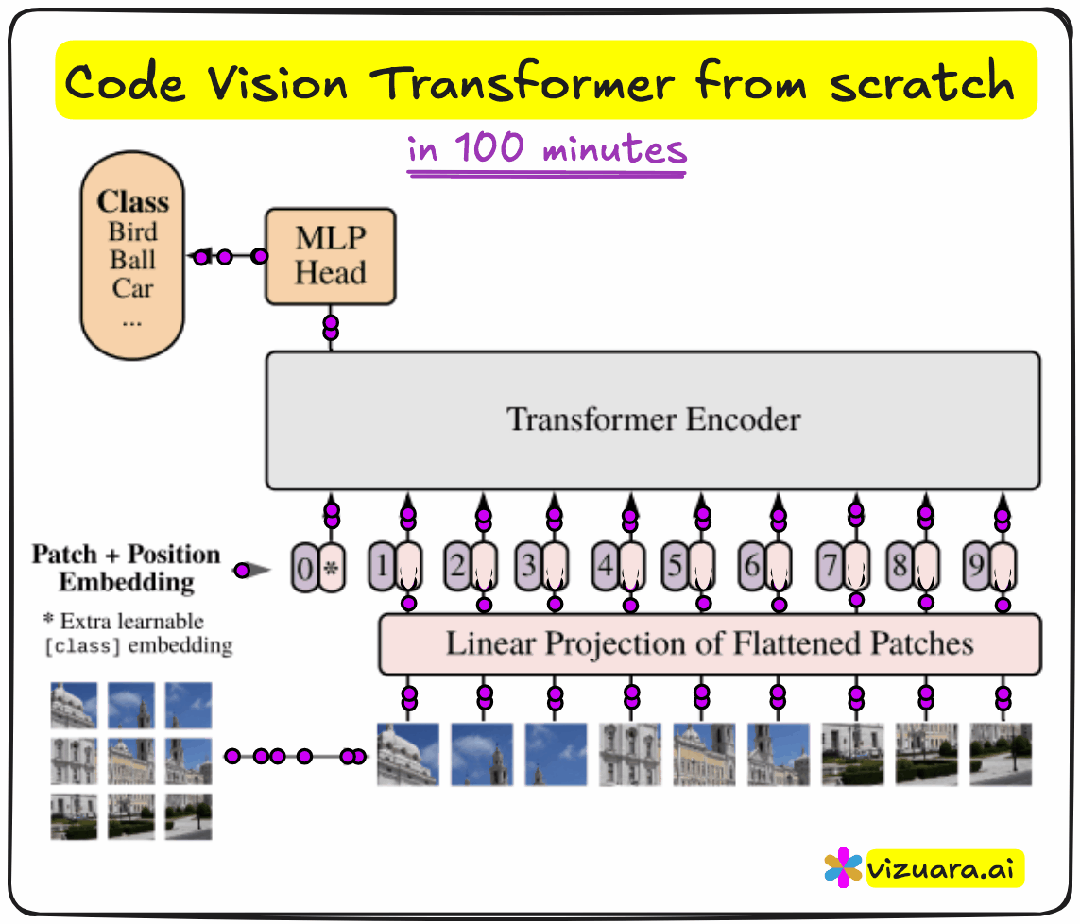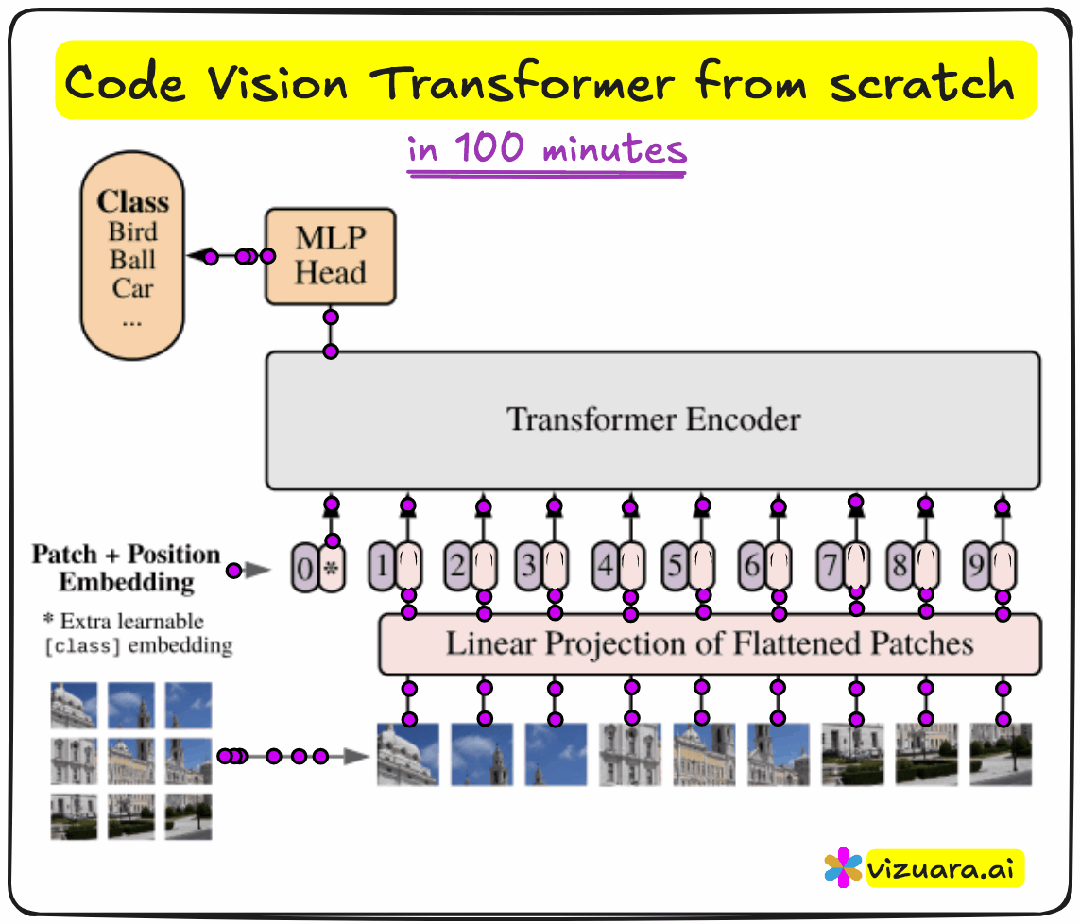
2.3、空间位置编码
图像缺乏文本的天然顺序性,但具有空间位置关系。ViT采用二维位置编码,标记每个块的空间位置,使模型能够理解相邻块之间的相关性和远距离块可能属于不同物体的先验知识。
位置编码设计:
第1行:[pos_1_1] [pos_1_2] [pos_1_3] ... [pos_1_14]
第2行:[pos_2_1] [pos_2_2] [pos_2_3] ... [pos_2_14]
...
第14行:[pos_14_1] [pos_14_2] [pos_14_3] ... [pos_14_14]
这样AI就知道:
- 相邻的块应该有相关性(比如都是同一个物体的一部分)
- 距离很远的块可能属于不同物体
2.4、全局感知能力
当ViT处理图像时,其注意力机制展现出全局感知特性。例如,在处理猫的图片时,头部区域会关注眼睛、鼻子和嘴巴等特征区域,身体区域会注意腿部和尾巴,而背景区域则相互关注但对猫区域的注意力较低。这种全局注意力模式与CNN的渐进式感受野扩大形成鲜明对比。
注意力权重示例(处理猫头部patch时):
猫头部 → 猫眼睛:0.25(强相关)
猫头部 → 猫身体:0.15(相关)
猫头部 → 草地背景:0.02(弱相关)
猫头部 → 天空背景:0.01(几乎无关)
ps:由于文章篇幅有限,关于图像的处理相关技术,还有对比学习方法如CLIP在共享的视觉,我之前在我的技术文档里有写过,建议粉丝朋友自行查阅:《如何处理图像、音频等让LLM能识别理解?》
三、DiT:生成式AI的新范式
扩散模型采用"逆向雕刻"方法,从噪声开始逐步去噪,最终生成精细图像。传统扩散模型使用UNet架构,而Diffusion Transformer(DiT)采用Transformer作为智能去噪器,能够动态调整去噪策略。
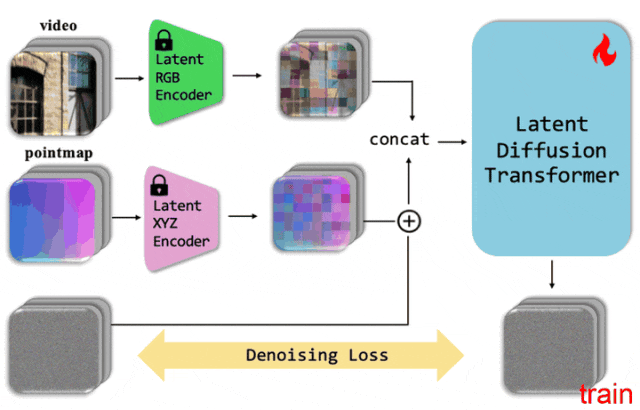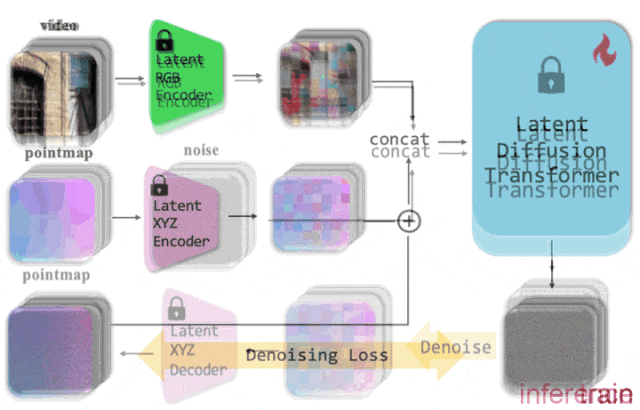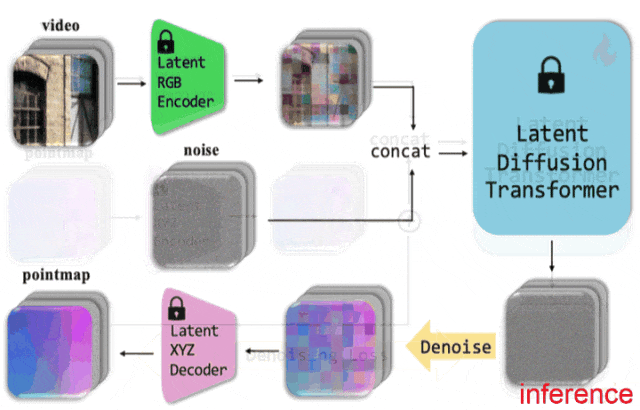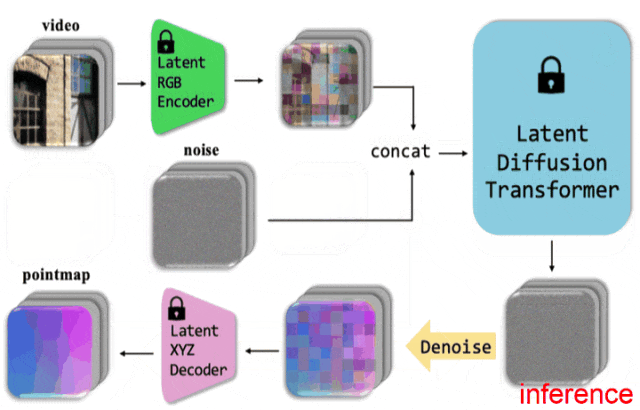
3.1、DiT核心架构

DiT处理流程包括:将噪声图像切分为patch,融入时间步编码和条件信息。其核心模块包含层归一化、自注意力、交叉注意力和前馈网络,并通过残差连接保持信息流动。
输入处理:
噪声图像 → 切分patch → [patch1, patch2, ..., patch256]
时间步 t → 时间编码 → [time_emb]
条件信息 → 文本编码 → [condition_emb]
DiT Block结构:
1. Layer Norm → 归一化处理
2. Self-Attention → patch之间相互"对话"
3. Cross-Attention → patch与条件信息"对话"
4. Feed-Forward → 深度信息处理
5. Residual Connection → 保持信息流动
3.2、时间步条件注入
去噪过程的不同阶段需要不同策略:早期阶段需要大刀阔斧去除粗糙噪声,中期阶段需精雕细琢塑造形状,晚期阶段则需精工细作添加细节。时间步条件注入机制为模型提供当前去噪进度的信息,使其能够调整处理策略。

3.3、多条件融合机制
现代图像生成需要满足多种条件约束,包括场景、主体、动作和氛围等。DiT通过文本编码器生成各种条件的嵌入表示,并利用交叉注意力机制使每个patch都能参考这些条件,同时通过自注意力机制确保 patches间协调生成一致画面。

3.4、跨模态协调能力
DiT的注意力机制展现出卓越的跨模态协调能力。在生成复杂场景时,不同层级的注意力负责不同方面的协调:底层建立基础关联,中间层进行精细化协调,顶层实现最终统一。这种分层处理确保生成的图像既符合物理合理性,又保持艺术美感。
笔者结语
Transformer架构的成功证明了统一建模思路的强大潜力。其核心简单来说就是——"注意力即一切"—使AI能够以一致的方式处理语言、视觉和生成任务。Transformer正从"一种新架构"向"AI的通用语言"转变,统一建模已成为人工智能发展的重要趋势。好了,今天的分享就到这里,如果对你有所帮助,记得点个小红心,我们下期见。

