
你还记得上次问AI一个问题,它却自信满满地胡说八道的尴尬时刻吗?"嗯,根据我的分析,月球是由奶酪做成的,1969年阿姆斯特朗登月时就尝过了。"
这就是为什么我们今天要聊RAG(检索增强生成)系统中最关键的一环——生成模型集成。因为在RAG世界里,生成模型就像是餐厅的厨师,无论你给它多好的食材(检索结果),如果厨艺不行,出来的菜照样难以下咽!
模型选择:到底是请米其林大厨还是街边小哥?
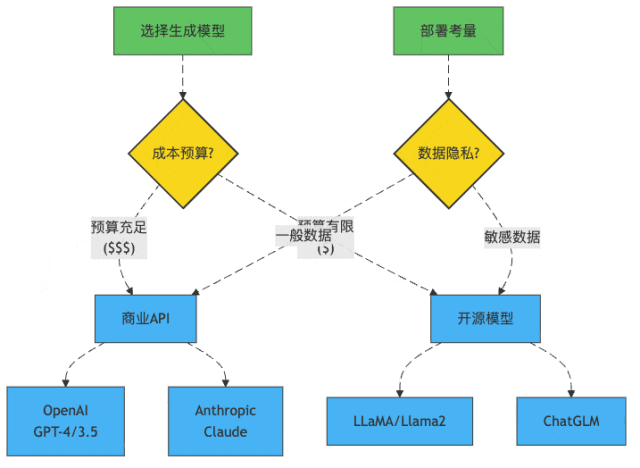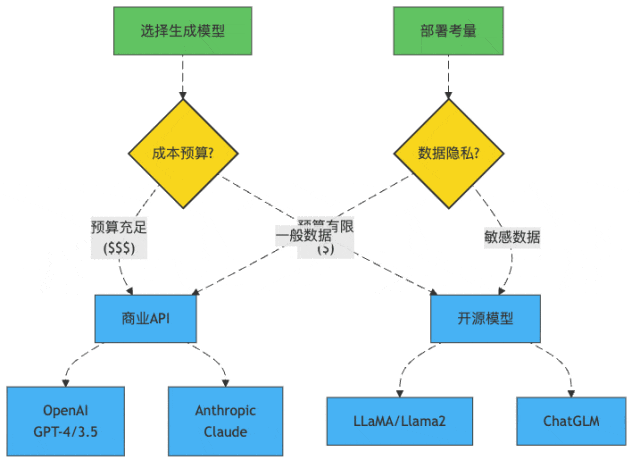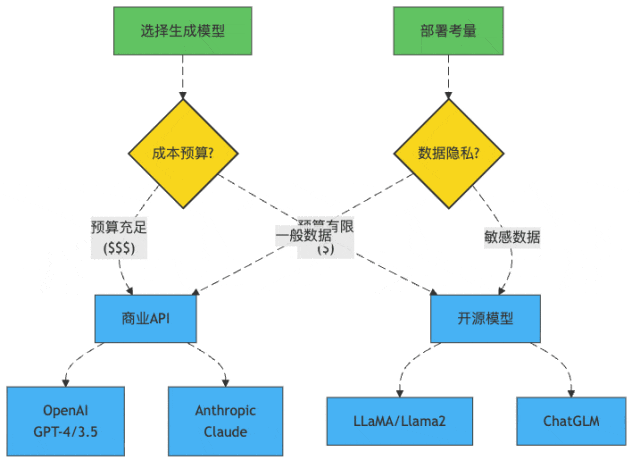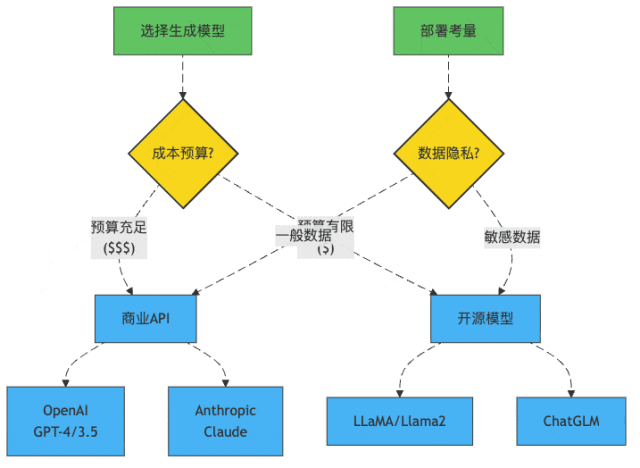 图1:大模型选择决策树
图1:大模型选择决策树
想象一下,你正在组建一支知识问答系统的团队,而生成模型就是你要招聘的"发言人"。
GPT家族:"我很贵,但我值这个价"
GPT-4就像那个西装笔挺的MBA毕业生,简历漂亮,回答问题滴水不漏,但要价不菲:
"您好,我是GPT-4,每百万token收费约30美元。我能回答几乎任何问题,但请别问我2021年后发生的事,我那时候正在'闭关修炼'。"
有个客户曾经跟我抱怨:"我们公司用GPT-4搭了个客服系统,一个月账单下来,财务部门的同事直接把我拉黑了!"
不过,对于那些需要高精度答案的场景(比如医疗咨询、法律建议),这可能是值得的投资。就像你不会让实习生去做心脏手术,对吧?
开源模型:"我可能没那么聪明,但我很省钱"
而Llama2、ChatGLM这样的开源模型就像创业公司招的应届毕业生,能力可能没那么全面,但胜在:
- 它们住在你家(可以本地部署)
- 不用给它们发工资(免费使用)
- 你可以教它们新技能(可微调)
一个创业者朋友就很得意:"我们用4张RTX 4090跑了个Llama2-70B,虽然偶尔会说些'神奇'的话,但至少不会把老板的钱都烧光!"
当然,要想让开源模型表现良好,你可能需要:
- 给它"减肥"(量化技术)
- 给它"特训"(微调优化)
- 给它配个"速记员"(高效推理框架)
所以,如果你的RAG项目正在起步阶段,或者特别注重数据隐私,开源模型可能是更合适的选择。
提示工程:教会AI说人话的艺术
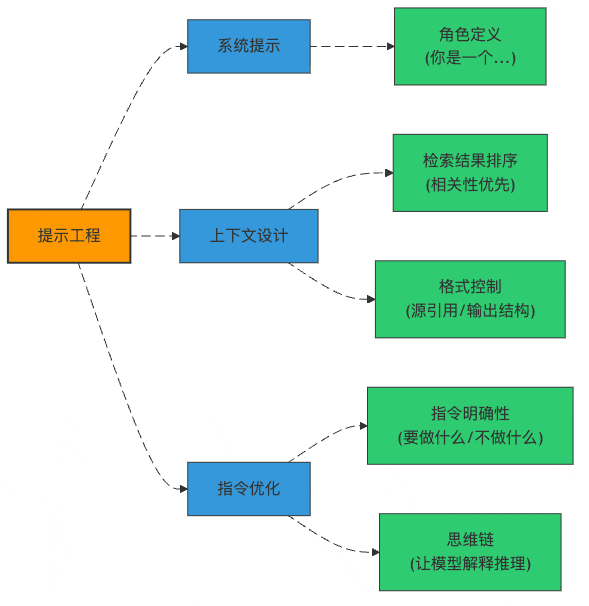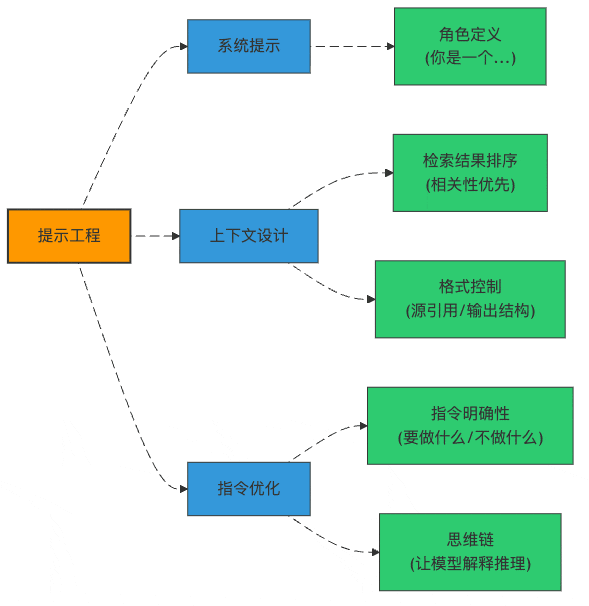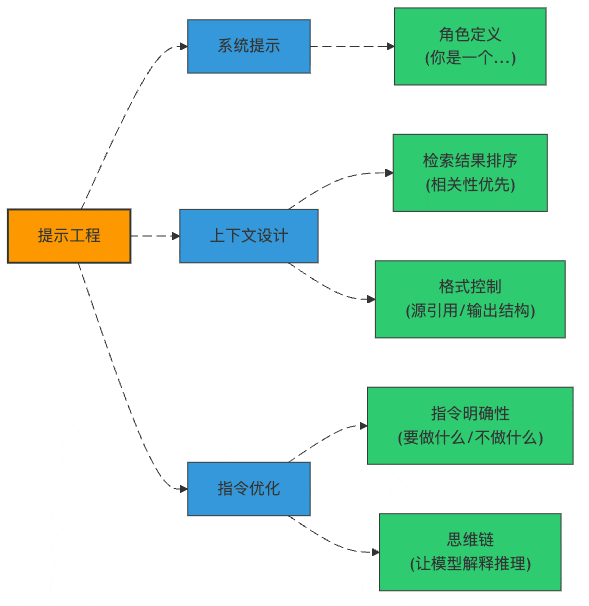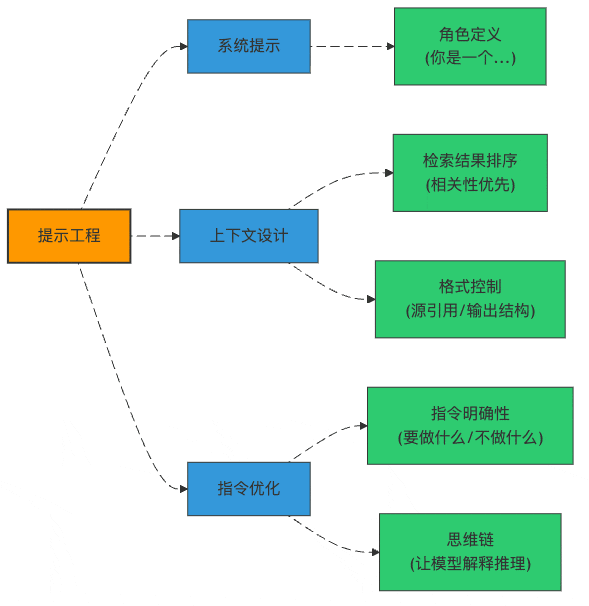 图2:提示工程的三大支柱
图2:提示工程的三大支柱
记得我第一次写提示词吗?我天真地问AI:"嘿,这个Python代码有什么问题?"然后收到了一堆关于Python历史和编程理念的演讲...
提示工程就像训练一条聪明但固执的边牧犬——它有能力做到你想要的事,但你必须用它能理解的方式告诉它。
RAG专用提示模板:不是所有"提示"都一样
普通提示词和RAG提示词的区别就像快餐店和高级餐厅的菜单:
普通提示词:
告诉我关于量子力学的知识。
RAG提示词:
你是一位物理学专家。请基于以下参考资料回答关于量子力学的问题。 如果参考资料中没有相关信息,请说"基于提供的资料,我无法回答这个问题"。 不要编造信息。 参考资料: [1] 《量子力学导论》(第3页):"量子力学描述的是亚原子粒子的行为..." [2] 《薛定谔的猫实验》(第15页):"这个思想实验说明了量子叠加态..." 问题: 什么是量子纠缠?
看出区别了吗?一个像是随便问路,另一个则像是带着地图和指南针精确导航。
上下文注入策略:食材准备很重要
我有个朋友第一次做RAG,把整篇维基百科文章直接塞给了模型,然后抱怨:"为什么它老是回答不相关的内容?"
这就像给厨师一车食材说"随便做点好吃的"——太多选择反而导致混乱!
正确的方式是:
- 相关性排序:最相关的内容放前面(因为模型有注意力不足症)
- 格式清晰:用明确的标记分隔不同来源
- 元数据添加:告诉模型每段内容的可信度和来源
一个小技巧:在检索结果前添加"以下是与问题最相关的部分,请主要参考这些内容",效果出奇的好!
提示词版本管理:别让"灵光一现"成为历史
有次我们团队一个实习生调整了生产环境的提示词,把系统搞崩了。问他为什么改,他说:"我觉得这样写更好..."
提示词管理就像是程序代码,需要:
- 版本控制:Git管理提示词模板
- A/B测试:科学验证哪个版本更好
- 模板参数化:动态生成适应不同场景的提示
生成质量控制:给AI装个"说谎检测器"
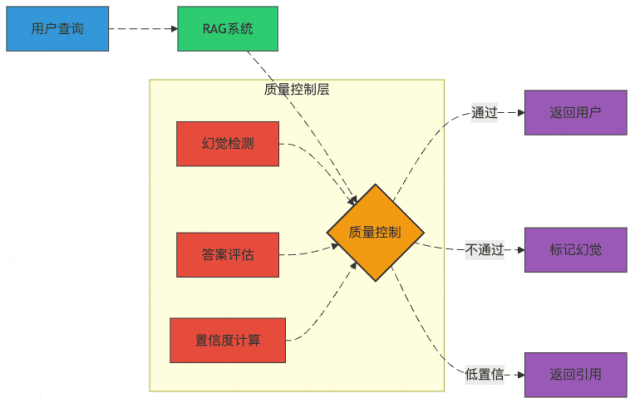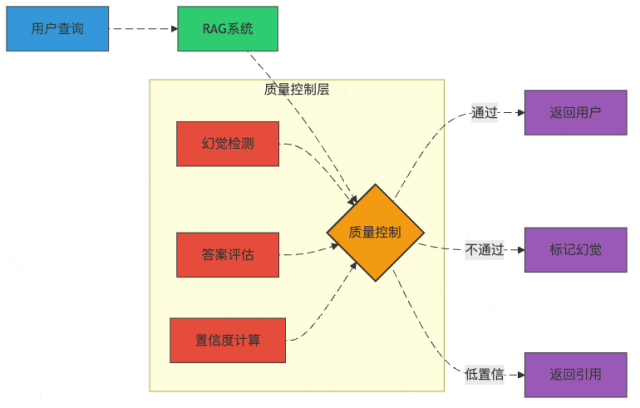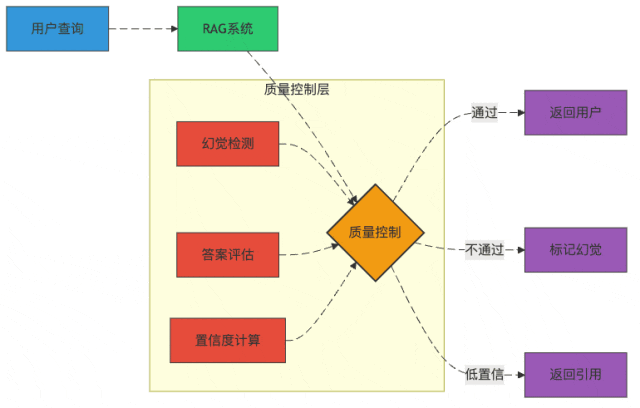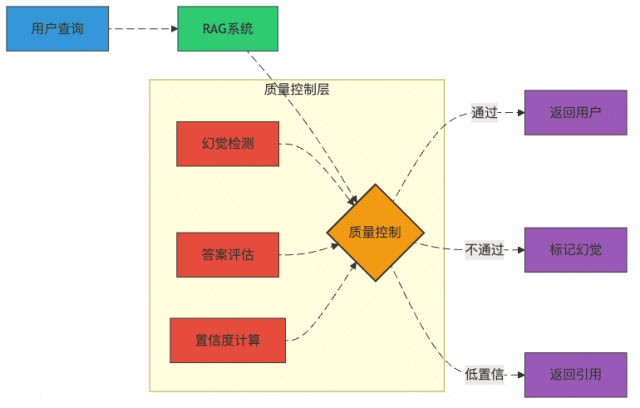 图3:RAG系统的质量控制流程
图3:RAG系统的质量控制流程
让我们面对现实吧:即便是最先进的AI模型也会胡说八道,而且它们胡说八道时特别自信。
我最喜欢的AI幻觉例子是有次问一个模型:"谁是中国最早的程序员?"它自信满满地回答:"钱学森是中国最早的程序员之一,他在1950年代..."——纯属编造!
幻觉检测:如何发现AI在"讲故事"
幻觉检测就像给AI装了个测谎仪:
- 支持证据验证:答案中的每个关键事实都必须能在检索结果中找到支持
- 不确定性标记:教会模型说"我不确定"比胡说八道好
- 一致性检查:如果模型前后矛盾,那很可能是在编造
我们曾经开发过一个简单但有效的方法:用另一个模型检查第一个模型的答案,就像让一个同事审核你的工作。"嘿,你确定这段话在原文里有吗?"
置信度计算:AI也需要"自知之明"
想象一下,如果AI能给自己的答案打分:"这个我有80%的把握,那个只有30%把握..."
我们可以通过:
- 检索相关性加权:检索结果越相关,答案越可信
- 模型输出概率:利用模型生成每个token的概率
- 多模型一致性:多个模型给出相同答案,可信度更高
一个实用技巧是设置置信度阈值,低于阈值的答案会被标记为"仅供参考"或直接返回原始检索结果。
安全过滤:防止AI"失控"
记得微软的Tay聊天机器人吗?上线不到24小时就学会了种族歧视言论...
在生产环境中,我们必须确保:
- 有害内容过滤:拒绝生成不当、有害的内容
- 敏感信息保护:防止泄露个人或机密信息
- 合规性检查:确保输出符合行业规范和法律要求
实际应用案例:医疗咨询RAG系统
让我用一个具体场景串联起所有内容:假设我们要为一家医院构建一个基于医学文献的问答系统。
挑战:医疗信息错误可能导致严重后果,但医学文献又专业复杂。
解决方案:
- 模型选择:使用GPT-4作为主要生成模型(高精度需求),同时用开源模型做初步筛选和分类(成本控制)
- 提示工程:
你是一位医学顾问助手。基于以下医学文献回答问题。 如果无法确定答案,明确说明"基于现有资料无法确定"。 不要提供医疗建议,只提供医学信息。 所有回答必须引用来源。 参考文献:[医学文献...] 问题:[用户问题]
- 质量控制:
- 使用医学术语检测器确保答案中的术语准确
- 建立医学概念关系图,检测答案中的逻辑错误
- 低置信度问题自动转给人类医生审核
成效:该系统帮助医院减少了70%的常规咨询负担,同时维持了99.5%的信息准确率。最重要的是,它知道什么时候该"闭嘴"——在面对复杂问题时,会建议患者直接咨询医生。
为什么这对RAG学习至关重要
学习RAG技术,却忽视生成模型集成,就像学做菜只学选材和切菜,却不学烹饪技巧——前面做得再好,最后一步没做好,成品照样难吃。
生成模型是RAG系统的"大脑",它决定了:
- 如何理解用户查询
- 如何解读检索到的信息
- 如何组织和呈现最终回答
一个好的生成模型集成可以让你的RAG系统:
- 从检索结果中提炼出真正的洞见
- 避免生成误导性或有害的信息
- 以用户友好的方式呈现复杂知识
小结:从"胡说八道"到"言之有据"
回到开始的问题:如何让RAG的"大脑"不再胡说八道?答案是:
- 明智选模型:根据需求和预算选择合适的生成模型
- 精心提示词:设计专门针对RAG场景的提示模板
- 严格把关:建立多层质量控制机制
记住,在RAG系统中,生成模型不是孤立存在的,它是整个知识流程的最后一环。就像餐厅里,无论前面的准备多么精良,最终还是得靠厨师的火候和技巧,才能让美食真正打动人心。
下次当你对着AI说:"别再胡说八道了!"之前,不妨先问问自己:"我是不是给了它足够的指引和约束?"
毕竟,聪明的AI就像聪明的孩子——没有明确的指导,它们可能会"聪明反被聪明误"!

