
MySQL的插件式存储引擎架构
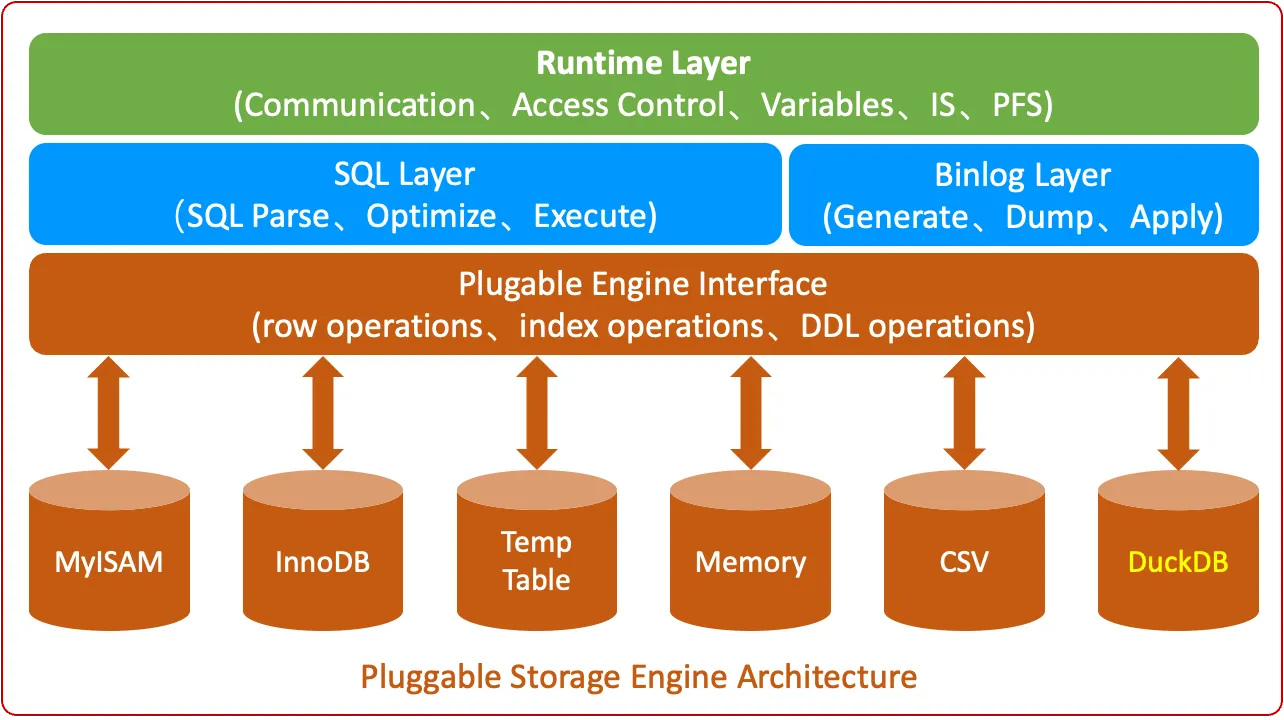
MySQL的核心创新之一就是其插件式存储引擎架构(Pluggable Storage Engine Architecture),这种架构使得MySQL可以通过多种不同的存储引擎来扩展自己的能力,从而支持更多的业务场景。MySQL的插件式架构如下图所示:

MySQL的插件式存储引擎架构可以划分为四个主要的部分:
- 运行层(Runtime Layer):负责MySQL运行相关的任务,比如通讯、访问控制、系统配置、监控等信息。
- Binlog层(Binlog Layer): 负责Binlog的生成、复制和应用。
- SQL层(SQL Layer):复制SQL的解析、优化和SQL的执行。
- 存储引擎层(Storage Engine Layer):负责数据的存储和访问。
MySQL在SQL计算和数据存储之间设计了一套标准的数据访问控制接口(Plugable Engine Interface),SQL层通过这个标准的接口进行数据的更新、查询和管理,存储引擎得以作为独立组件实现“热插拔”式集成。
目前MySQL中常用的存储引擎包括:
- MyISAM:MySQL最早使用的引擎,因为不支持事务已经被InnoDB取代。但是一直到MySQL-5.7还是系统表的存储引擎。
- InnoDB:MySQL的默认引擎。因期对事务的支持以及优秀的性能表现,逐步替代MyISAM成为MySQL最广泛使用的引擎。
- CSV: CSV文件引擎,MySQL慢日志和General Log的存储引擎。
- Memory:内存表存储引擎,也可作为SQL执行时内部临时表的存储引擎。
- TempTable:MySQL-8.0引入的引擎,用于存储内部临时表。
InnoDB作为引擎引入到MySQL,是MySQL插件式引擎架构的一个非常重要的里程碑。在互联网发展的初期,MyISAM因其简单高效的访问赢得了互联网业务的青睐,和Linux、Apach、PHP一起被称为LAMP架构。随着电商、社交互联网的兴起,MyIASAM的短板越来越明显。InnoDB因其对事务ACID的支持、在并发访问和性能上的优势,大大的拓展了MySQL的能力。在InnoDB的加持下,MySQL成为最流行的开源OLTP数据库。
随着MySQL的广泛使用,我们看到有越来越多基于TP数据的分析型查询。InnoDB的架构是天然为OLTP设计,虽然在TP业务场景下能够有非常优秀的性能表现。但InnoDB在分析型业务场景下的查询效率非常的低。这大大的限制了MySQL的使用场景。时至今日,MySQL一直欠缺一个分析型查询引擎。DuckDB的出现让我们看到了一种可能性。
DuckDB简介
DuckDB 是一个开源的在线分析处理(OLAP)和数据分析工作负载而设计。因其轻量、高性能、零配置和易集成的特性,正在迅速成为数据科学、BI 工具和嵌入式分析场景中的热门选择。DuckDB主要有以下几个特点:
- 卓越的查询性能:单机DuckDB的性能不但远高于InnoDB,甚至比ClickHouse和SelectDB的性能更好。
- 优秀的压缩比:DuckDB采用列式存储,根据类型自动选择合适的压缩算法,具有非常高的压缩率。
- 嵌入式设计:DuckDB是一个嵌入式的数据库系统,天然的适合被集成到MySQL中。
- 插件化设计:DuckDB采用了插件式的设计,非常方便进行第三方的开发和功能扩展。
- 友好的License:DuckDB的License允许任何形式的使用DuckDB的源代码,包括商业行为。
基于以上的几个原因,我们认为DuckDB非常适合成为MySQL的AP存储引擎。因此我们将DuckDB集成到了AliSQL中。
DuckDB引擎的定位是实现轻量级的单机分析能力,目前基于DuckDB引擎的RDS MySQL DuckDB只读实例已经上线,欢迎试用。未来我们还会上线主备高可用的RDS MySQL DuckDB主实例,用户可以通过DTS等工具将异构数据汇聚到RDS MySQL DuckDB实例,实现数据的分析查询。
RDS MySQL DuckDB只读实例的架构

DuckDB分析只读实例,采用读写分离的架构。分析型业务和主库业务分离,互不影响。和普通只读实例一样,通过Binlog复制机制从主库复制数据。DuckDB分析只读节点有以下优势:
- 高性能分析查询:基于DuckDB的查询能力,分析型查询性能相比InnoDB提升高达200倍(详见性能部分)。
- 存储成本低:基于DuckDB的高压缩率,DuckDB只读实例的存储空间通常只有主库存储空间的20%。
- 100% 兼容MySQL语法,免去学习成本。DuckDB作为引擎集成到MySQL中,因此用户查询仍然使用MySQL语法,没有任何学习成本。
- 无额外管理成本:DuckDB只读实例仍然是RDS MySQL实例,相比普通只读实例仅仅增加了一些MySQL参数。因此DuckDB和普通RDS MySQL实例一样管理、运维、监控。监控信息、慢日志、审计日志、RDS API等无任何差异。
- 一键创建DuckDB只读实例,数据自动从InnoDB转成DuckDB,无额外操作。
DuckDB 引擎的实现

DuckDB只读实例使用上可以分为查询链路和Binlog复制链路。查询链路接受用户的查询请求,执行数据查询。Binlog复制链路连接到主实例进行Binlog复制。下面会分别从这两方面介绍其技术原理。
查询链路

查询执行流程如上图所示。InnoDB仅用来保存元数据和系统信息,如账号、配置等。所有的用户数据都存在DuckDB引擎中,InnoDB仅用来保存元数据和系统信息,如账号、配置等。
用户通过MySQL客户端连接到实例。查询到达后,MySQL首先进行解析和必要的处理。然后将SQL发送到DuckDB引擎执行。DuckDB执行完成后,将结果返回到Server层,server层将结果集转换成MySQL的结果集返回给客户。
查询链路最重要的工作就是兼容性的工作。DuckDB和MySQL的数据类型基本上是兼容的,但在语法和函数的支持上都和MySQL有比较大的差异,为此我们扩展了DuckDB的语法解析器,使其兼容MySQL特有的语法;重写了大量的DuckDB函数并新增了大量的MySQL函数,让常见的MySQL函数都可以准确运行。自动化兼容性测试平台大约17万SQL测试,显示兼容率达到99%。详细的兼容性情况见链接
Binlog复制链路

幂等回放
由于DuckDB不支持两阶段提交,因此无法利用两阶段提交来保证Binlog GTID和数据之间的一致性,也无法保证DDL操作中InnoDB的元数据和DuckDB的一致性。因此我们对事务提交的过程和Binlog的回放过程进行了改造,从而保证实例异常宕机重启后的数据一致性。
DML回放优化
由于DuckDB本身的实现上,有利于大事务的执行。频繁小事务的执行效率非常低,会导致严重的复制延迟。因此我们对Binlog回放做了优化,采用攒批(Batch)的方式进行事务重放。优化后可以达到30行/s的回放能力。在Sysbench压力测试中,能够做到没有复制延迟,比InnoDB的回放性能还高。

并行Copy DDL
MySQL中的一少部分DDL比如修改列顺序等,DuckDB不支持。为了保证复制的正常进行,我们实现了Copy DDL机制。DuckDB原生支持的DDL,采用Inplace/Instant的方式执行。当碰到DuckDB不支持的DDL时,会采用Copy DDL的方式创建一个新表替换原表。

Copy DDL采用多线程并行执行,执行时间缩短7倍。

DuckDB只读实例的性能
测试环境
ECS 实例 32Cpu、128G内存、ESSD PL1云盘 500GB
测试类型
TPC-H SF100

线上购买 RDS MySQL 实例就可以直接体验:
https://help.aliyun.com/zh/rds/apsaradb-rds-for-mysql/duckdb-based-analytical-instance/
欢迎您加入RDS产品技术用户交流钉钉群(106730000316),有任何问题和需求都可以在群内沟通。
点击查看官网专题页:RDS MySQL DuckDB 分析实例

