
面向人机协作任务的具身智能系统感知-决策-执行链条建模
随着人工智能的发展,具身智能(Embodied Intelligence)逐渐成为机器人研究中的一个核心议题。它强调智能体不仅应具备感知和决策能力,还需与物理环境互动,通过“身体”实现学习与适应。具身智能不仅推动了机器人技术的升级,也为现实世界中的复杂任务带来了更多可能性。
本文将深入探讨具身智能与机器人技术融合的关键挑战与机遇,并通过代码示例展示如何在仿真环境中构建具身智能代理。
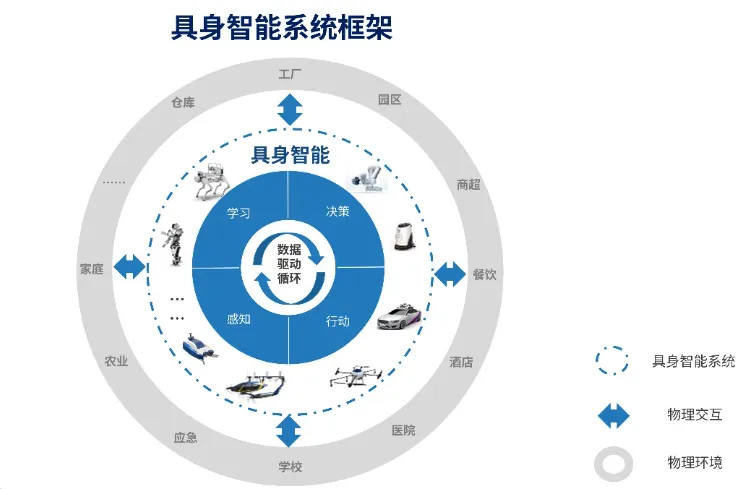
一、什么是具身智能?
具身智能是一种集感知、运动、认知为一体的智能形式。相较于传统AI仅基于抽象数据进行推理,具身智能关注以下几点:
- 感知-运动耦合:智能体通过身体感知环境,并以此调整运动策略。
- 在线学习与适应:智能体在与环境交互过程中不断优化行为。
- 主动感知:不再是被动接收信息,而是主动探索以获取最有价值的信息。
应用领域包括仿人机器人、服务机器人、救援机器人以及复杂任务控制系统等。
二、具身智能在机器人中的关键组成
1. 感知系统(Perception)
包括图像识别、深度感知、触觉反馈等模块,常用技术有CNN、SLAM、激光雷达等。
2. 控制系统(Control)
用于控制关节、轮子、机械臂等执行器。控制策略包括PID控制、强化学习控制器、模仿学习等。
3. 决策系统(Planning & Policy)
核心为决策策略模型,往往通过深度强化学习(Deep Reinforcement Learning, DRL)实现。
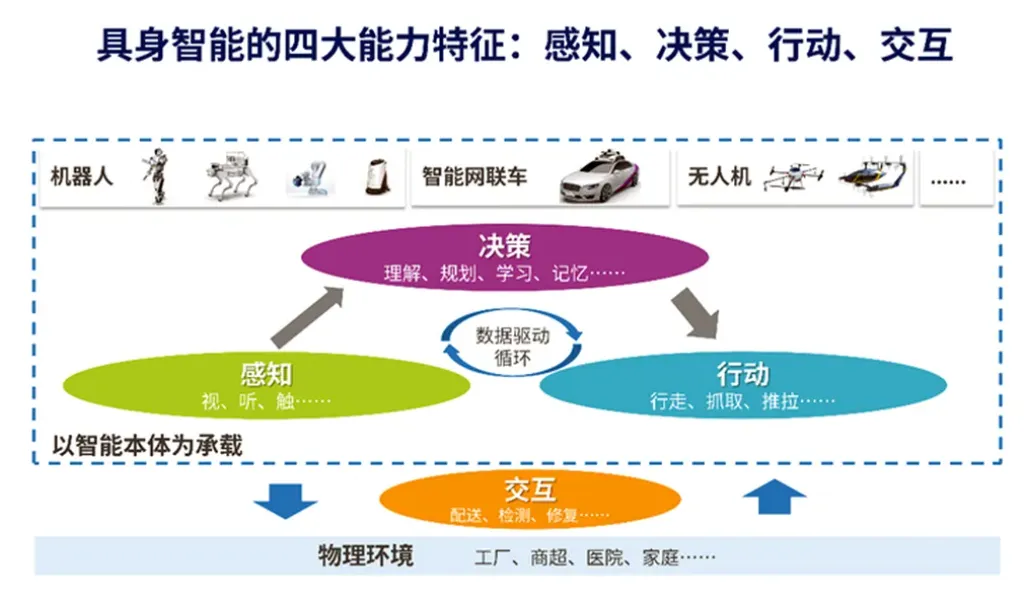
三、挑战:具身智能融合的瓶颈
1. 高维状态与动作空间
机器人与环境的交互涉及庞大的状态与动作组合,使得策略学习困难。
2. 模拟与现实的“模拟鸿沟”(Sim2Real Gap)
训练往往在模拟环境中完成,迁移到真实世界容易性能大幅下降。
3. 数据采集成本高
机器人在现实世界中试错成本高,易损耗硬件,不利于大规模训练。
四、机遇:技术融合催生新范式
1. 基于仿真平台的训练加速
使用如PyBullet、Isaac Gym等高性能仿真平台,实现快速迭代与训练。
2. 多模态感知与神经表示学习
融合视觉、触觉、语言信息,加速认知与决策学习。
3. 模仿学习与大语言模型结合
结合LLMs(如GPT)进行高层语义指令解析,推动从“命令到动作”的跨模态理解。
五、代码实例:使用PyBullet训练具身智能代理
以下是一个基于PyBullet的强化学习训练框架,演示如何训练一个简单的机械臂进行目标定位任务。
安装依赖:
pip install pybullet stable-baselines3
示例代码:
import pybullet as p
import pybullet_data
import time
from stable_baselines3 import PPO
from stable_baselines3.common.envs import DummyVecEnv
from gym import spaces
import numpy as np
import gym
class SimpleArmEnv(gym.Env):
def __init__(self):
super(SimpleArmEnv, self).__init__()
self.physicsClient = p.connect(p.DIRECT)
p.setAdditionalSearchPath(pybullet_data.getDataPath())
self.action_space = spaces.Box(low=-1, high=1, shape=(3,), dtype=np.float32)
self.observation_space = spaces.Box(low=-10, high=10, shape=(10,), dtype=np.float32)
def reset(self):
p.resetSimulation()
p.setGravity(0, 0, -9.8)
planeId = p.loadURDF("plane.urdf")
self.robotId = p.loadURDF("r2d2.urdf", [0, 0, 0])
self.target_pos = np.random.uniform(-2, 2, size=3)
return self._get_obs()
def _get_obs(self):
robot_pos, _ = p.getBasePositionAndOrientation(self.robotId)
return np.array(list(robot_pos) + list(self.target_pos) + [0] * 4)
def step(self, action):
dx, dy, dz = action
p.resetBasePositionAndOrientation(self.robotId, [dx, dy, dz], [0, 0, 0, 1])
obs = self._get_obs()
dist = np.linalg.norm(np.array(obs[:3]) - np.array(obs[3:6]))
reward = -dist
done = dist < 0.2
return obs, reward, done, {
}
def render(self, mode='human'):
pass
def close(self):
p.disconnect()
# 环境包装与模型训练
env = DummyVecEnv([lambda: SimpleArmEnv()])
model = PPO("MlpPolicy", env, verbose=1)
model.learn(total_timesteps=10000)
模型推理:
obs = env.reset()
for _ in range(100):
action, _states = model.predict(obs)
obs, rewards, dones, info = env.step(action)
该代码展示了从环境构建、策略学习到部署的完整流程,代表了具身智能系统设计的核心步骤。
六、未来展望:通向通用具身智能(General Embodied AI)
具身智能的终极目标是构建“通用智能体”,能够适应不同环境、任务和交互模式,完成开放式任务,这对系统架构、学习机制和感知交互方式都提出了更高要求。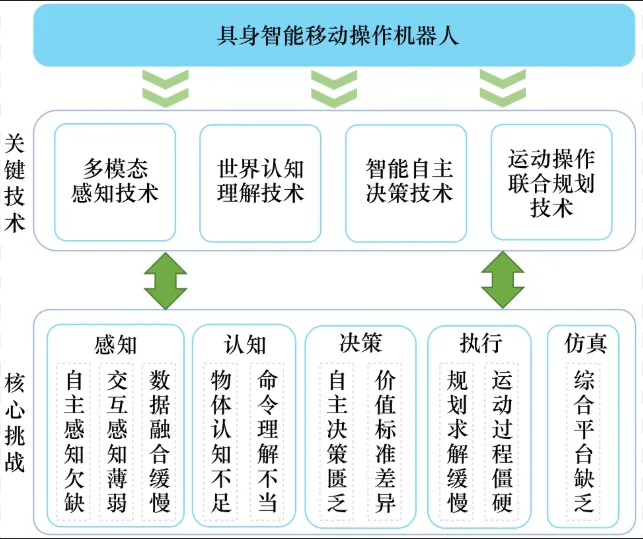
6.1 多任务、多模态统一策略
未来的具身智能系统不应局限于单一任务(如走路或抓取),而应具备任务泛化能力和跨模态理解能力。例如,机器人应能理解如下复杂语言指令:
“去厨房拿一个红色的杯子,然后递给我。”
这类任务要求系统:
- 语义解析(语言→意图)
- 多模态感知(视觉→红色→杯子)
- 空间定位与路径规划
- 操作动作(抓取→移动→放置)
6.2 多模态具身智能的技术栈构建图
┌───────────────────────────────┐
│ 自然语言指令(文本) │
└────────────┬──────────────────┘
↓
┌───────────────────────────────┐
│ 大语言模型(如GPT-4) │← Text-to-Plan
└────────────┬──────────────────┘
↓
┌───────────────────────────────┐
│ 任务规划器 + 语义映射层 │← 跨模态融合
└────────────┬──────────────────┘
↓
┌───────────────────────────────┐
│ 多模态感知(视觉/语言) │← CLIP, SAM, ViT
└────────────┬──────────────────┘
↓
┌───────────────────────────────┐
│ 控制策略(RL/模仿学习) │
└────────────┬──────────────────┘
↓
┌───────────────────────────────┐
│ 机器人执行(抓/移) │← Unitree, UR5, LoCoBot
└───────────────────────────────┘
七、多模态融合代码示例:CLIP + 视觉识别 + LLM解析
在此示例中,我们使用OpenAI的CLIP模型处理“红色杯子”的语义视觉匹配,配合语言指令与目标检测,模拟具身智能的跨模态任务。
7.1 安装依赖
pip install torch torchvision transformers openai clip-by-openai opencv-python
7.2 示例代码:文本引导的目标检测(Text-Driven Visual Selection)
import torch
import clip
import cv2
from PIL import Image
import numpy as np
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
# 假设摄像头拍下的图像
frame = cv2.imread("kitchen_scene.jpg") # 示例图片替换为真实环境图像
objects = [("object1.jpg", "blue mug"), ("object2.jpg", "red cup"), ("object3.jpg", "yellow bowl")]
# 用户指令
query = "Pick up the red cup"
# 提取图像嵌入
image_embeddings = []
for obj_img, _ in objects:
image = preprocess(Image.open(obj_img)).unsqueeze(0).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
image_embeddings.append(image_features)
# 文本嵌入
with torch.no_grad():
text_features = model.encode_text(clip.tokenize([query]).to(device))
# 匹配
similarities = [torch.cosine_similarity(text_features, emb, dim=-1).item() for emb in image_embeddings]
best_match_idx = int(np.argmax(similarities))
print(f"Selected object: {objects[best_match_idx][1]}")
这段代码模拟了机器人在环境中接收一条自然语言指令后,利用CLIP模型从多个候选图像中选出与“红色杯子”最相关的对象。这是实现具身智能理解能力的重要一环。
八、从仿真到现实:Sim2Real迁移实践路径
8.1 模拟环境构建平台
具身智能研究大量依赖于仿真平台。当前常用平台包括:
- Habitat Lab(Meta AI):高保真室内环境模拟。
- Isaac Gym(NVIDIA):支持GPU加速大规模并行强化学习。
- iGibson / RoboSuite:集物理模拟、视觉、触觉为一体。
8.2 Sim2Real迁移技术
为减少虚实差距,研究者提出以下方案:
- Domain Randomization:在训练时随机变化纹理、光照、物理参数。
- Adversarial Adaptation:使用对抗学习使模拟特征更贴近真实数据分布。
- Real-to-Sim Calibration:通过真实传感器数据修正仿真参数。
8.3 迁移示意图
模拟环境训练策略 真实机器人执行
┌────────────────────┐ ┌────────────────────┐
│ Sim Environment │ --> │ Real Robot Agent │
└────────────────────┘ └────────────────────┘
↑ ↑
域随机化/迁移学习 校准/微调
九、人类模仿学习与具身智能的结合实验
9.1 行为克隆(Behavior Cloning)示例
以下为基于演示数据训练策略网络的基本示意:
import torch.nn as nn
import torch
class BehaviorCloningPolicy(nn.Module):
def __init__(self, obs_dim, act_dim):
super().__init__()
self.net = nn.Sequential(
nn.Linear(obs_dim, 128),
nn.ReLU(),
nn.Linear(128, act_dim)
)
def forward(self, obs):
return self.net(obs)
# 加载演示数据
observations = torch.tensor([...], dtype=torch.float32)
actions = torch.tensor([...], dtype=torch.float32)
# 模型训练
policy = BehaviorCloningPolicy(obs_dim=10, act_dim=3)
optimizer = torch.optim.Adam(policy.parameters(), lr=1e-3)
loss_fn = nn.MSELoss()
for epoch in range(1000):
pred_actions = policy(observations)
loss = loss_fn(pred_actions, actions)
optimizer.zero_grad()
loss.backward()
optimizer.step()
通过这种方式,机器人可以“模仿”人类演示动作,快速获得具身策略,为复杂操作任务提供可行的初始策略。
十、总结:迈向通用具身智能的融合之路
具身智能(Embodied AI)正日益成为人工智能发展的关键方向,其核心理念是将智能“植入”物理实体,使其能通过感知、行动与学习,像人类一样在真实环境中完成复杂任务。随着深度学习、多模态模型、机器人控制与大语言模型等技术的融合,具身智能系统已经从实验室走向了通用泛化的新时代。
本文深入探讨了具身智能与机器人技术融合的多个关键维度:
分析了从视觉、触觉、语言到动作的多模态融合机制;
展示了基于CLIP等跨模态模型的目标识别代码实践;
论述了从仿真到现实(Sim2Real)的迁移挑战与解决路径;
给出了行为克隆等模仿学习算法的简化实现;
展望了具身智能系统向通用智能体(General Embodied Agent)演进的未来。
我们可以看到,具身智能不仅是AI模型结构的创新,更是对“感知—理解—决策—执行”全链条智能的重塑。随着GPT-4、Claude、Gemini 等大语言模型具备了更强的逻辑推理能力,它们也正逐步成为具身系统中的“脑”,与“身体”(机器人平台)实现深度协同。
未来,具身智能将在智能制造、家庭服务、医疗辅助、灾难救援等多个领域大放异彩。它不仅是人工智能发展的前沿阵地,也是推动人类与机器深度协作的关键引擎。

