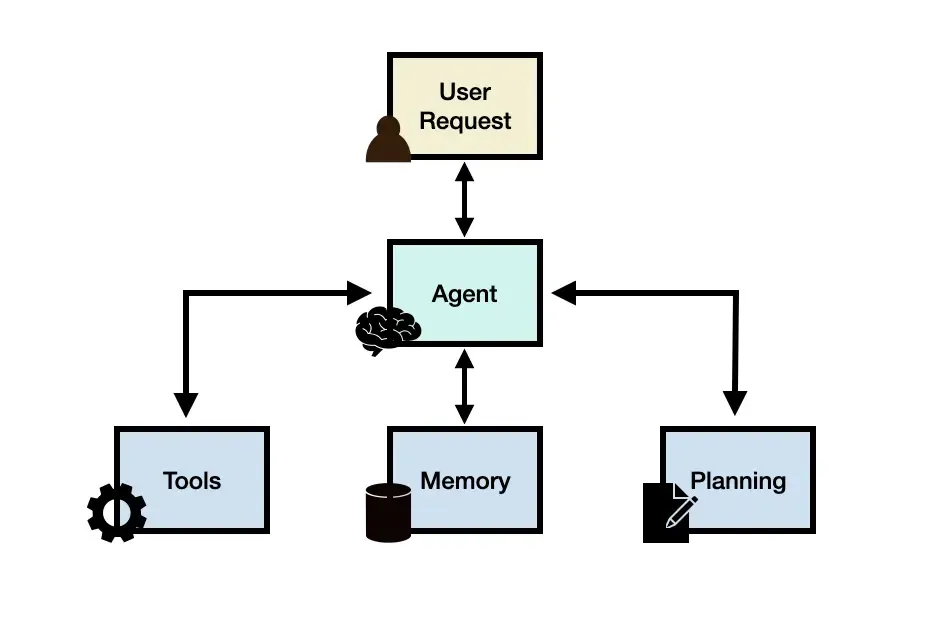
AI ops,即通过AI的方式,去提升ops的效率洞察力可观测概念以及前哨。如何让系统于整个机器和AI为可视。主要为三个主题,第一讲解监控观测和洞察之间几个概念之间的区别和平时operation工作所面临的挑战,第二agi概念出现对于过去可观测的工作,有哪些变化以及对应的想象力。最后分享最佳实践,以rag和问答,如何把可观测的能力放到其中让大模型调用,对于客户更加的有具有洞察力。
一、监控、观测与洞察
1.从监控到观测
科普简单的概念,二三十年之前随着整个数字化技术的诞生,监控理念被发现。无论是各种开源的社区或标准,提出词:可观测技术。可观测是通过一些multidimensional data,对于整个系统有更深入的反馈,如可以通过log,trace,metric profiling等各种手段,让对于整个系统的变化有更深刻的了解,同时会发现可将概念延伸到各个场景里面,除平时的double工作之外,概念叫security ops,工作如果去做简单的抽象,可以理解为在目标系统里面去采集日志,对于数据做临时的存储和加工,根据整个业务优化的目标去做输出,去做类比去感知整个it数字的环境,根据自己的想法去做处理做输出,所以会看到可观测概念,可延展到security ops business operation等等众多领域中。
2.观测到洞察挑战
衍生概念发现对于每个不同的公司和开发人员,有不同挑战。图最左侧是目标的系统,认为系统是立体的系统,不同的人如用户a,用户b和用户C,使用不同的工具,采集不同的数据。最后凭借不同的经验,对于整个目标系统的认知是有偏差的。存在有经验的用户,使用了非常好工具,基本上可以把整个系统里面所有的变化状态,有个非常深入的了解,但是缺乏经验的工程师使用开源系统,对于目标系统,感知能力都会降低。如果拿整个AI领域非常时髦的名词去阐述话题,会产生是否可找到非常general的方法,让整个目标系统在各个角度产生的投影数据,如trace和metric,可以把类比成在向量维度的投影,让数据去提供存算一体的系统,最后和整个大模型里面所有的概念去对齐,未来专家不需要去写任何的规则,只要把所有的概念让大模型去理解。随着整个大模型认知,推理能力的提升,同时就拥有了两年运维专家开发专家和安全专家的经验。目前在尝试是否可以有一套general的方法帮助把整个可观测系统的洞察能力和agi结合在一起,把事情做得更通用。
有三大挑战,第一大挑战,数据和概念的挑战。
举例说明,如apple词,在不同的context下面会有不同的语境,如目前在描述iPhone,就知道apple是cooperation的代称,但是在说“what did you eat in your lunch”apple指向的是水果,所以必须对不同可观测数据里面描述的实体去做采集。
第二,过去数据都是散落在各个开源系统,为了和整个agi去对齐,需要做工作把离散的数据放在一起,解决如何通过系统,对于过去整个面向的数字目标,从整个可观测到可解释最后达到整个可预测的目的。
3.AI Powered 可观测
做4块主要的工作,第一块叫知识图谱概念对齐和语义检索,等同于数据从目标端产生到最后被消费。语义内容,只有当时写日志或者写指标的人才能去理解,需要尝试一种手段,通过定义一种通用的图谱,让数据语义从产生端到消费端一致。
第二目前整个数据稀缺,从投影角度,目前可观测数据种类还在不停的增多,需要有一些能力对于数据去做增强。
最后两块,尝试如何通过一些机器学习和统计学习的方法,让整个系统的洞察能力做得更强,copilot可以去极大提升整个工作的效率。
二、AI+计算 重塑可观测
分享如何让AI和计算把可观测能力提升台阶。
1.挑战1:数据割裂,概念漂移
三维空间里面,指代了不同的对象。举例描述,如当收到一条告警,告警的内容是192.168.3.1。指标,增加了100%,但是不同的人,对于IP有不同的解读,如目前在vpt子网里面,指向了对象是蓝色的对象,但是在另外一套系统里面,因为是属于不同的网络空间,有对象是另外一块,所以如果通过文本去理解一件事情,对于本身去做这件事情产生不确定性。
第二块,如过去有很多时间序列的算法,可以通过算法去对于整个指标去设告警,但是当设的算法不理解整个指标,语义的情况下面,告警是徒劳的。
举例说明。西方某国家的客户,有指标即线上下单率,但是每年都会去过节日,节日期间大家会停止所有的线上的活动,所以到点上面,指标会产生非常大幅的波动,问题的本质在需要把当时的context传递下来,让认知指标背后代表的location是什么context是什么,以及背后表达的含义。如收到一条告警,经常会发生情况,a系统,报了系统,出现了告警,b系统认为是OK,所以看到在不同的软件里面,大家对于很多事情的认知都是产生的偏差。
2.UModle:可观测 数字图谱
为解决问题定义了一套叫U model的可观测的数字图谱,数字图谱里面包含两个概念。第一个概念为:Data schema,定义了一套非常通用的类似字典的机制,字典当去做数据采集,就非常明确的去把指标(无论用户对指标起什么样的名字)都跟字典里面的概念去做对应,把变成确定性的一个语义。
第二个部分,定义:entity Schema,在过去欧洲古典逻辑里面,把叫做ontology,本体,本体相当于对于所有可观测里面出现的对象,定义了唯一的schema。举例说明,如目前定义的类叫com.aliyun.ecs,当所有的实例是属于类,就明确语义,目前所有描述实例的对象,都是类别下的。通过这两种方式,就完成了所有可观测对象里面的数据对象在语义层面的对齐。
3.UModel+QWeng对齐概念
了解整个对齐的过程。在最底部,面对的场景是叫多源头碎片化和低信息量的数据,每条日志单位的价值密度是很低的,原因是描述的是单体的事件,通过把进行统一存储之后,完成了对于整个异构数据的把centralization的工作。概念图谱在过程中会把里面数据所有的字段,所有描述的对象去做关联,关联做完之后,在第4步,系统里面会有很多日志的输出,如目前有一条日志,描述了IP,动作,做了operation,延时和返回码,如果有图谱之后,可以通过通义大模型把这条数据变成结构化的内容。举例,会看到192.168.3.1,会加标签,讲目前有对象叫ecs,唯一的ID叫1001,做的何种动作,影响到哪个对象里,最后的延时的形式。持续场景类似,在过去时序场景里面,看到的更多为指标,可以通过整个通义大模型,把指标变成大模型,可以了解的patch。举例,可以把所有的上升言变成类似的文本,把下降言变成另外文本,相当于所有的多模态的可观测数据,都往前去走了一小步,把语义更明确,让和大模型去做联通。
讲解视频方便进一步了解,该视频整体的过程在于当接入目标系统之后,能自动的去把目标系统里面的对象生成,这里对象包含很多系统,比如数据库满MySQL有redis LB ecs,K8s的Pord以及应用程序,对象在统一接入模块的初始化的过程中,都会根据目标系统做自动的生成,之后可以对于所有联通的对象去做自然语言的查询和检索。最后可以通过日志去做反向关联,比如解读一条日志,知道日志里面所有的字段都在描述何种事件,从而达到相互跳转的目的。
首先过程是已经在线上的系统,里面有各种各样的对象,可以通过语法去查询对象所在的实体,也可以通过模糊检索的方法,去检索对应的实例,检索之后可以非常快速的跳转到图上去看实例的数据,同时可以使用自然语言的查询,去询问所有拓扑之间的关系,如目前的服务跑在哪些机器上,机器依赖于哪些数据库,数据库是不是有其的服务的依赖,所有的交互本身背后不依赖于任何CMDB,都是图谱的方式进行存储的,所有的指标日志都是联通的。如目前有一套Java的日志,可以通过关联的方法,去解读日志里面所有的片段,在描述什么样的一件事情,和哪些实例相关,可以通过跳转的方式,快速去查看对应的实例,所以,通过这种schema和entity relation图谱的定义,实现了整个多模态系统之间的数据,相互连通和跳转。
4.挑战2:可观测分析挑战
定义之后系统为了达到对接,还需要去做非常大数据量的数据的整合,举例:目前不同的场景,对于整个诉求的数据的诉求是不一样的,会看到过去为了去分析问题,Sre的工作人员往往需要在4~5个平台里面去做,反复的跳转和个粘贴,通过关键词去找到日志,把对应的IP拿出来,再到CMDB里面去链接,同时向trace,或者log需要到不同的系统里面去交互。
5.多模态存储+分析架构
目前尝试把整个可观测领域,多模态的存储和分析进行统一。统一分层较多,主要为元数据和语义的统一。
首先,整个存储系统把所有的数据分成两个类别,第一类别telemetry data。Data特点跟时间序列相关的,第二个是多维的,会发现 log等都把认为这块某时间点上系统在某个维度的投影,右边这侧叫可观测图谱存储,会去存储所有系统对应的实体和实体对应的关系。做了整个处理系统的统一,如原生会去提供一套SQL和spl的语法,对于所有的数据去做统一的存储分析和脚印,在之上也做生态兼容的API,如ECS KAFKA。可以做到一件事情用户习惯性的使用所熟悉的运维系统,如elastic search,但底层数据又可以通过prometheus的协议,直接读出,从而可以做到不改变用户习惯的情况下,让所有的数据放在一起互联互通。
如目前有elastic search的集群,上面跑了很多的日志,过去会为了去计算指标,需要通过flink的任务,把数据先拖出来,写到prometheus存储,最后通过方案去做可视化,目前如果做了整个存储和计算系统的统一之后,就可以在不搬数据的情况下达到效果。
如何打通ecs和prometheus。首先网页存储了非常多的日志,数据在底层,会把放到SL4的平台,上层做了协议的兼容,可以使用各种算子,对于指标,去做计算,生成后台计算的任务。如目前根据整个延时去做了每个方法的统计的图,可以把数据保存到时序库的对象里面,保存完成之后,就看到前台的访问日志,就会每分钟生成对应的点,就可以通过目前的metric查询,去把计算结果给查询出。如可以通过prometheus的协议去把所有计算完成之后的数据拿到。同时,因为对于整个prometheus的grammer进行兼容,所以可以非常无缝的去拿到整个关于访问日志计算的结果,通过整个存储的统一,打通了各个开源软件之间的数据。
6.开箱即用机器学习、异常检测函数
AI ops,AI的copilot很重要的部分是需要去提升一些数据洞察的能力,在这里内置了很多非常common的可观测场景的一些常见的算法,统计学习,机器学习异常检测等等各个领域的函数,也提供了200多个开箱即用的内置告警和报表,让客户去洞察整个业务。这里给大家去做简单的演示,同样,演示的目标还是访问日志的数据源。看到访问日志为平面,可以通过聚合函数把访问日志,变成时间序列数据,可以调用copilot,如可以对于整个序列去做描述,在整个序列检测的过程中,算法去做整个变点检测和异常检测,各种各样的周期的分析的能力,所以未来无论是什么样的数据,因为目前所有的持续的概念和大模型做了对齐,所以可以让大模型去读懂所有一些持续的数据,举个例子,刚才是比较平的数据。看一下周期性数据的特点,同样可以通过调用整个持续的检测能力,大模型就会对于整个持续的检测去做很多的拆分,如周期,长周期的趋势是什么样,噪声是什么样的,当把噪声去除之后,背后是否会有一些异常点,一些异常点是什么,都可以让大模型去洞察所有持续变化背后的一些细节。
三、最佳实践与未来展望
面向目前的AI的应用,可观测可做实践与未来展望。
1.阿里云AI Stack 可观测解决方案
第一,当使用AI应用的过程中,会看到整个软件体系stack非常深的,包含整个模型的预训练推理调用的整个过程,如果一分为二,会看到在冰山之下是整个模型预训练的过程,开发者需要关注上半部分怎么去调用AI去完成整个应用的升级。设计是推理的阶段,在推理阶段,阿里云可观测团队,提供了非常轻量级的解决方案,叫做LLM应用的可观测解决方案,里面会有两个部分构成,d第一定义了一套兼容的整个协议,在协议之上,对于字段进行了扩展,提供了Python的agent,Python agent可以认为是对于应用无侵入的采集器,当目前应用和采集器做了集成之后,所有python sdk里面写的应用程序涉及到所有大模型的,无论是阿里云的,或者是open AI各种开源的引擎,都自动去识别,在识别背后,会把你整个调用rag的过程,调用tools的过程,调用的结果,token数把给采集下来,变成一些可观指标,如目前的性能手针返回时间每个trace调用的链路,都可以把拿到。右侧图相当于当chat book完成调用之后,背后的链路是什么样的,哪些链路,经过的应用系统,哪些涉及到整个大模型的调用,调用的结果context,input output和上下文是什么样的,都可以拿到。
介绍过程:首先会有接入中心的应用,在接入中心可以去选择large language model的application,这里目前支持4种,以llama index来作为例子,会有对应采集的指标和对应的模板,可以去选择对应的region来去做埋点,选择之后,就会产生对应Python相关的依赖包,接入之后就去提供一些常见的报表,以及,对应的trace的链路,可以根据不同的筛选条件,如根据不同的时间,应用名称,是不是调用tools对于整个chatboard,或者是rag的应用去做筛选,筛选完成之后,可以点击详情,看到里面所有调用和retriever的过程,如点一下retriever的过程,看到用户写的in 和output prompt。对数据去做进一步的分析,举个例子,会看到用户做了很多问答,如的问题是如何拥有更好的睡眠,如果对于数据无法进行逐条分析,可以利用目前内置的通义千问的大模型,对于所有的input和output进行enrich,做后会看到用户所有的问答,以及进行语义分析。会发现加了两个字段,叫input semantic,叫output semantic,会对于所有的问答做分类,分完类之后,可以根据topic对于所有的调用做检索,如想看所有健康类的调用,也可以去向量去检索过去问了改善睡眠相关的问题,通过这种方式,帮助快速去debug。目前AI相关的产品和的应用,最后也可以通过一些分析的手段,去对于所有用户,目前的调用去做分类,如目前查询类和法律咨询类占了多少比例有多少,是正确的,有多少客户根本没有回来,所以通过这种模式,非常容易的把可观测能力应用在各种新的AI的场景中。
2.总结
做可观测会有4个阶段。第一阶段会使用各种垂直的工具去解决各种的问题,如通过metric通过log,trace去解决业务的投影方向的认知的问题。在第二个阶段,把所有的数据在平台里面去存储和分析,即将各个散落在各地低信息量的数据汇聚在一起。目前,给大家讲解的是第三个阶段,数据放在一起之后如何让数据里面的概念和对象让机器,让用户去做理解,会看到整个过程中知识概念。最后阶段为愿景,当在散落在系统里面的投影产生的知识被连通之后,和整个大语言模型对齐之后,就可以借助整个AI的力量,让AI扮演整个专家的角色去认知整个系统,每个人未来既是开发的专家,又是安全的专家,同时也是业务分析的高手。