Django作为一个高级Python Web框架,其自带的对象关系映射(ORM)是其最强大的特性之一。ORM允许开发者以编程语言原生的方式操作数据库,而无需编写原始的SQL查询。本文展示如何在Django项目中利用ORM执行各种数据库查询,并提供详细的代码示例及其解释。
基础查询操作
查询所有对象
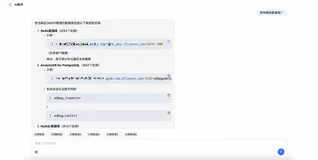
from myapp.models import MyModel # 获取MyModel表中的所有对象 all_entries = MyModel.objects.all() for entry in all_entries: print(entry)
from myapp.models import MyModel: 导入应用中定义的模型。MyModel.objects.all(): 获取MyModel表中的所有对象。for entry in all_entries: 遍历查询到的所有对象,并打印。
过滤查询
# 获取所有is_active为True的对象 active_entries = MyModel.objects.filter(is_active=True) for entry in active_entries: print(entry)
MyModel.objects.filter(is_active=True): 使用filter方法筛选出字段is_active值为True的对象。
排除查询
# 获取除了is_active为True之外的所有对象 inactive_entries = MyModel.objects.exclude(is_active=True) for entry in inactive_entries: print(entry)
MyModel.objects.exclude(is_active=True): 使用exclude方法排除字段is_active值为True的对象。
获取单个对象
# 获取主键为1的单个对象 try: entry = MyModel.objects.get(pk=1) print(entry) except MyModel.DoesNotExist: print("MyModel with pk=1 does not exist.")
MyModel.objects.get(pk=1): 获取主键(Primary Key)为1的对象。try...except: 异常处理,防止查询不到对象时抛出DoesNotExist异常。
复杂查询操作
链式查询
# 获取is_active为True且name以'D'开头的所有对象 filtered_entries = MyModel.objects.filter(is_active=True).filter(name__startswith='D') for entry in filtered_entries: print(entry)
filter(is_active=True).filter(name__startswith='D'): 链式调用filter方法来组合筛选条件。
Q对象复杂查询
from django.db.models import Q # 获取is_active为True或者name以'D'开头的所有对象 complex_entries = MyModel.objects.filter(Q(is_active=True) | Q(name__startswith='D')) for entry in complex_entries: print(entry)
from django.db.models import Q: 导入Q对象。Q(is_active=True) | Q(name__startswith='D'): 使用Q对象结合逻辑运算符|(或)构建复杂查询。
跨关联关系查询
假设MyModel有一个外键ForeignKey指向另一个模型RelatedModel。
# 获取MyModel的所有对象,其关联的RelatedModel对象的name为'Sample' related_entries = MyModel.objects.filter(relatedmodel__name='Sample') for entry in related_entries: print(entry)
relatedmodel__name='Sample': 使用双下划线__跨关联关系查询RelatedModel的name字段。
聚合与分组查询
from django.db.models import Count # 对MyModel对象按is_active字段进行分组,并计算每组的数量 grouped_entries = MyModel.objects.values('is_active').annotate(count=Count('id')) for entry in grouped_entries: print(f"Active: {entry['is_active']}, Count: {entry['count']}")
from django.db.models import Count: 导入Count聚合函数。values('is_active').annotate(count=Count('id')): 使用values方法分组并使用annotate进行聚合,计算每组的数量。
性能优化查询
选择性字段查询
# 仅获取MyModel对象的id和name字段 partial_entries = MyModel.objects.only('id', 'name') for entry in partial_entries: print(entry.id, entry.name)
MyModel.objects.only('id', 'name'): 使用only方法来限制查询只返回特定字段。
延迟字段查询
# 在需要时才查询MyModel对象的description字段 deferred_entries = MyModel.objects.defer('description') for entry in deferred_entries: print(entry.description) # 这里才会实际查询description字段
MyModel.objects.defer('description'): 使用defer方法延迟加载指定字段,直到实际访问该字段时才会执行查询。
使用select_related优化关联对象查询
假设MyModel有一个外键ForeignKey指向另一个模型RelatedModel。
# 通过select_related获取MyModel和其关联的RelatedModel对象 entries_with_related = MyModel.objects.select_related('relatedmodel') for entry in entries_with_related: print(entry.relatedmodel)
MyModel.objects.select_related('relatedmodel'): 使用select_related方法来优化对关联对象的查询,减少数据库的查询次数。
使用prefetch_related优化多对多和反向关联查询
假设MyModel与OtherModel有多对多关系。
# 通过prefetch_related获取MyModel及其多对多关联的OtherModel对象 entries_with_others = MyModel.objects.prefetch_related('othermodel_set') for entry in entries_with_others: for other in entry.othermodel_set.all(): print(other)
MyModel.objects.prefetch_related('othermodel_set'): 使用prefetch_related方法来优化多对多和反向关联查询。
赶紧存一下吧!