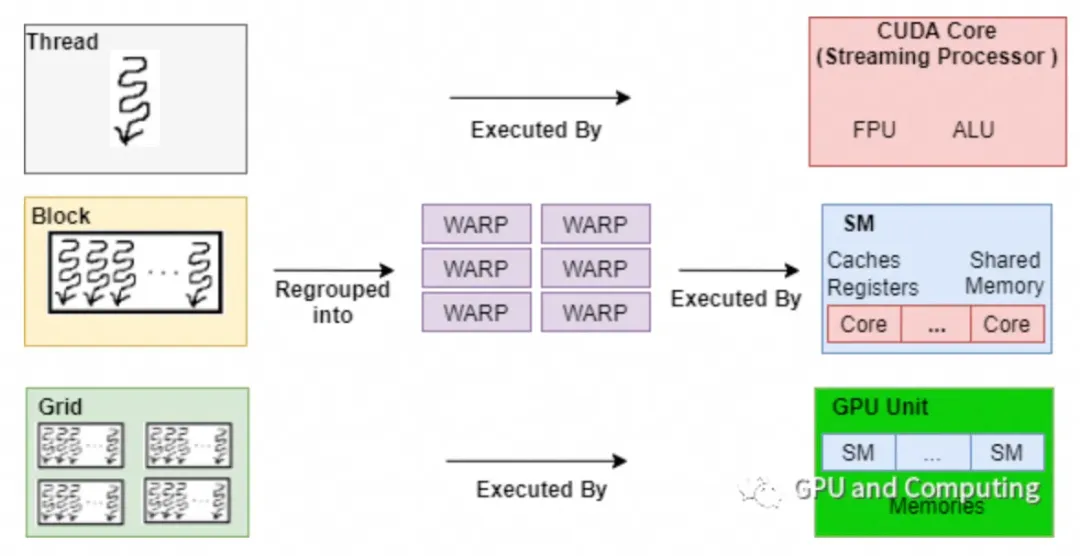
在深度学习中,测量GPU性能是至关重要的步骤,尤其是在训练和推理过程中。以下是一些常见的测量GPU性能的方式和详细解释:
1. 运行时间(Runtime)测量
描述:运行时间测量是评估GPU性能的最直接方式,即通过测量模型训练或推理所需的总时间来判断性能。可以测量单次迭代的时间、多次迭代的平均时间或整个训练过程的总时间。
优点:
简单直接,易于理解。
适用于对比不同模型或不同硬件的性能。
局限:
可能受到其他系统因素的干扰,如I/O操作、CPU负载等。
仅提供总体性能数据,无法细化到具体的操作或步骤。
2. 吞吐量(Throughput)测量
描述:吞吐量测量指的是在单位时间内GPU处理的数据量,通常以每秒处理的样本数(samples per second)或每秒处理的图像数(images per second)表示。这种方法更适合评估GPU在处理大批量数据时的效率。
优点:
直接反映GPU处理数据的能力。
易于比较不同GPU或不同配置的性能。
局限:
需要对数据进行合理分批,以避免批量大小对结果的影响。
与运行时间测量类似,可能受到系统其他因素的干扰。
3. GPU利用率(GPU Utilization)
描述:GPU利用率是指GPU在执行深度学习任务期间的使用率,通常以百分比表示。高利用率意味着GPU资源被充分利用,而低利用率则可能表示存在瓶颈,如数据传输延迟或I/O操作。
优点:
提供关于GPU资源使用效率的直接反馈。
有助于识别和解决性能瓶颈。
局限:
需要结合其他测量方法(如内存使用情况)进行全面分析。
仅显示总体利用率,无法细化到具体的操作或步骤。
4. 内存使用情况(Memory Usage)
描述:内存使用情况测量包括GPU显存的已用内存和剩余内存。显存不足可能导致内存溢出错误,显存使用过多也会影响性能。
优点:
帮助优化模型大小和批量大小,避免内存溢出。
提供关于模型资源需求的直接反馈。
局限:
需要结合其他测量方法进行全面分析。
仅显示显存使用情况,无法细化到具体的操作或步骤。
5. 计算能力(Compute Capability)
描述:计算能力评估包括GPU在不同计算任务中的性能,如浮点运算速度(FLOPS)。这类测量通常通过基准测试工具完成,以评估GPU在特定任务上的计算效率。
优点:
提供关于GPU计算性能的详细数据。
有助于选择最适合特定任务的GPU。
局限:
需要专门的基准测试工具。
通常仅适用于特定任务或操作,无法全面反映实际应用中的性能。
6. 端到端性能测试(End-to-End Performance Testing)
描述:端到端性能测试测量整个深度学习训练和推理过程的性能,包括数据加载、前向传播、反向传播等所有步骤。
优点:
提供关于整个流程的全面性能数据。
帮助识别和优化流程中的各个环节。
局限:
需要详细的日志和跟踪工具。
结果可能受到多种因素的影响,需要综合分析。
7. 显存带宽(Memory Bandwidth)
描述:显存带宽测量指的是GPU显存的读写带宽,评估数据在显存中的传输速度。高带宽有助于加快数据处理速度。
优点:
提供关于数据传输性能的详细数据。
有助于优化数据传输和内存管理。
局限:
需要专门的基准测试工具。
通常仅适用于特定操作,无法全面反映实际应用中的性能。
8. 框架自带性能工具
描述:许多深度学习框架(如PyTorch、TensorFlow)提供内置的性能分析工具,这些工具可以详细记录和分析模型的运行时间、内存使用情况和各个操作的性能。
优点:
提供关于具体模型和操作的详细性能数据。
易于集成到现有工作流程中。
局限:
需要了解和掌握特定框架的工具和使用方法。
分析结果可能需要进一步处理和解释。
9. 基准测试工具
描述:专用基准测试工具(如DeepBench、AI-Benchmark)用于评估不同深度学习操作在各种硬件上的性能。
优点:
提供标准化的性能评测结果。
有助于对比不同硬件和配置的性能。
局限:
通常仅适用于特定任务或操作,无法全面反映实际应用中的性能。
需要专门设置和运行基准测试。