
你是否曾为大模型训练数据的标注工作感到头痛?
是否在寻觅一款简单、好用、免费的开源的多模态文本对话标注工具?
是否急需一款能团队协作标注的管理平台?
别慌,超好用的标注平台Label-LLM拯救你!
大模型的训练离不开高质量的标注数据,正是这些数据的精准标注,为模型的进化与演变提供了坚实的基础。这其中,以ChatGPT为代表的大语言模型的爆火,激发了研究人员和开发者对于多轮对话标注的强烈需求。然而,数据标注的过程往往繁琐且耗时,尤其是在多轮对话和多模态数据的标注上,挑战更是层出不穷。
为了更好地满足个人及团队等对文本对话的各类标注、管理需求,OpenDataLab团队继多模态标注工具LabelU之后,全新开源了一款面向大模型训练的多模态标注平台——Label-LLM。

这款平台不仅支持多人协作轻松完成多模态数据的标注任务,还能通过智能化的工具和高效的工作流,显著提升标注质量和效率。无论是纯文本,还是图像、视频、音频等交错问答、对话标注,Label-LLM都能提供全面的支持。现在,让我们一起深入了解这个强大的工具,看看它如何在大模型训练的标注过程中,大显身手。
Label-LLM的主要功能及特色
Label-LLM是一款能够让你轻松愉快完成标注任务的利器!接下来,让我们用2分钟时间,来快速了解一下它的主要功能及特色。
01 丰富的任务类型
作为一款面向大模型训练数据标注平台,Label-LLM集成了多种常见标注工具,并支持用户进行自由灵活的个性化配置。Label-LLM支持对整段对话以及对话中的提问或回复进行标注,可适配现有大语言模型训练中绝大部分的数据标注任务需求。如:
● 回答/指令采集:根据要求扮演AI助手解答给定的问题,或向AI助手发出符合要求的指令,包括常识问答、文本分类、文本重写、开放性问答等。
● 偏好收集:根据提供的问题和评估标准,为AI生成的多条回答进行排序。
● 内容评估:基于给定的评价准则与问题,评估回答的质量、相关度或者是否包含敏感信息。
● 分类标注:支持对数据进行分类标注,为模型的分类任务提供准确的训练数据。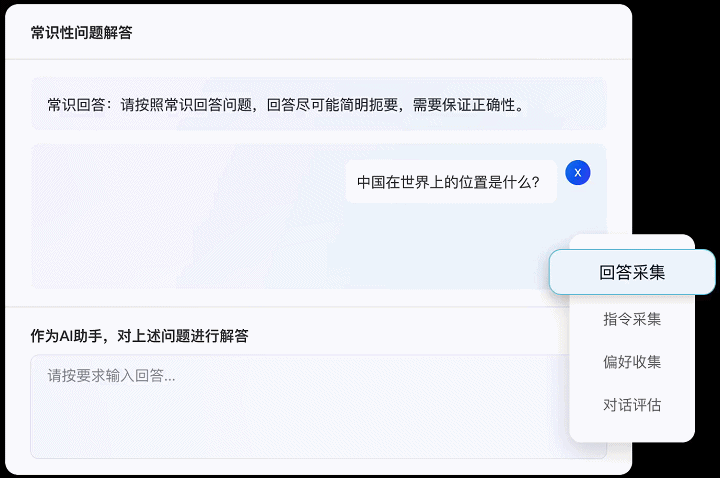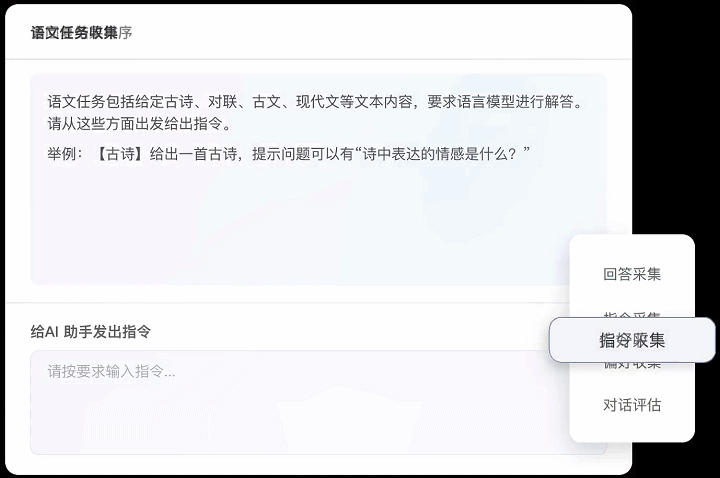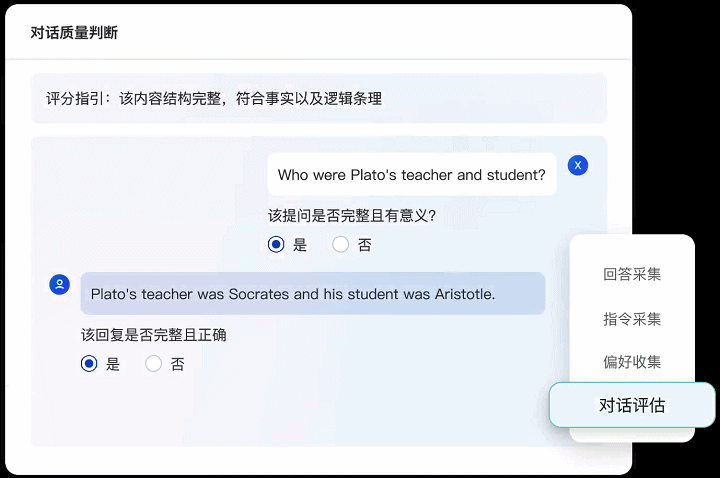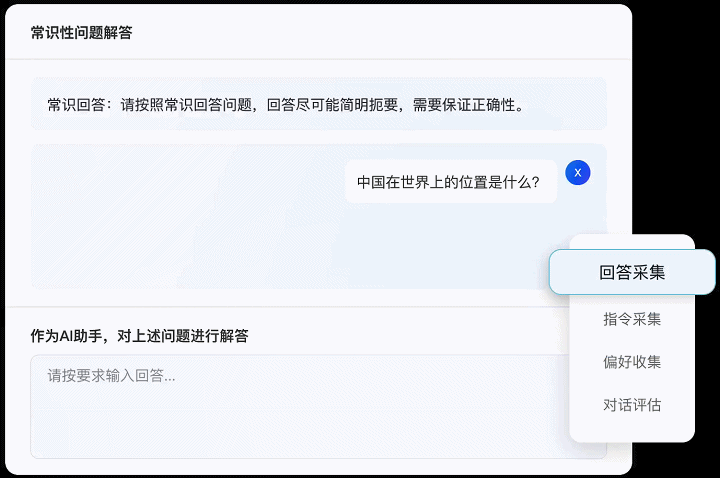
02 多模态数据标注支持
Label-LLM不仅支持纯文本数据的标注任务,同时也兼容图像、视频和音频等多种数据模态,这意味着Label-LLM能够有效地满足现阶段对多模态大型模型微调数据的标注需求,能执行更为复杂的数据标注工作。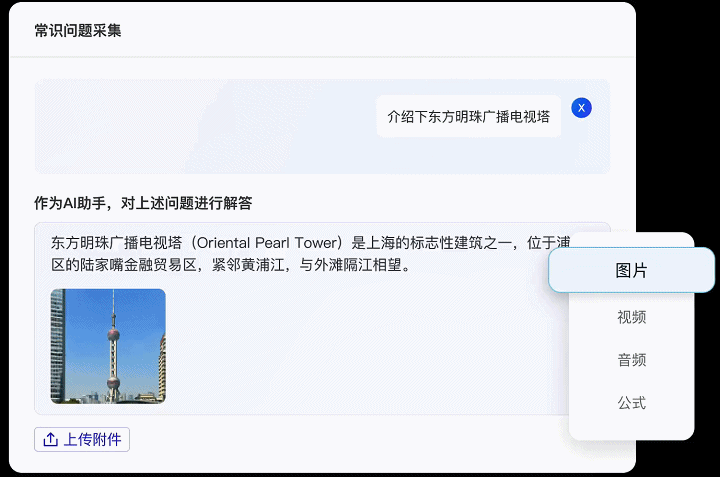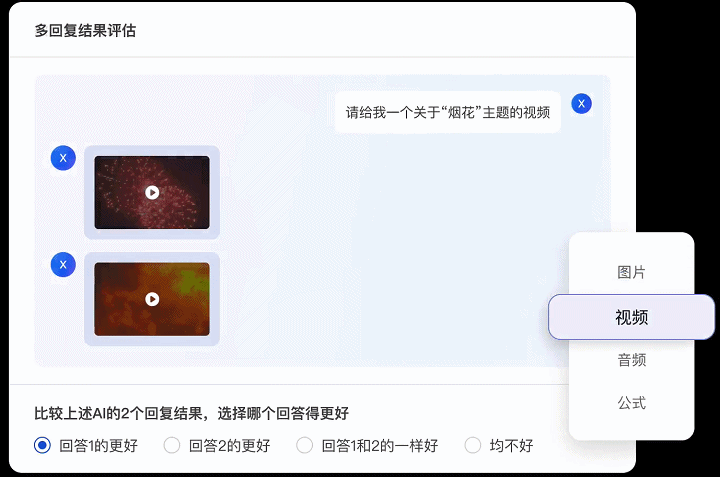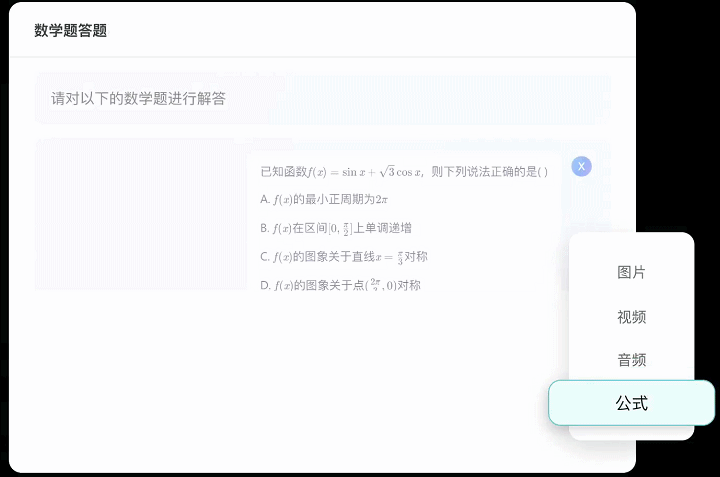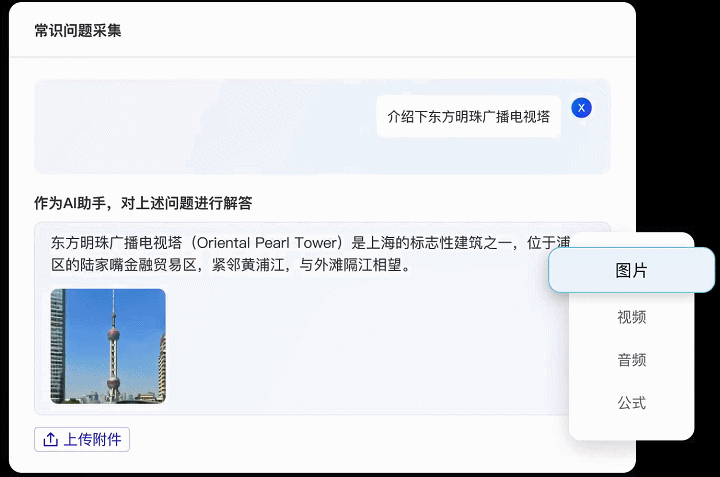
03 支持预标注载入
Label-LLM支持导入预先标注的JSONL文件以进行二次修改。这意味着用户可以先利用多种大模型进行大规模的自动标注,在后期的人工标注过程中针对预标注中不够准确的条目进行微调、修正,从而显著提升数据标注的效率和数据质量。
04 全方位可视化任务管理
Label-LLM还提供了对于标注任务全流程的监控管理。
● 标注任务进度实时把控:能够追踪任务执行全过程,实时把控任务进度与标注质量。
● 标注结果可视化分析:支持对于已标注数据进行筛选对比,并且可以进行多维度数据分析。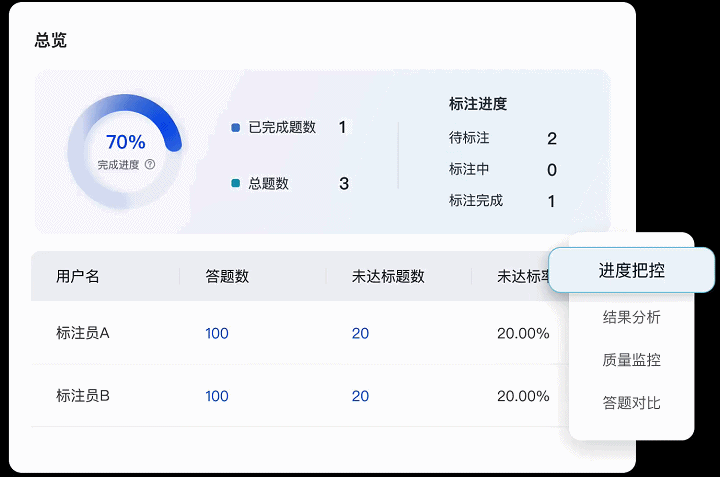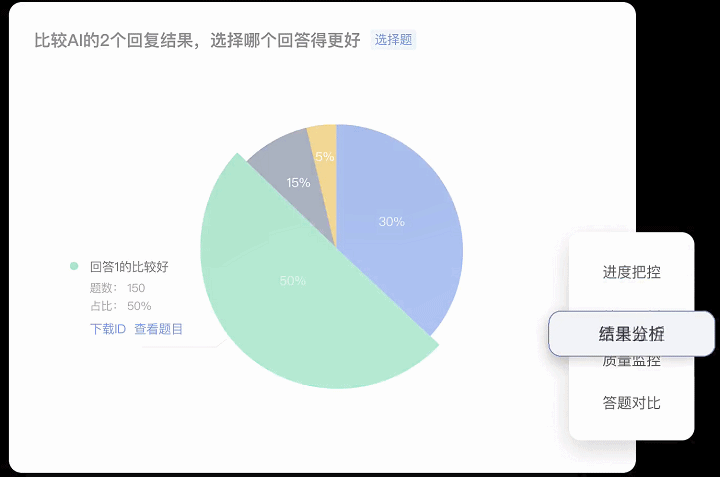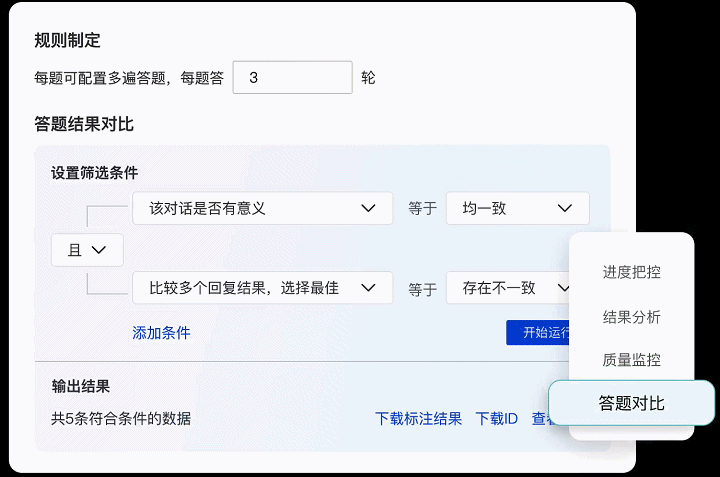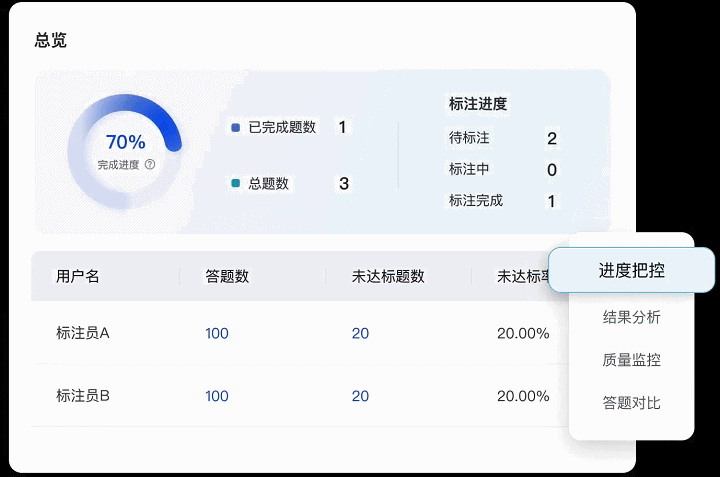
Label-LLM标注配置小技巧
在配置Label-LLM标注功能时,要根据任务需求来选择标注对象和打标类型。
首先要选择标注对象类型。根据标注对象的不同,标注对象类型可分为三大类:
整段对话内容:对完整的对话进行标注。
对话中的提问:仅针对对话中的提问部分进行标注。
对话中的回答:仅针对对话中的回答部分进行标注。
接下来,要选择标注的打标类型。无论标注对象是哪一种,打标都分为两大类:
选择题:包括单选题和多选题。这种题目需要提前配置好具体选项内容,标注时通过下拉菜单勾选。
文本题:允许自由填写内容,同时也支持设置默认值,方便快速标注。
在选择上述选项后,您就可以通过自由组合标注工具,灵活适配适合自身的标注场景、任务或题目了。配置好标注工具,可以进入工作台,愉快地上传数据分配标注任务了。
Label-LLM安装部署教程
另外,Label-LLM还提供了诸如预标注载入、可视化任务管理等功能,帮助大家提升标注效率,快来试试吧。
Label-LLM 部署文档:
https://github.com/opendatalab/LabelLLM/wiki/README%E2%80%90zh
更多数据处理宝藏工具,尽在 OpenDataLab GitHub仓库:
https://github.com/opendatalab
还有超好用的多模态标注工具 LabelU:
https://github.com/opendatalab/labelU
不要吝啬你的star!



