
PDF文档遵循一定的规范,例如精确定位了每个字符出现在页面上的坐标、根据坐标绘制的各种形状(线、矩形、曲线等)。所以,用PDF格式传输和打印文档可以保证格式的一致性,不会像Word那样因为渲染引擎的不同而出现格式错乱、多页少页等问题。
Word文档则是一种流式布局,元素之间的相对距离决定了其呈现在页面上的最终位置。因此适合编辑内容,前文内容的修改自动促发后续文档布局的更新。
PDF转Word是一个古老的话题,其难点在于建立从PDF基于元素位置的格式到Word基于内容的格式的映射。
PDF文档实际并不存在段落、表格的概念,PDF转Word要做的就是将PDF文档中“横、竖线条围绕着文本”解析为Word的“表格”,将“文本及下方的一条横线”解析为“文本下划线”,等等。
pdf2docx支持Windows和Linux平台,要求Python版本>=3.6。
pdf2docx安装方式:
pip install pdf2docx

pdf2docx使用
from pdf2docx import Converter
思路如下
- 获取pdf文件路径。
- 过滤出当前文件夹中所有的pdf文件。
- 提取pdf文件名和后缀名。
- 文件名+'docx'拼接重组word文件(改变格式不变文件名)。
- 使用pdf2docx进行文件转换。
源码
代码很简单,源码奉上,思路都在注释里已经说明
import os from pdf2docx import Converter def pdf_docx(): # 获取当前工作目录 file_path = os.getcwd() # 遍历所有文件 for file in os.listdir(file_path): # 获取文件后缀 suff_name = os.path.splitext(file)[1] # 过滤非pdf格式文件 if suff_name != '.pdf': continue # 获取文件名称 file_name = os.path.splitext(file)[0] # pdf文件名称 pdf_name = os.getcwd() + '\\' + file # 要转换的docx文件名称 docx_name = os.getcwd() + '\\' + file_name + '.docx' # 加载pdf文档 cv = Converter(pdf_name) cv.convert(docx_name) cv.close()
测试
我们准备的pdf文档有格式,有图片。先来进行测试

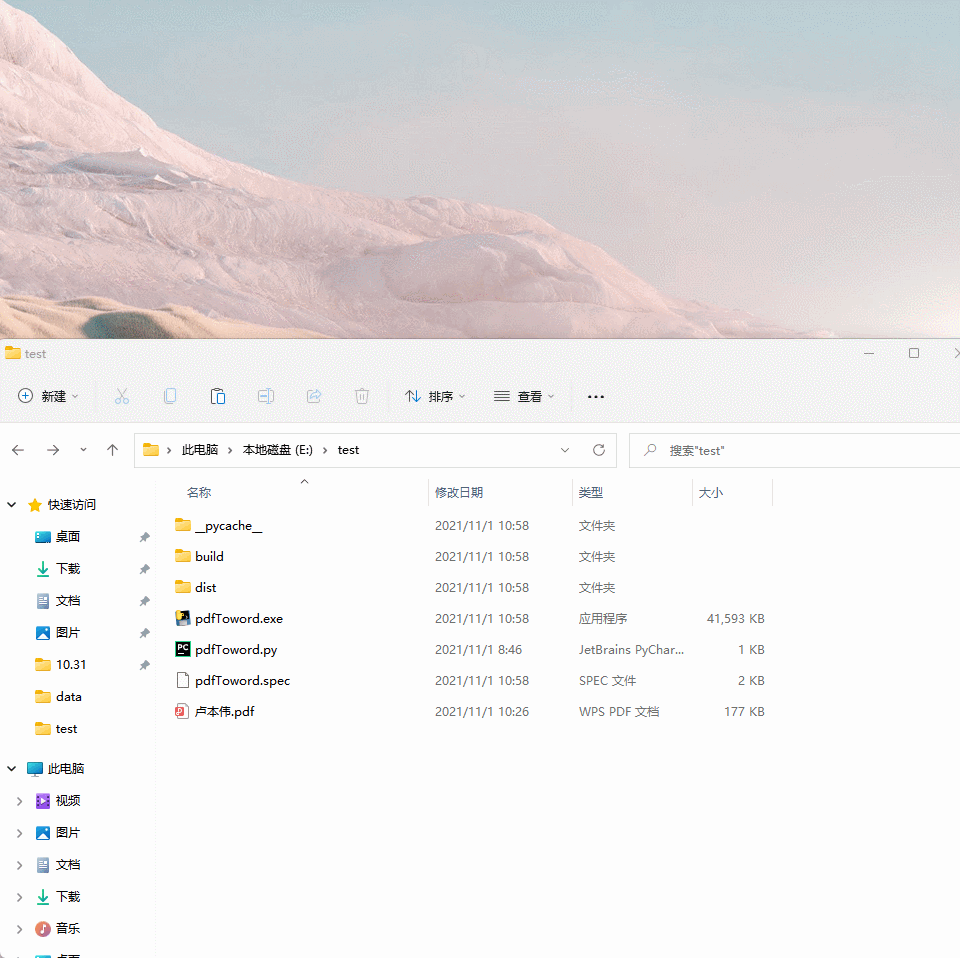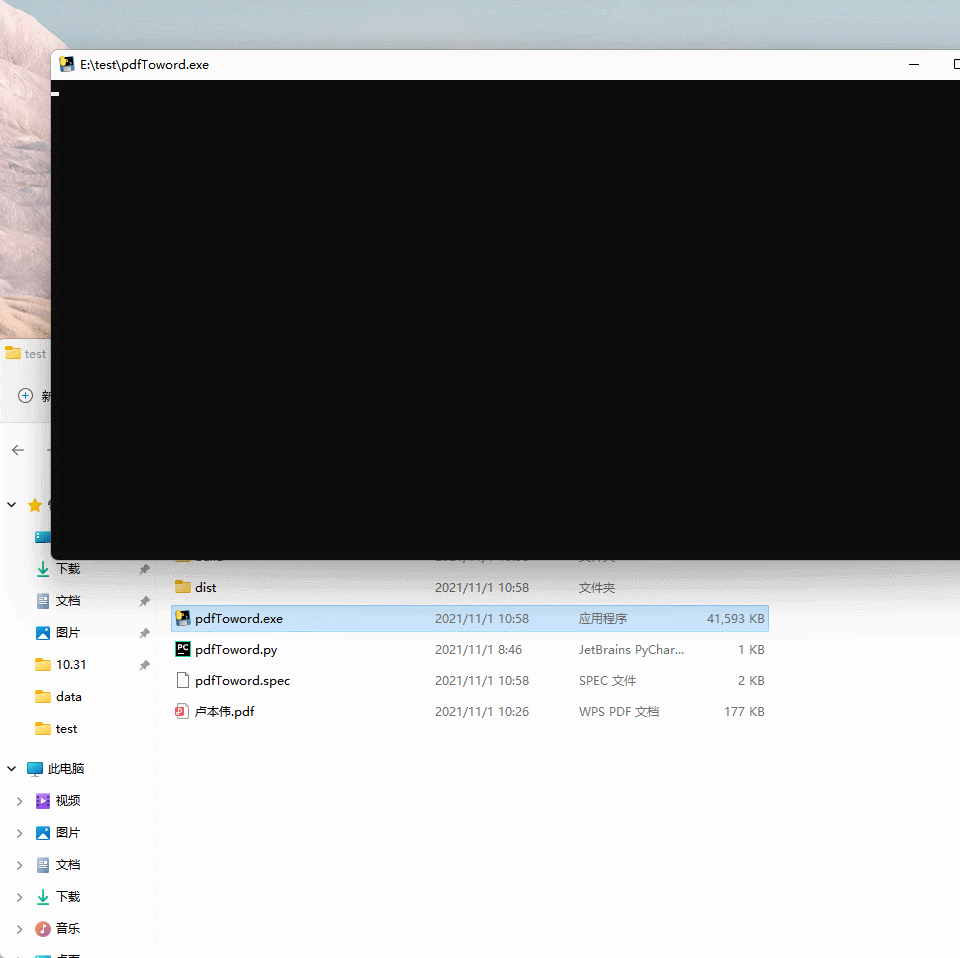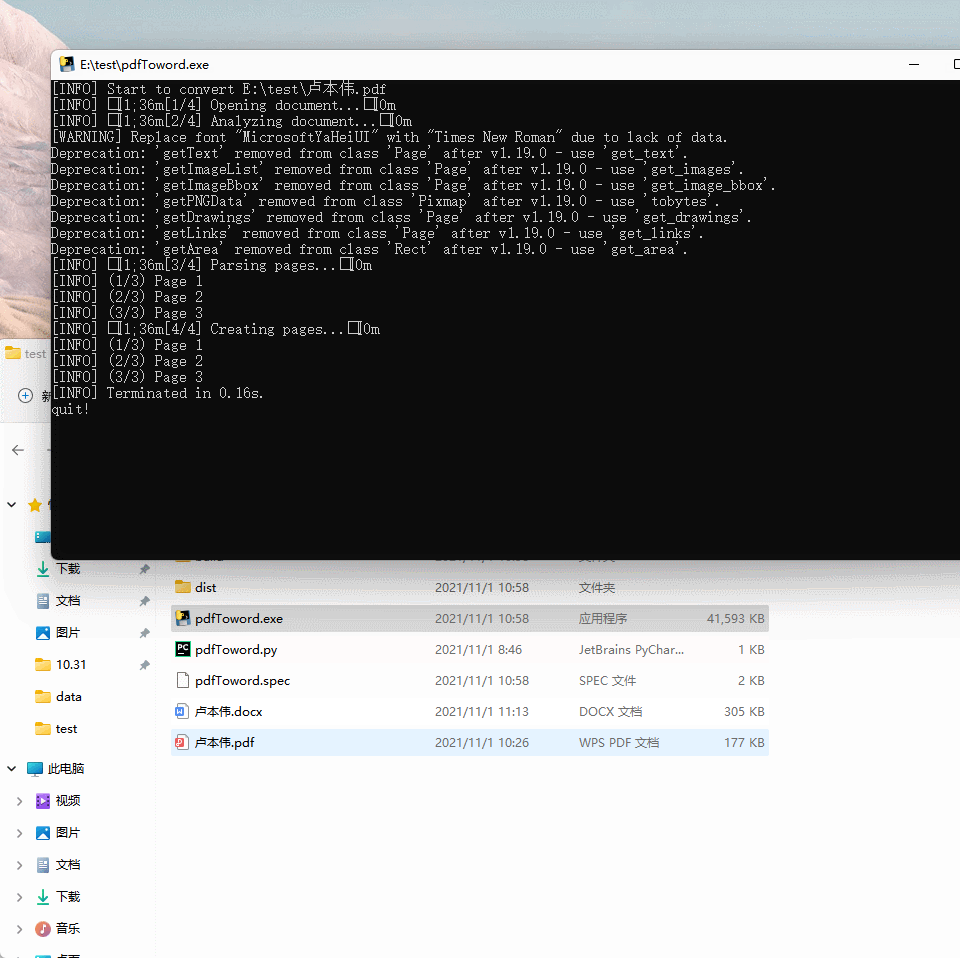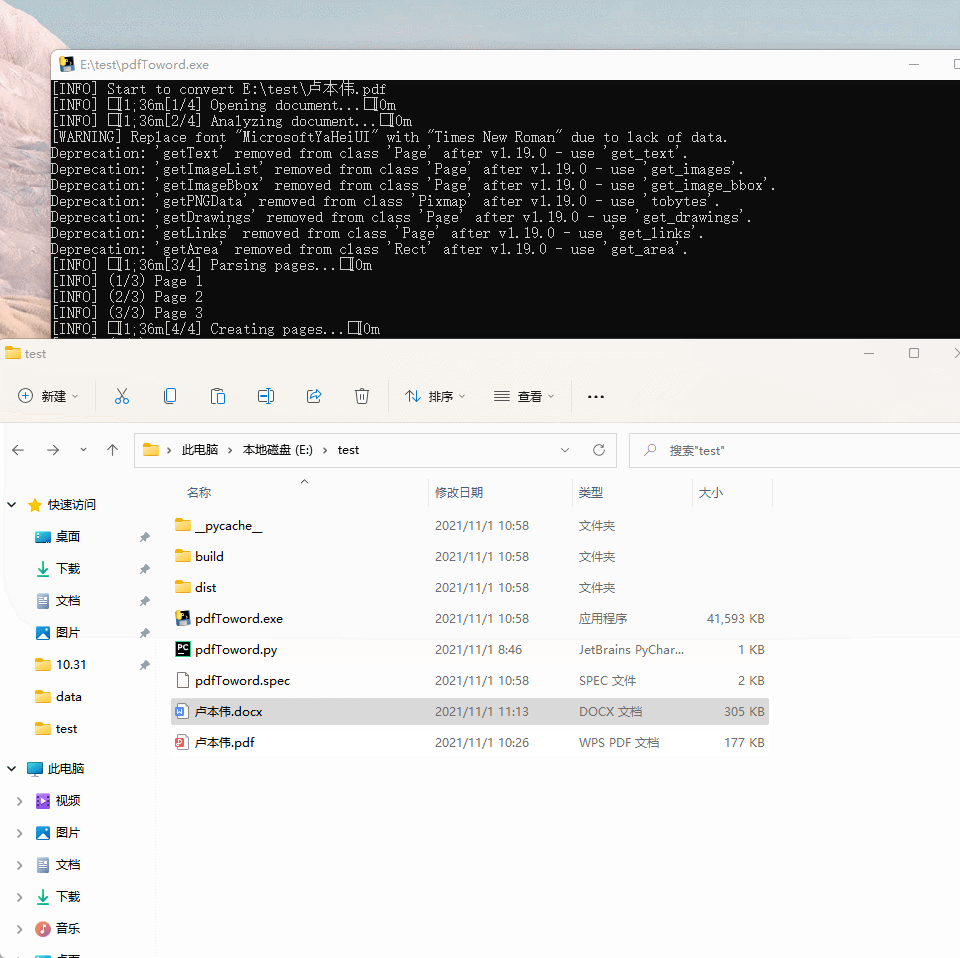
控制台信息打印如下,0.17秒完成了3页pdf->docx文件的转换
[INFO] Start to convert E:\Python\pycharm++\GOGO数据\卢本伟.pdf [INFO] [1/4] Opening document... [INFO] [2/4] Analyzing document... [WARNING] Replace font "MicrosoftYaHeiUI" with "Times New Roman" due to lack of data. Deprecation: 'getText' removed from class 'Page' after v1.19.0 - use 'get_text'. Deprecation: 'getImageList' removed from class 'Page' after v1.19.0 - use 'get_images'. Deprecation: 'getImageBbox' removed from class 'Page' after v1.19.0 - use 'get_image_bbox'. Deprecation: 'getPNGData' removed from class 'Pixmap' after v1.19.0 - use 'tobytes'. Deprecation: 'getDrawings' removed from class 'Page' after v1.19.0 - use 'get_drawings'. Deprecation: 'getLinks' removed from class 'Page' after v1.19.0 - use 'get_links'. Deprecation: 'getArea' removed from class 'Rect' after v1.19.0 - use 'get_area'. [INFO] [3/4] Parsing pages... [INFO] (1/3) Page 1 [INFO] (2/3) Page 2 [INFO] (3/3) Page 3 [INFO] [4/4] Creating pages... [INFO] (1/3) Page 1 [INFO] (2/3) Page 2 [INFO] (3/3) Page 3 [INFO] Terminated in 0.17s.
转换完成后的docx文件格式如下:

现在我们已经完成了pdf转word的操作,这样的局限性太大了,万一我的pc没有python环境怎么搞?
接下来我们对文件进行打包,让你随时随地可以转换文档
python 上常见的打包方式目是通过 pyinstaller 来实现的。
pip install pyinstaller

详细步骤
pyinstaller 是一个命令行工具,下面是详细步骤
1、cmd 切换到 python 文件的目录
2、执行命令 pyinstall -F pdfToword.py
执行完毕会发现生成了 3 个文件夹

其中 dist 文件夹就有我们已经打包完成的 exe 文件。

3、双击 exe 就可以运行成功了。一键抓换pdf-word
够方便的吧~~
今天的分享就到此结束啦,

