文章目录
简介
安装
初始配置
数据分析
简单查询
创建场景
创建集合和仪表盘
自定义查询
原生查询
sql变量
动态sql片段
管理员操作
添加数据库
连接oracle
成员管理
邀请新成员
权限配置
数据权限
文件夹权限
邮箱配置
定时任务
简介
Metabase是一个免费的BI分析工具,可以帮助你把数据库中的数据更好的呈现给更多人,通过建立一个”查询“来提炼数据,再以图形化的方式做展示。上手简单,操作门槛低,即使不会sql语句也能使用。同时工具轻量、安装依赖的环境简单、配置简单清楚,只需一个jar包和一条命令就能完成安装
安装
Metabase的安装非常简单,只需将jar包下载下来后(下载地址),放在有java环境的机子上,通过java -jar命令启动即可,启动命令:
java -jar metabase.jar
1
这里需要注意的是metabase自带的H2数据库相对较弱,最好替换成其他数据源,比如MySQL等,这里可以参考我的另一篇文章:《metabase默认应用数据//代码效果参考:http://www.jhylw.com.cn/165933803.html
源H2变更为MySQL及历史数据迁移》初始配置
启动后metabase默认端口为3000,如果要变更端口,可添加环境变量MB_JETTY_PORT来指定端口
,假设metabase为本地启动,浏览器访问网址:即可进入初始化界面
按提示一步步填写相关信息即可,注意第一个创建的账户默认即为管理员账户
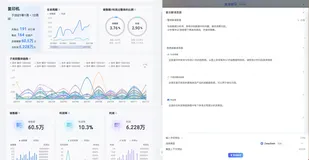
等待初始化之后,进入首页即可看到配置数据库下的所有表
数据分析
接下来就可以正式使用了,右上角各功能如下:
下面就以具体场景为例,分别解释各项功能,点击创建问题 --》简单查询,先从简单的开始,走一遍整体流程
简单查询
假设我要对一张名为customer_group_info的客户群表做多个维度的分析,表结构与测试记录如下:
需求场景如下:
根据status状态字段做聚合,查看各个状态下的客群数
根据insert_time创建时间字段对客群做趋势分析
筛选出cgp_type客群类型为3的客群
创建场景
场景1:
1) 右上角选聚合,聚合条件为总行数,分组条件为status,聚合结果如下:
2) 为了便于观察,我们以图表形式显示,选择右下角“可视化”,选择图表类型
3)保存该问题,由于目前还没新建集合,先默认保存在“分析下”
场景2,3类似,就不再赘述
场景2:
场景3:
以上三个问题创建完毕,目前都保存在“分析”下,为了便于分类管理,下面就新建一个集合,把以上问题归类
创建集合和仪表盘
回到首页,进入“分析”,新建名为“客群分析”的集合,然后把问题移到该集合下
目前虽然已经归类到一个集合下了,但是查看还是很不方便,还是要每个问题分别点进去才能看到,下面就开始建一个仪表盘,把这三个问题整合到同一个仪表盘下,点右上角“+”号,选择新仪表盘,放到“客群分析”集合下
然后在仪表盘中把三个问题添加进去即可
这样,后续对这三个场景的数据分析,就可以直接在该仪表盘中查看了
自定义查询
自定义查询相较于简单查询,支持更高级的操作,如多表关联,表与创建的问题之间的关联等,但整体操作还是跟简单查询类似,这里就不再重复了
原生查询
原生查询即直接写sql查询,但是前提是该用户必须有sql查询的权限,权限问题会在后面的权限管理中讲到。
sql查询可直接通过右上角控制台图标进入,进入后记得要先在左上角选择数据库
metabase中的sql可以支持变量和根据变量做动态sql拼接,变量形式:{ {变量名}},动态sql片段形式:【【and 字段 = { {变量名}}】】,具体如何使用,下面举例说明。
sql变量
还是以customer_group_info这张表为例,假设创建了一个问题,问题中的sql如下:
select from customer_group_info where cgp_id = '2589bd22-c719-4e01-b9bf-2144beacadca'
1
根据cgp_id去查找记录,但是cgp_id是固定的,如果每次查询都要修改问题中的sql去改变值的话,那岂不是跟直接写sql没差,这时候就可以用变量替换,把cgp_id改成变量,然后直接输入查询值,改成如下格式的sql:
select from customer_group_info where cgp_id = { {input_id}}
1
问题上方会多出一个文本框,在文本框中输入cgp_id就可以查询
动态sql片段
sql变量虽然解决了查询条件值不固定的问题,但是如果有些查询条件也是可选的,这该怎么解决呢,如下面的sql:
select
cgp_id as 客群编号,
user_name as 用户名,
cgp_type as 客群类型
from
customer_group_info
where user_name = 'apicloud1'
and
cgp_type = 2 -- 该条件为可选条件
1
2
3
4
5
6
7
8
9
那就可根据条件来动态拼sql,改成如下形式:
select
cgp_id as 客群编号,
user_name as 用户名
【【 ,{ {input_type}} as 客群类型】】
from
customer_group_info
where user_name = { {input_user}}
【【and cgp_type = { {input_type}}】】
1
2
3
4
5
6
7
8
当不输入cgp_type时,查询出所有客群类型
当指定cgp_type时,查询出指定客群类型
以上为数据分析人员的数据分析操作,下面来说一下管理员角色的管理功能
管理员操作
添加数据库
点击设置,切换为管理员,进入管理员页面
选择 数据库 --> 添加数据库
填写数据库信息, 填写完成后保存即可
后续也可以通过该步骤选择已有数据库变更信息
连接oracle
metabase的默认数据源连接里面是没有oracle选项的,如果要连接oracle,需要单独配置
首先去oracle官网下载ojdbc驱动:
放到/metabase/plugins目录下,重启metabase即可
成员管理
邀请新成员
可以在 管理员页面 --》人员 --》 邀请其他人 邀请新用户,并分配用户组,邀请初始密码随机生成
权限配置
权限管理主要分为数据权限和文件夹权限两类,数据权限只访问数据库与表记录的权限,文件夹权限指访问集合的权限
数据权限
数据权限管理页面如下图所示,其中纵轴为所有的数据库,横轴为所有用户组
权限类型如下:
允许访问数据
没有权限: 无法访问整个数据库
部分权限:可访问指定表
授予不受限制的访问权限:可访问整个数据库
sql查询
没有权限: 无法在终端写原生sql
写原始查询语句: 可写sql
文件夹权限
其管理页面如下,纵轴为所有集合,横轴为所有用户组
权限类型如下:
集合权限
没有权限
查看集合
修改集合
邮箱配置
配置邮箱后,metabase可定时将指定的集合的分析结果推送至关注人邮箱,就不用主动登录metabase去查看
邮箱配置流程如下:
管理员页面 --》设置 --》 邮箱,填写邮件服务器信息与发送者邮箱
配置好后点击 ”发送测试邮件“,如果管理员邮箱中能收到如下测试邮件,说明邮箱配置成功
定时任务
邮箱配置完成之后,就可以配置定时任务来定时推送结果,将上面创建的三个问题的结果推送给对应邮箱,步骤如下:
回到首页,点击”+“添加新的定时任务
选择集合中的问题
设置定时任务和接收者邮箱,这里要注意你metabase设定的时区对不对,然后就能定时推送分析报告了
收到邮件如下:
------------恢复内容开始------------
文章目录
简介
安装
初始配置
数据分析
简单查询
创建场景
创建集合和仪表盘
自定义查询
原生查询
sql变量
动态sql片段
管理员操作
添加数据库
连接oracle
成员管理
邀请新成员
权限配置
数据权限
文件夹权限
邮箱配置
定时任务
简介
Metabase是一个免费的BI分析工具,可以帮助你把数据库中的数据更好的呈现给更多人,通过建立一个”查询“来提炼数据,再以图形化的方式做展示。上手简单,操作门槛低,即使不会sql语句也能使用。同时工具轻量、安装依赖的环境简单、配置简单清楚,只需一个jar包和一条命令就能完成安装
安装
Metabase的安装非常简单,只需将jar包下载下来后(下载地址),放在有java环境的机子上,通过java -jar命令启动即可,启动命令:
java -jar metabase.jar
1
这里需要注意的是metabase自带的H2数据库相对较弱,最好替换成其他数据源,比如MySQL等,这里可以参考我的另一篇文章:《metabase默认应用数据源H2变更为MySQL及历史数据迁移》
初始配置
启动后metabase默认端口为3000,如果要变更端口,可添加环境变量MB_JETTY_PORT来指定端口
,假设metabase为本地启动,浏览器访问网址:即可进入初始化界面
按提示一步步填写相关信息即可,注意第一个创建的账户默认即为管理员账户
等待初始化之后,进入首页即可看到配置数据库下的所有表
数据分析
接下来就可以正式使用了,右上角各功能如下:
下面就以具体场景为例,分别解释各项功能,点击创建问题 --》简单查询,先从简单的开始,走一遍整体流程
简单查询
假设我要对一张名为customer_group_info的客户群表做多个维度的分析,表结构与测试记录如下:
需求场景如下:
根据status状态字段做聚合,查看各个状态下的客群数
根据insert_time创建时间字段对客群做趋势分析
筛选出cgp_type客群类型为3的客群
创建场景
场景1:
1) 右上角选聚合,聚合条件为总行数,分组条件为status,聚合结果如下:
2) 为了便于观察,我们以图表形式显示,选择右下角“可视化”,选择图表类型
3)保存该问题,由于目前还没新建集合,先默认保存在“分析下”
场景2,3类似,就不再赘述
场景2:
场景3:
以上三个问题创建完毕,目前都保存在“分析”下,为了便于分类管理,下面//代码效果参考:http://www.jhylw.com.cn/580321209.html
就新建一个集合,把以上问题归类创建集合和仪表盘
回到首页,进入“分析”,新建名为“客群分析”的集合,然后把问题移到该集合下
目前虽然已经归类到一个集合下了,但是查看还是很不方便,还是要每个问题分别点进去才能看到,下面就开始建一个仪表盘,把这三个问题整合到同一个仪表盘下,点右上角“+”号,选择新仪表盘,放到“客群分析”集合下
然后在仪表盘中把三个问题添加进去即可
这样,后续对这三个场景的数据分析,就可以直接在该仪表盘中查看了
自定义查询
自定义查询相较于简单查询,支持更高级的操作,如多表关联,表与创建的问题之间的关联等,但整体操作还是跟简单查询类似,这里就不再重复了
原生查询
原生查询即直接写sql查询,但是前提是该用户必须有s