【阅读原文】戳:AI模型推理服务在Knative中最佳配置实践
【作者:李鹏、尹航】Knative和AI结合提供了快速部署、高弹性和低成本的技术优势,对于一些需要频繁变动计算资源的AI应用,如模型推理等尤其明显。那么在Knative上部署AI模型推理时可以遵循这些最佳实践,以提升AI推理服务能力和GPU资源利用率。

模型服务部署
加速模型部署
为了保证Knative Serving部署的AI模型推理服务实现快速的扩缩容,实现AI模型推理服务的最佳实践是避免将AI模型打包到容器镜像中。当AI模型和容器镜像打包在一起时,容器的大小会显著地增大,进而拖慢容器的部署速。此外,当AI模型被打包在容器内时,AI模型的版本将与容器镜像版本绑定,使得版本控制更加复杂。
为避免上述问题,应该将AI模型的数据加载到对象存储OSS、文件存储NAS等外部介质中,并通过存储声明PVC挂载到Knative服务Pod中。同时,可使用分布式数据集编排和加速引擎Fluid来加速对AI模型的读取和加载过程(参考[1]JindoFS加速OSS文件访问、[2]EFC加速NAS或CPFS文件访问等相关文档),实现大模型的秒级加载。
例如,当您将AI模型存放在对象存储OSS时,可以使用Dataset来声明OSS上的数据集,并使用JindoRuntime执行缓存任务(需要在集群中安装ack-fluid组件)。
apiVersion: v1 kind: Secret metadata: name: access-key stringData: fs.oss.accessKeyId: your_ak_id # 请替换为访问OSS所用的access key ID fs.oss.accessKeySecret: your_ak_skrt # 请替换为访问OSS所用的access key secret --- apiVersion: data.fluid.io/v1alpha1 kind: Dataset metadata: name: oss-data spec: mounts: - mountPoint: "oss://{Bucket}/{path-to-model}" # 请替换为模型所在的OSS Bucket以及存储路径 name: xxx path: "{path-to-model}" # 根据程序加载模型的路径,替换该处的模型存储路径 options: fs.oss.endpoint: "oss-cn-beijing.aliyuncs.com" # 请替换为实际的OSS endpoint地址。 encryptOptions: - name: fs.oss.accessKeyId valueFrom: secretKeyRef: name: access-key key: fs.oss.accessKeyId - name: fs.oss.accessKeySecret valueFrom: secretKeyRef: name: access-key key: fs.oss.accessKeySecret accessModes: - ReadOnlyMany --- apiVersion: data.fluid.io/v1alpha1 kind: JindoRuntime metadata: name: oss-data spec: replicas: 2 tieredstore: levels: - mediumtype: SSD volumeType: emptyDir path: /mnt/ssd0/cache quota: 100Gi high: "0.95" low: "0.7" fuse: properties: fs.jindofsx.data.cache.enable: "true" args: - -okernel_cache - -oro - -oattr_timeout=7200 - -oentry_timeout=7200 - -ometrics_port=9089 cleanPolicy: OnDemand
声明Dataset和JindoRuntime后,会自动创建同名PVC,将PVC挂在到Knative服务中即可实现加速效果。
apiVersion: serving.knative.dev/v1 kind: Service metadata: name: sd-backend spec: template: spec: containers: - image: <your-image> name: image-name ports: - containerPort: xxx protocol: TCP volumeMounts: - mountPath: /data/models # 根据程序加载模型的路径,替换moutPath name: data-volume volumes: - name: data-volume persistentVolumeClaim: claimName: oss-data # 挂载和Dataset同名的PVC
除AI模型本身之外,也需要考虑容器本身尺寸对Knative服务的影响。运行AI模型的服务容器往往需要打包CUDA、pytorch-gpu等一系列依赖,使其容器尺寸比起普通容器有显著增加。当使用ECI Pod部署Knative AI模型推理服务时,建议使用ImageCache来加速镜像的拉取过程,ImageCache能够为ECI Pod提供镜像缓存功能,通过提前缓存镜像来显著加速镜像拉取时间、实现秒级镜像拉取,参考[3]使用ImageCache加速创建Pod。
apiVersion: eci.alibabacloud.com/v1 kind: ImageCache metadata: name: imagecache-ai-model annotations: k8s.aliyun.com/eci-image-cache: "true" #开启镜像缓存复用。 spec: images: - <your-image> imageCacheSize: 25 #镜像缓存大小,单位GiB retentionDays: 7 # 缓存保留时间
优雅关闭容器
为了确保正在进行的请求不会突然终止,容器应在收到 SIGTERM信号时启动正常关闭。
•收到SIGTERM信号后,如果应用程序使用HTTP探测,则设置为非就绪状态。这可以防止将新的请求路由到正在关闭的容器。
•在关闭过程中,Knative的queue-proxy可能仍在将请求路由到容器。为了确保所有请求在容器终止之前完成,timeoutSeconds参数应该是最长预期处理请求响应时间的1.2 倍。
例如,如果最长的请求响应时间需要5秒,建议将timeoutSeconds参数设置为6秒:
apiVersion: serving.knative.dev/v1 kind: Service metadata: name: helloworld-go namespace: default spec: template: spec: timeoutSeconds: 6
探针配置
Liveness和readiness探针在维护Knative服务的健康和可用性方面发挥着至关重要的作用。需要注意的是,Knative探测与Kubernetes探测不同。原因之一是Knative试图最大限度地减少冷启动时间,因此探测的间隔比Kubernetes的间隔要更积极。

•用户可以选择在Knative Service CR中定义Readiness和/或Liveness探针。
•Liveness探测由Kubelet直接针对相应的容器执行。
•Readiness就绪探针由Knative重写并由队列代理容器执行。
•Knative从某些地方(例如Activator和Queue-Proxy)进行探测,以确保整个网络链路已配置并准备就绪。与普通Kubernetes相比,Knative使用更快(称为积极探测)的探测间隔来缩短Pod已经启动并运行。
•当用户未定义探针时,Knative将为主用户容器定义默认的就绪探针。它将检查Knative服务的流量端口上的TCP Socket。
•Knative还为Queue-Proxy容器本身定义一个Readiness探针。一旦Queue-Proxy容器探针返回成功响应,Knative将认为Pod 健康并准备好提供流量。
Liveness存活探针
存活探针用于监视容器的健康状况。如果容器处于失败或卡住状态,存活探针将重新启动它。
Readiness就绪探针
就绪探针对于自动弹性尤其重要。
•在加载所有组件并且容器完全准备好之前,TCP探针不应启动监听端口。
•在端点能够处理请求之前,HTTP探测不应将服务标记为就绪。
•调整探测间隔periodSeconds时,请保持较短的间隔。理想情况下,该时间小于默认值10秒。
apiVersion: serving.knative.dev/v1 kind: Service metadata: name: runtime namespace: default spec: template: spec: containers: - name: first-container image: <your-image> ports: - containerPort: 8080 readinessProbe: httpGet: port: 8080 # you can also check on a different port than the containerPort (traffic-port) path: "/health" livenessProbe: tcpSocket: port: 8080
自动弹性扩缩容
基于请求自动弹性扩缩容是Knative中关键能力。默认的自动伸缩指标类型是concurrency,建议基于GPU的服务使用该类型。
apiVersion: serving.knative.dev/v1 kind: Service metadata: name: helloworld spec: template: metadata: annotations: autoscaling.knative.dev/metric: "concurrency"
在对自动弹性进行任何调整之前,首先定义优化目标,例如减少延迟、最大限度地降低成本或适应流量峰值。然后,观测Pod在预期场景下启动所需的时间。例如,部署单个Pod可能与同时部署多个Pod具有不同的平均启动时间。这些指标为自动弹性配置提供了基准配置。
扩缩容模式
自动弹性有两种模式:稳定模式和恐慌模式,每种模式都有单独的窗口。稳定模式用于一般操作,而恐慌模式默认情况下具有更短的窗口,用于在流量突发时快速扩容Pod。
稳定模式窗口
一般来说,为了保持稳定的扩缩容行为,稳定窗口应该比平均Pod启动时间长,推荐设置为平均时间的2倍。
apiVersion: serving.knative.dev/v1 kind: Service metadata: name: helloworld spec: template: metadata: annotations: autoscaling.knative.dev/window: "50s"
恐慌模式窗口
恐慌窗口是稳定窗口的百分比。其主要功能是管理突发的、意外的流量高峰。但是,设置此参数需要谨慎,因为它很容易导致过度扩容,特别是当Pod启动时间较长时。
•例如,如果稳定窗口设置为30秒,恐慌窗口配置为10%,则系统将使用3秒的数据来判断是否进入恐慌缩放模式。如果 Pod 通常需要30秒才能启动,则系统可能会在新Pod仍在上线时继续扩容,从而可能导致过度扩容Pod。
•在调整其他参数并且缩放行为稳定之前,不要微调恐慌窗口。当考虑恐慌窗口值短于或等于Pod启动时间时,这一点尤其重要。如果稳定窗口是平均Pod启动时间的两倍,则从50%的恐慌窗口值开始,以平衡常态和突发流量模式。
apiVersion: serving.knative.dev/v1 kind: Service metadata: name: helloworld namespace: default spec: template: metadata: annotations: autoscaling.knative.dev/panic-window-percentage: "10.0"
恐慌模式阈值是传入流量与目标容量的比率。根据流量的峰值和可接受的延迟水平来调整此值。初始值为200%或更高,直到缩放行为稳定。服务运行一段时间之后,可以考虑进一步调整。
apiVersion: serving.knative.dev/v1 kind: Service metadata: name: helloworld namespace: default spec: template: metadata: annotations: autoscaling.knative.dev/panic-threshold-percentage: "200.0"
弹性速率
扩容和缩容速率控制弹性以响应流量模式的速度。虽然默认情况下这些速率通常配置满足需求,但在某些特定情况下可能需要进行调整。在调整任一速率之前需要观察当前行为,并且对这些速率参数的任何更改都应首先在测试环境中进行测试。如果遇到扩缩容问题,请检查其它扩缩容参数,如稳定窗口和恐慌窗口,因为它们经常与扩容和缩容速率相互作用。
扩容速率
除非遇到特定问题,否则扩容速率通常不需要修改。例如,如果同时扩容多个Pod可能导致启动时间增加(资源准备等),则可能需要调整扩容速率。如果观察到频繁扩缩,则其它参数(例如稳定窗口或恐慌窗口)可能也需要调整。
apiVersion: v1 kind: ConfigMap metadata: name: config-autoscaler namespace: knative-serving data: max-scale-up-rate: "500.0"
缩容速率
缩容速率最初应设置为平均Pod启动时间或更长。默认值通常足以满足大多数使用情况,但如果优先考虑成本优化,可以考虑调大速率,以便在流量高峰后更快地缩容。如果某项服务遇到流量高峰,并且目标是降低成本,可以考虑更快的缩容设置。
缩容率是一个乘数;例如,值N/2将允许系统在弹性周期结束时将Pod数量缩减至当前数量的一半。对于Pod数量较少的服务,较低的缩容率有助于保持Pod数量更加平滑,降低频繁扩缩,从而提高系统稳定性。
apiVersion: v1 kind: ConfigMap metadata: name: config-autoscaler namespace: knative-serving data: max-scale-down-rate: "4.0"
扩缩容边界
这些参数与业务的规模和可用资源高度相关。
下限
autoscaling.knative.dev/min-scale控制每个修订版应具有的最小副本数。Knative将尝试保持不少于此数量的副本。对于很少使用且不应缩容到零的服务,设置值1可以保证容量始终可用。预计会有大量突发流量的服务时应将其设置为高于1。
apiVersion: serving.knative.dev/v1 kind: Service metadata: name: helloworld namespace: default spec: template: metadata: annotations: autoscaling.knative.dev/min-scale: "1"
上限
autoscaling.knative.dev/max-scale不应超过可用资源。使用此参数主要限制最大资源成本。
apiVersion: serving.knative.dev/v1 kind: Service metadata: name: helloworld namespace: default spec: template: metadata: annotations: autoscaling.knative.dev/max-scale: "3"
初始扩容数
配置初始Pod规模,以便新版本可以完全处理现有流量。推荐的配置值是现有Pod数量的1.2倍。
apiVersion: serving.knative.dev/v1 kind: Service metadata: name: helloworld-go namespace: default spec: template: metadata: annotations: autoscaling.knative.dev/initial-scale: "5"
利用缩容到0的能力
Knative的突出功能之一是能够在服务不使用时将Pod缩容至零。
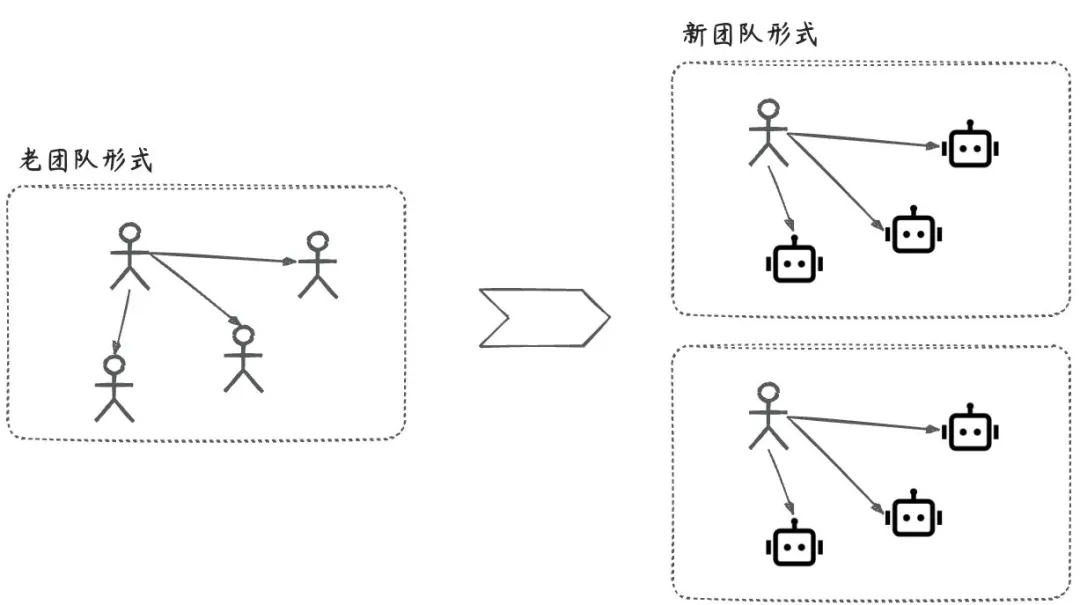
这对于管理多个模型的用户特别有用。我们建议将每个不同的模型部署各自的Knative服务,而不是在单个服务中实现复杂的逻辑。
•借助Knative的缩容到0的功能,可做到一段时间未访问的模型不会产生额外成本。
•当客户端第一次访问模型服务时,Knative可以从0开始扩容。
并发参数配置
正确的并发配置对于优化Knative服务至关重要。这些参数对应用程序性能产生显着影响。
并发硬限制
containerConcurrency是硬并发限制——单个容器实例可以处理的最大并发请求数。
需要准确评估容器在不降低性能的情况下,可以同时处理的最大请求数。对于GPU密集型任务,如果对其并发能力不确定,可以将containerConcurrency设置为1。
apiVersion: serving.knative.dev/v1 kind: Service metadata: name: helloworld spec: template: spec: containerConcurrency: 1
并发软限制
autoscaling.knative.dev/target设置软并发目标——每个容器所需的并发请求数。
在大多数情况下,target值应与containerConcurrency值匹配。这使得配置更易于理解和管理。如将 containerConcurrency设置为1的GPU密集型任务也应将 target设置为1。
apiVersion: serving.knative.dev/v1 kind: Service metadata: name: helloworld spec: template: metadata: annotations: autoscaling.knative.dev/target: 1
软限制是有针对性的限制,而不是严格执行的界限。在某些情况下,特别是请求突然爆发时,可能会超过该值。
硬限制是强制上限。如果并发达到硬限制,多余的请求将被缓冲,并且必须等待,直到有足够的可用资源来执行请求。
建议仅当应用程序有明确的用例时,才建议使用硬限制配置。指定较低的硬限制可能会对应用程序的吞吐量和延迟产生负面影响,并可能导致额外的冷启动。
目标使用率
最佳实践是调整目标利用率而不是修改target。这提供了一种更直观的方式来管理并发级别。
将autoscaling.knative.dev/target-utilization-percentage调整为尽可能接近100%,以实现最高效的完整并发处理。
•90-95%是比较推荐配置的区间范围。不过可能需要进行实验测试来优化该值。
•较低的百分比(<100%) 会增加Pod必须等待更长时间才能达到其并发上限。但这也提供了提前准备资源量来处理流量高峰的益处。
•如果Pod启动时间很快,则可以使用更高的百分比。否则,调整目标以找到弹性延迟和并发处理之间的平衡。
apiVersion: serving.knative.dev/v1 kind: Service metadata: name: helloworld spec: template: metadata: annotations: autoscaling.knative.dev/target-utilization-percentage: "90"
基于多版本设置合理的灰度节奏
Knative优势之一是可以确保不间断的服务可用性,特别是在推出新版本时。当部署新代码或对服务进行更改时,Knative会保持旧版本运行,直到新版本准备就绪。
•可以通过流量百分比阈值进行配置。流量百分比是一个关键参数,它决定Knative何时应将流量从旧版本切换到新版本。该百分比可以低至10%,也可以高达100%。
•在Pod可用资源有限的情况下进行大规模操作时,控制旧版本的缩容速度尤其重要。如果某个服务在500个Pod上运行,而只有300个额外的Pod可用,那么设置过大的流量百分比可能会导致服务部分不可用。
ECS和ECI资源混用
如果希望常态情况下使用ECS资源,突发流量使用ECI,那么可以结合ResourcePolicy来实现。在常态下通过ECS资源承载流量,突发流量则新扩容出来的资源使用ECI。

apiVersion: scheduling.alibabacloud.com/v1alpha1 kind: ResourcePolicy metadata: name: xxx namespace: xxx spec: selector: serving.knative.dev/service: helloworld-go ## 此处指定Knative Service 名称即可 strategy: prefer units: - resource: ecs max: 10 nodeSelector: key2: value2 - resource: ecs nodeSelector: key3: value3 - resource: eci
这里会根据先后顺序Knative Pod优先使用ecs进行扩容,当超过了缩设置的max pod数或者ECS资源不足时,会调度到ECI创建Pod。
缩容时,会根据调度节点的逆序,优先缩容在ECI上的Pod。
共享GPU调度
结合ACK共享GPU调度能力,Knative模型服务可以充分利用cGPU显存隔离能力,高效利用GPU设备资源。
在Knative使用共享GPU只需要在Knative Service中limits设置aliyun.com/gpu-mem参数即可,参考示例如下:
apiVersion: serving.knative.dev/v1 kind: Service metadata: name: helloworld-go namespace: default spec: template: spec: containerConcurrency: 1 containers: - image: registry-vpc.cn-hangzhou.aliyuncs.com/demo-test/test:helloworld-go name: user-container ports: - containerPort: 6666 name: http1 protocol: TCP resources: limits: aliyun.com/gpu-mem: "3"
可观测性能力
开启Queue-Proxy容器日志
通过Queue-Proxy容器日志,我们可以查看请求是否成功,以便在失败的情况下快速定位问题原因。开启方式如下:
apiVersion: v1 kind: ConfigMap metadata: name: config-observability namespace: knative-serving data: logging.enable-request-log: "true" logging.request-log-template: '{"httpRequest": {"requestMethod": "{{.Request.Method}}", "requestUrl": "{{js .Request.RequestURI}}", "requestSize": "{{.Request.ContentLength}}", "status": {{.Response.Code}}, "responseSize": "{{.Response.Size}}", "userAgent": "{{js .Request.UserAgent}}", "remoteIp": "{{js .Request.RemoteAddr}}", "serverIp": "{{.Revision.PodIP}}", "referer": "{{js .Request.Referer}}", "latency": "{{.Response.Latency}}s", "revisionName": "{{.Revision.Name}}", "protocol": "{{.Request.Proto}}"}, "traceId": "{{index .Request.Header "X-B3-Traceid"}}"}'
Queue-Proxy容器日志示例:
{"httpRequest": {"requestMethod": "GET", "requestUrl": "/fr", "requestSize": "0", "status": 502, "responseSize": "17", "userAgent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36", "remoteIp": "10.111.162.1:40502", "serverIp": "10.111.172.168", "referer": "", "latency": "9.998150996s", "revisionName": "demo-00003", "protocol": "HTTP/1.1"}, "traceId": "[]"}
开启Prometheus大盘
Knative提供了开箱即用的Prometheus大盘,可以查看请求数、请求成功率、Pod扩缩容趋势、RT请求响应延迟、并发数以及资源使用率等。

基于这些大盘信息,在测试阶段,可以评估出最佳模型弹性指标配置。如基于可接受的RT响应延迟时间,单Pod并发最大可以达到多少。然后不断的进行调整并发指标、弹性指标配置等。
小结
Serverless架构和人工智能(AI)的结合可以带来一系列优势,特别是对于需要高弹性、快速持续迭代以及低成本的场景。作为CNCF最受欢迎的开源Serverless 应用框架,Knative恰好提供了这些能力。也欢迎有兴趣的开发者(扫描下方二维码)加入Knative钉钉技术交流群:

相关链接:
[1] JindoFS加速OSS文件访问
[2] EFC加速NAS或CPFS文件访问
[3] 使用ImageCache加速创建Pod
我们是阿里巴巴云计算和大数据技术幕后的核心技术输出者。
获取关于我们的更多信息~