
问题一:用官网flink cdc 3.0 进行mysql 到 starrocks的测试,报错了什么原因呢?
用官网flink cdc 3.0 进行mysql 到 starrocks的测试,报错了什么原因呢?https://ververica.github.io/flink-cdc-connectors/release-3.0/content/%E5%BF%AB%E9%80%9F%E4%B8%8A%E6%89%8B/mysql-starrocks-pipeline-tutorial-zh.html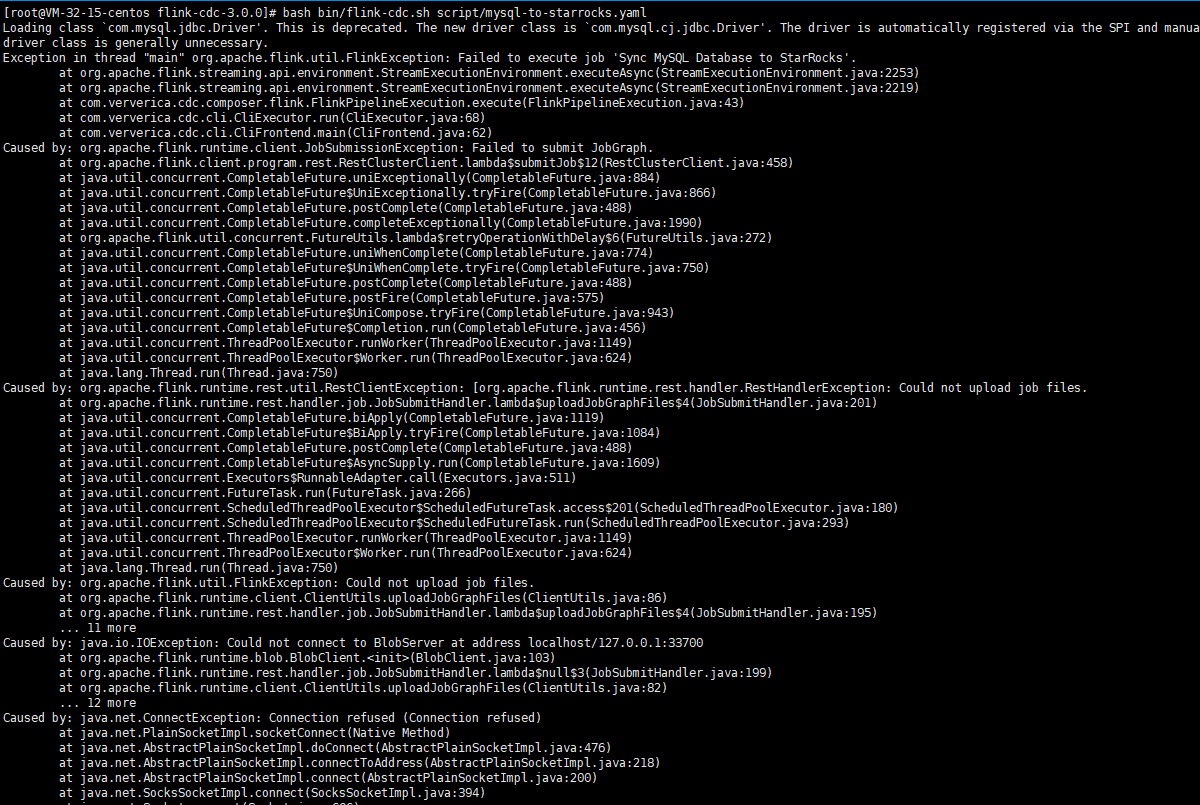
参考回答:
从你提供的信息和截图来看,报错信息是 "UnknownHostException: xxx",这表明 Flink CDC 在尝试连接 StarRocks 时无法解析目标主机的 IP 地址。以下是一些可能的原因和解决方法:
- 网络问题:
- 确保运行 Flink CDC 的机器可以访问到 StarRocks 集群所在的网络。
- 检查 StarRocks 集群的主机名或 IP 地址是否正确配置在 Flink CDC 的连接参数中。
- 如果 StarRocks 集群使用内网地址,确保 Flink CDC 运行环境能够通过内网访问。
- DNS 解析问题:
- 如果你在使用主机名而非 IP 地址连接 StarRocks,检查 DNS 解析是否正常。你可以尝试在运行 Flink CDC 的机器上使用
ping或nslookup命令来测试能否正确解析 StarRocks 主机名。
- 防火墙或安全组设置:
- 确保 StarRocks 集群的防火墙或安全组规则允许来自 Flink CDC 运行环境的连接请求。
- 如果有必要,打开相应的端口(通常是 StarRocks 的 JDBC 连接端口)以允许入站连接。
- StarRocks 配置问题:
- 确认 StarRocks 集群已经正确配置并正在运行。
- 检查 StarRocks 的连接参数,包括用户名、密码、数据库名称等是否正确。
- Flink CDC 配置问题:
- 确保你在 Flink CDC 的配置中正确指定了 StarRocks 的连接参数,包括主机名或 IP 地址、端口、用户名、密码等。
- 依赖库问题:
- 确保你使用的 Flink CDC 版本与 StarRocks 的版本兼容,并且已经包含了所有必要的依赖库。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/580757
问题二:Flink CDC中flink-mysql-cdc3.0报的错跟上面的有点类似?
Flink CDC中flink-mysql-cdc3.0报的错跟上面的有点类似? 

参考回答:
dbz开头的包都不需要,cdc里面有封装,会冲突
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/580753
问题三:Flink CDC读取kafka中的数据打印测试,kafka中的数据过期了?
Flink CDC读取kafka中的数据打印测试,之前代码打印测试正常输出,现在,kafka中的数据过期了?重新推送数据进入kafka中,再次打印输出测试,发现没有输出(日志告警,但是没有error。
2023-12-15 16:01:20 DEBUG (org.apache.flink.runtime.util.HadoopUtils:getHadoopConfiguration) - Searching Hadoop configuration files in HADOOP_HOME: D:\bigdate\hadoop\winutils-master\hadoop-3.0.0
2023-12-15 16:01:20 WARN (org.apache.flink.runtime.util.HadoopUtils:getHadoopConfiguration) - Could not find Hadoop configuration via any of the supported methods (Flink configuration, environment variables).
参考回答:
这个问题可能是由于以下几个原因导致的:
- Kafka数据过期:
- Kafka默认配置中,数据保留时间是有限的。如果你的数据超过了这个保留时间,就会被自动删除。你可以检查Kafka的broker配置中的
log.retention.hours或者log.retention.bytes参数,以确定数据的保留策略和期限。
- Flink CDC任务配置问题:
- 确保你的Flink CDC任务配置正确地指向了包含新数据的Kafka主题和分区。
- 检查Flink CDC任务的消费偏移量设置,确保它从最新的数据开始读取,而不是从旧的或者已消费的数据开始。
- Hadoop配置问题:
- 虽然日志中显示了关于Hadoop配置的警告信息,但这可能不是直接导致你无法从Kafka中读取数据的原因。
- 如果你的Flink CDC任务依赖于Hadoop相关的组件或者功能(如HDFS、HBase等),那么确实需要正确的Hadoop配置。但是,如果只是从Kafka中读取数据,通常不需要Hadoop配置。
为了解决这个问题,你可以尝试以下步骤:
- 确认Kafka中是否有新的数据,并且数据没有超过保留期限。
- 检查并修改Flink CDC任务的配置,确保它指向正确的Kafka主题和分区,并从最新的数据开始消费。
- 如果你的Flink CDC任务依赖于Hadoop相关组件,确保Hadoop配置正确并且可以访问。
- 查看Flink CDC任务的日志和监控信息,查找其他可能的错误或者警告信息,以便定位问题的具体原因。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/580749
问题四:Flink CDC这个问题大家遇到过吗?
Flink CDC这个问题大家遇到过吗? 
但是我同一个jar包 在其他服务器跑起来了 ,这个怎么解决呢?
参考回答:
依赖冲突,和集群的冲突,把这个依赖打在包里
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/580742
问题五:Flink CDC消费kafka中的数据,之前能正常消费。现在报这种,有遇到过么?
Flink CDC消费kafka中的数据,之前能正常消费。现在报这种,大佬们有遇到过么? 
参考回答:
看着是你的kafka集群配置不对哦
关于本问题的更多回答可点击原文查看:



