
1、Elasticsearch 版本冲突复现
先让大家直观的看到 Elasticsearch 文档版本冲突。
1.1 场景1:create 场景
DELETE my-index-000001 # 执行创建并写入 PUT my-index-000001/_create/1 { "@timestamp": "2099-11-15T13:12:00", "message": "GET /search HTTP/1.1 200 1070000", "user": { "id": "kimchy" } } # 再次执行会报版本冲突错误。 # 报错信息:[1]: version conflict, document already exists (current version [1]) PUT my-index-000001/_create/1 { "@timestamp": "2099-11-15T13:12:00", "message": "GET /search HTTP/1.1 200 1070000", "user": { "id": "kimchy" } }

1.2 场景2:批量更新场景模拟
模拟脚本1:循环写入数据 index.sh。

模拟脚本2:循环update_by_query 批量更新数据 update.sh。

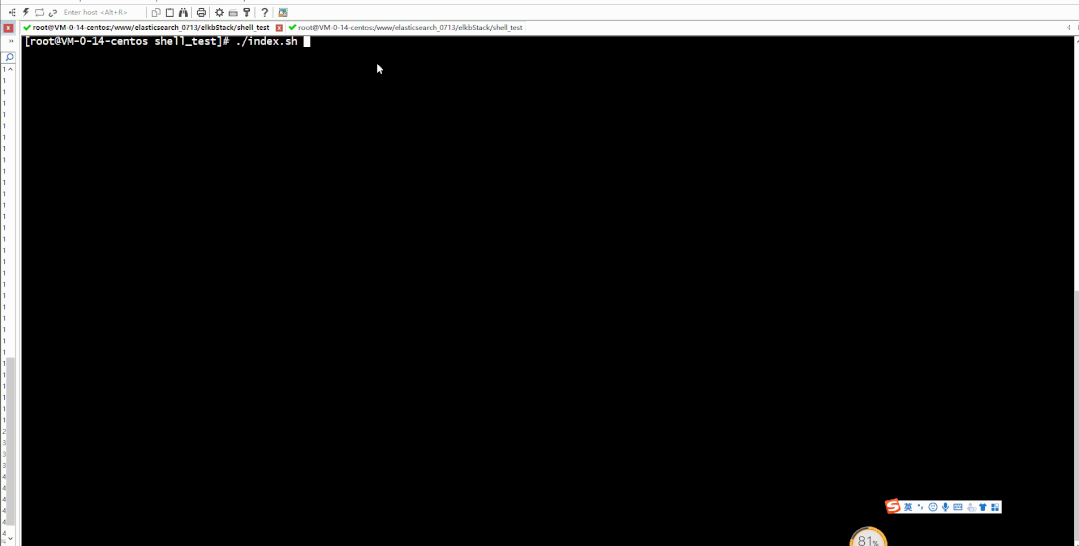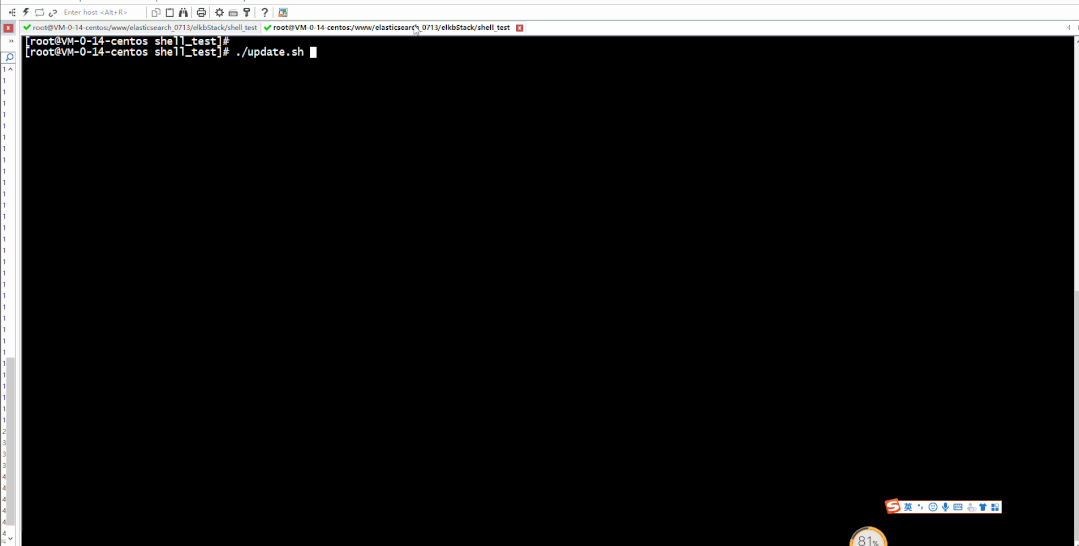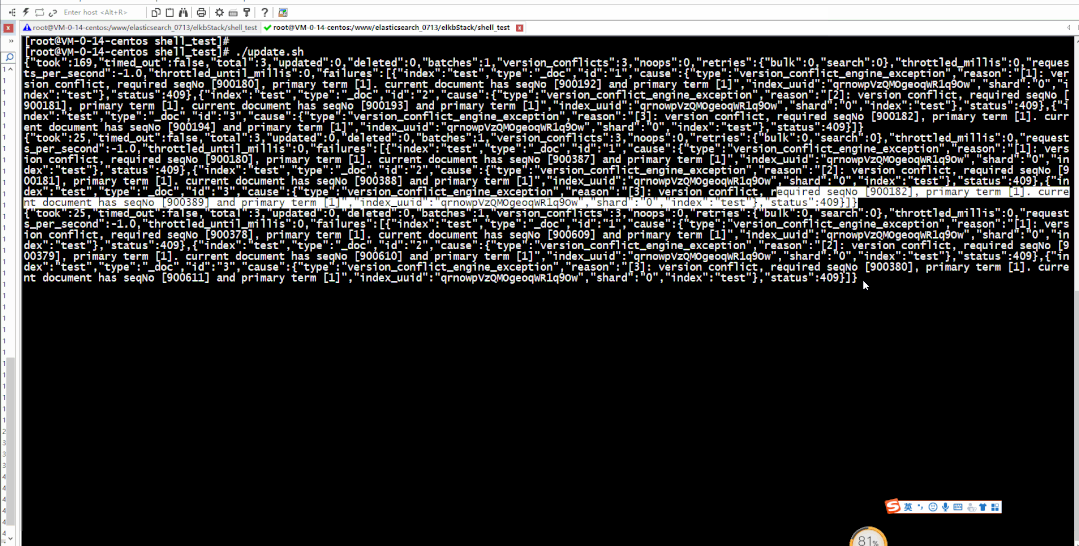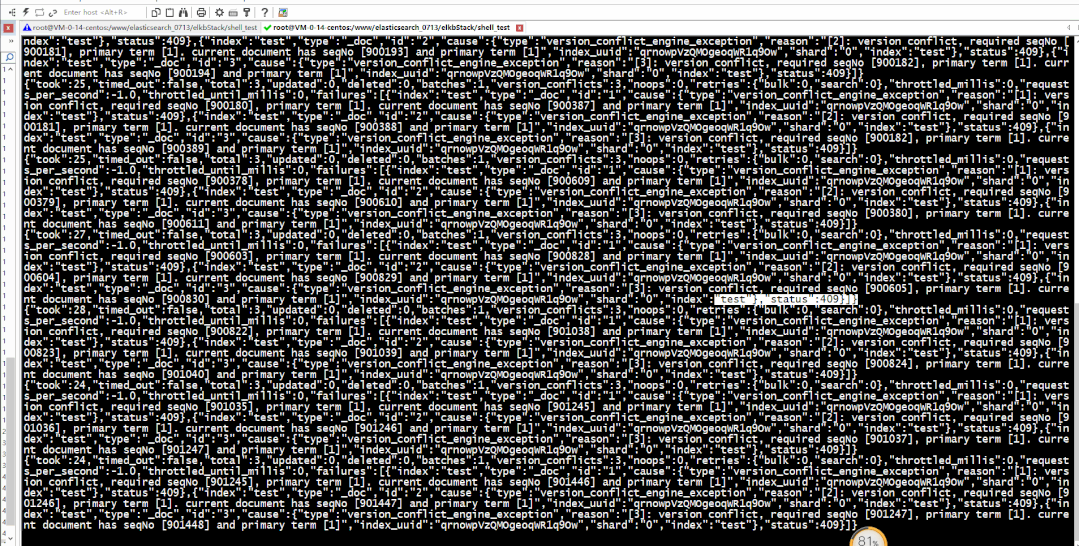
由于:写入脚本 index.sh 比更新脚本 update.sh (执行一次,休眠1秒)执行要快,所以更新获取的版本较写入的最新版本要低,会导致版本冲突如下图所示:

1.3 场景3:批量删除场景模拟
写入脚本 index.sh 不变。
删除脚本 delete.sh 如下:

和更新原因一致,由于:写入脚本 index.sh 比删除脚本 delete.sh (执行一次,休眠1秒)执行要快,所以删除获取的版本较写入的最新版本要低,会导致版本冲突如下图所示:

2、Elasticsearch 文档版本定义
执行:
GET test/_doc/1
召回结果如下:

这里的 version 代表文档的版本。
- 当我们在 Elasticsearch 中创建一个新文档时,它会为该文档分配一个_version: 1。
- 当我们对该文档进行任何后续更新(更新 update、索引 index 或删除 delete)时,_version都会增加 1。
一句话:Elasticsearch 使用_version来鉴别文档是否已更改。
3、Elasticsearch 文档版本产生背景
试想一下,如果没有文档版本?当有并发访问会怎么办?
前置条件:Elasticsearch 从写入到被检索的时间间隔是由刷新频率 refresh_interval 设定的,该值可以更新,但默认最快是 1 秒。

如上图所示,假设我们有一个人们用来评价 T 恤设计的网站。网站很简单,仅列出了T恤设计,允许用户给T恤投票。如果顺序投票,没有并发请求,直接发起update更新没有问题。
但是,在999累计投票数后,碰巧小明同学和小红同学两位同时(并发)发起投票请求,这时候,如果没有版本控制,将导致最终结果不是预期的1001,而是1000。
所以,为了处理上述场景以及比上述更复杂的并发场景,Elasticsearch 亟需一个内置的文档版本控制系统。这就是 _version 的产生背景。
https://www.elastic.co/cn/blog/elasticsearch-versioning-support
4、常见的并发控制策略
并发控制可以简记为:“防止两个或多个用户同时编辑同一记录而导致最终结果和预期不一致”。
常见的并发控制策略:悲观锁、乐观锁。
4.1 悲观锁
悲观锁,又名:悲观并发控制,英文全称:"Pessimistic Concurrency Control",缩写“PCC”,是一种并发控制的方法。
- 悲观锁本质:在修改数据之前先锁定,再修改。
- 悲观锁优点:采用先锁定后修改的保守策略,为数据处理的安全提供了保证。
- 悲观锁缺点:加锁会有额外的开销,还会增加产生死锁的机会。
- 悲观锁应用场景:比较适合写入操作比较频繁的场景。
4.2 乐观锁
乐观锁,又名:乐观并发控制,英文全称:“Optimistic Concurrency Control”,缩写OCC”,也是一种并发控制的方法。
- 乐观锁本质:假设多用户并发的事务在处理时不会彼此互相影响,各事务能够在不产生锁的情况下处理各自影响的那部分数据。在提交数据更新之前,每个事务会先检查在该事务读取数据后,有没有其他事务又修改了该数据。如果其他事务有更新的话,正在提交的事务会进行回滚。
- 乐观锁优点:“胆子足够大,足够乐观”,直到提交的时候才去锁定,不会产生任何锁和死锁。
- 乐观锁缺点:并发写入会有问题,需要有冲突避免策略补救。
- 乐观锁应用场景:数据竞争(data race)不大、冲突较少的场景、比较适合读取操作比较频繁的场景,确保比其他并发控制方法(如悲观锁)更高的吞吐量。
这里要强调的是,Elasticsearch 采用的乐观锁的机制来处理并发问题。
Elasticsearch 乐观锁本质是:没有给数据加锁,而是基于 version 文档版本实现。每次更新或删除数据的时候,都需要对比版本号。
5、Elasticsearch 文档版本冲突的本质
一句话,Elasticsearch 文档冲突的本质——老版本覆盖掉了新版本。
6、如何解决或者避免 Elasticsearch 文档版本冲突?
6.1 external 外部控制版本号
“external”——我的理解就是“简政放权”,交由外部的数据库或者更确切的说,是写入的数据库或其他第三方库来做控制。
版本号可以设置为外部值(例如,如果在数据库中维护)。要启用此功能,version_type应设置为 external。
使用外部版本类型 external 时,系统会检查传递给索引请求的版本号是否大于当前存储文档的版本。
- 如果为真,也就是新版本大于已有版本,则文档将被索引并使用新的版本号。
- 如果提供的值小于或等于存储文档的版本号,则会发生版本冲突,索引操作将失败。
好处:不论何时,ES 中只有最新版本的数据,借助 external 相对有效的解决版本冲突问题。
实战一把:
如果没有 external,执行如下命令:
PUT my-index-000001/_doc/1?version=2 { "user": { "id": "elkbee" } }
报错如下:
{ "error" : { "root_cause" : [ { "type" : "action_request_validation_exception", "reason" : "Validation Failed: 1: internal versioning can not be used for optimistic concurrency control. Please use `if_seq_no` and `if_primary_term` instead;" } ], .......省略2行...... "status" : 400 }
啥意思呢?内部版本控制(internal)不能用于乐观锁,也就是直接使用 version 是不可以的。需要使用:if_seq_no 和 if_primary_term,它俩的用法,后文会有专门解读。
如果用 external,执行如下命令:
PUT my-index-000001/_doc/1?version=2&version_type=external { "user": { "id": "elkbee" } }
执行结果如下:
{ "_index" : "my-index-000001", "_type" : "_doc", "_id" : "1", "_version" : 2, "result" : "updated", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 1, "_primary_term" : 1 }
相比于之间没有加 external,加上 external 后,可以实现基于version的文档更新操作。
external_gt 和 external_gte的用法见官方文档,本文不展开,原理同 external。
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/docs-index_.html#index-versioning
6.2 通过if_seq_no 和 if_primary_term 唯一标识避免冲突
索引操作(Index,动词)是有条件的,并且只有在对文档的最后修改分配了由 if_seq_no 和 if_primary_term 参数指定的序列号和 primary term specified(翻译起来拗口,索性用英文)才执行。
如果检测到不匹配,该操作将产生一个 VersionConflictException 409 的状态码。
Step1:写入数据
DELETE products_001 PUT products_001/_doc/1567 { "product" : "r2d2", "details" : "A resourceful astromech droid" } # 查看ifseqno 和 ifprimaryterm GET products_001/_doc/1567
返回:
{ "_index" : "products_001", "_type" : "_doc", "_id" : "1567", "_version" : 1, "_seq_no" : 0, "_primary_term" : 1, "found" : true, "_source" : { "product" : "r2d2", "details" : "A resourceful astromech droid" } }
Step2:以这种方式更新,前提是先拿到 if_seq_no 和 if_primary_term
# 模拟数据打tag 过程 PUT products_001/_doc/1567?if_seq_no=0&if_primary_term=1 { "product": "r2d2", "details": "A resourceful astromech droid", "tags": [ "droid" ] } # 再获取数据 GET products_001/_doc/1567
返回:
{ "_index" : "products_001", "_type" : "_doc", "_id" : "1567", "_version" : 2, "_seq_no" : 1, "_primary_term" : 1, "found" : true, "_source" : { "product" : "r2d2", "details" : "A resourceful astromech droid", "tags" : [ "droid" ] } }
step2 更新数据的时候,是在 step1 的获取已写入文档的 if_seq_no=0 和 if_primary_term=1 基础上完成的。
这样能有效避免冲突。
6.3 批量更新和批量删除忽略冲突实现
如下是在开篇的基础上加了:conflicts=proceed。
conflicts 默认值是终止,而 proceed 代表继续。
POST test/_update_by_query?conflicts=proceed { "query": { "match": { "name": "update" } }, "script": { "source": "ctx._source['foo'] = '123ss'", "lang": "painless" } }
conflicts=proceed 的本质——告诉进程忽略冲突并继续更新其他文档。
开篇不会报 409 错误了,但依然会有版本冲突。但,某些企业级场景是可以用的。

同理,delete_by_query 参数及返回结果均和 update_by_query 一致。

扩展:单个更新 update (区别于批量更新:update_by_query)有 retry_on_conflict 参数,可以设置冲突后重试次数。
7、关于频繁更新带来的性能问题
正如文章开篇演示的,并发更新或者并发删除可能会导致版本冲突。
除了并发性和正确性之外,请注意,非常频繁地更新文档可能会导致性能下降。
如果更新了尚未写入段(segment)的文档,将会导致刷新操作。而刷新频率越小(企业级咨询我见过设置小于1s的,不推荐),势必会导致写入低效。
更多探讨推荐阅读:
https://discuss.elastic.co/t/handling-conflicts/135240/2
8、小结
从实际问题抽象出模拟脚本,让大家看到文档版本冲突是如何产生的。而后,定义了版本冲突并指出了其产生的背景。
接着,详细讲解了解决冲突的两种机制:乐观锁、悲观锁。探讨、验证了解决文档版本冲突的几种方案。
你有没有遇到过本文提及的问题,如何解决的呢?欢迎留言交流。
参考
[2] https://learnku.com/articles/43867
[3] https://www.elastic.co/guide/en/elasticsearch/reference/current/optimistic-concurrency-control.html
[5] https://www.elastic.co/guide/en/elasticsearch/reference/8.1/docs-index_.html#index-versioning
推荐阅读

比同事抢先一步学习进阶干货!



