当今大模型如此火热,作为一名数据同学,持续在关注LLM是如何应用在数据分析中的,也关注到很多公司推出了AI数智助手的产品,比如火山引擎数智平台VeDI—AI助手、 Kyligence Copilot AI数智助理、ThoughtSpot等,通过接入人工智能大模型,提升数据处理和查询分析的效率。智能数据分析助手,采用对话式分析技术,每个普通人都可以与数据进行随时随地的实时交互,根据用户的使用反馈,不断学习,自我迭代找到答案,并在团队内分享对数据的见解。
简单分析一下数据分析的发展阶段:第一阶段,以静态报表为主,传统BI和静态报表基本上都是面向开发部门的,业务部门提出需求之后,由开发根据报表工具开发出固定的报表,然后业务部门查看报表结果。第二阶段,敏捷BI自助式分析,在业务部门提出需求之后,数据分析可以基于敏捷BI的工具帮助业务部门快速获取所需的数据,帮助他们获得所需要的结果。第三阶段,不管是基于大模型的AskBI还是增强分析,都是直接面向业务的,其理念是业务部门直接使用对话式BI工具能够解决问题,获得所需的数据结果。这一过程无需像之前那样依赖开发部门开发报表,或者数据分析师基于敏捷BI再提供数据结果,而是直接由业务部门推进落地。

整体方案
通过多家数AI数智助手调研,实现智能数据分析的核心有:一是以指标为中心,二是大模型。其中也分享出了如何把指标平台+AI技术落地方案,提出了:人人用数=AI Copilot + 指标体系 + 合理成本的关键技术观点。
指标体系给到我们的是一个通用的数据语言,当我们每一个人都用数据来沟通时,我们遇到的第一个障碍一定是缺乏通用的语言。就像普通话让13 亿中国人能够自由沟通,数据的解释权有一个标准一致的口径也是非常重要的,是数据共享和协作的前提。
指标数据最理想的使用场景就是,想要就有,数据准确,可视化展示。用户期望能够随时查看自己想要的业务指标数据,绝大多数人都有自己的使用指标的渠道和方法,但是需要用户熟悉系统的操作、数据内容可能会根据需求提前预设好,如果是需要指标的话,就依赖支持者的时间了,或者需要排期开发。虽然每个人都各显其通能够拿到数据,但于用户体验来说,还是需要有操作和时间成本。
智能化的指标应用可以大幅提高数据指标的用户体验和效率。我们希望的场景是,用户对着手机:“告诉我昨天的DAU、用户留存、销售额”,系统就能快速的反馈给用户这三个指标的结果,并且是准确的。
指标的加工处理到使用中间有很多过程,从数据沉淀->数仓加工->口径定义->报表->系统->用户,中间流程最直接的方式就是自然语言直接对接到数据。

▐ 通用方案
通用做法是基于指标要素生产出指标的模型(提前预算好所有的可能),通过NLP技术,将自然语言转译成SQL,直接读取指标模型,大概的技术思路如下: 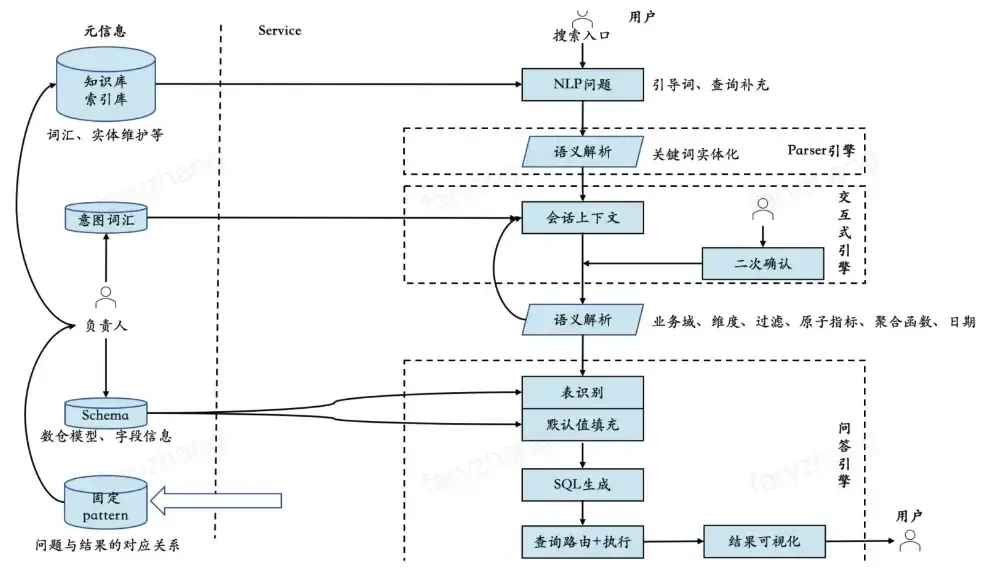
▐ 基于大模型
目标:通过大模型技术,打造用户在灵活搜索指标的时候能够快速反馈给用户正确的指标体验。
核心聚焦:
- 让系统尽可能的去理解自然语言,并准确的把它转换成可执行的SQL。
- 尽最大的可能覆盖用户的灵活需求,提高指标要素组合的成指标的组合数量。
基于LLM生成准确可执行SQL的关键思路:把指标管理模型的定义、指标要素等元数据信息送给LLM当作prompt进行指标搜索与生成。

Text-to-SQL
Text-to-SQL(简写为T2S,或者是Text2SQL),顾名思义就是把文本转化为SQL语言,更学术一点的定义是:把数据库领域下的自然语言(Natural Language,简写为NL)问题,转化为在关系型数据库中可以执行的结构化查询语言(Structured Query Language,简写为SQL)。
▐ Text-to-SQL是什么
Text-to-SQL任务相对正式的定义:在给定关系型数据库(或表)的前提下,由用户的提问生成相应的SQL查询语句。下图是spider数据集的样例,问题:有哪些系的教师平均工资高于总体平均值,请返回这些系的名字以及他们的平均工资。可以看到该问题对应的SQL语句是很复杂的,并且有嵌套关系。

▐ 数据集
常见的数据集有GenQuery、Scholar、WikiSQL、Spider、Spider-SYN、Spider-DK、Spider-SSP、CSpider、SQUALL、DuSQL、ATIS、SparC、CHASE等。

数据集的分类有单领域和交叉领域;有单轮对话和多轮对话;有简单问题和复杂问题;有中文语言和英文语言;有单张表和多张表等。重点介绍两个数据集:WikiSQL、Spider。
- WikiSQL
WikiSQL数据集是目前规模最大的Text-to-SQL数据集,由2017年美国的Salesforce公司提出,场景来源于Wikipedia,属于单领域。数据标注采用外包。
- 包含了80654个自然语言问题,77840个SQL语句。
- 包含了26521张数据库表,1个数据库只有1张表。
- 预测的SQL语句形式比较简单,基本为一个SQL主句加上0-3个WHERE子句条件限制构成,如下图所示:

- Spider
Spider数据集是多数据库、多表、单轮查询的Text-to-SQL数据集,也是业界公认难度最大的大规模跨领域评测榜单,由2018年耶鲁大学提出,由11名耶鲁大学学生标注。
- 10181个自然语言问题,5693个SQL语句。
- 涉及138个不同领域的200多个数据库。
- 难易程度分为:简单、中等、困难、特别困难。如下图所示

Spider数据集论文地址:https://arxiv.org/pdf/1809.08887.pdf。
CSpider是西湖大学在EMNLP2019上提出了一个中文text-to-sql的数据集,主要是选择Spider作为源数据集进行了问题的翻译,并利用SyntaxSQLNet作为基线系统进行了测试,同时探索了在中文上产生的一些额外的挑战,包括中文问题对英文数据库的对应问题(question-to-DBmapping)、中文的分词问题以及一些其他的语言现象。
▐ 评估指标
目前广泛使用的是执行准确率(Execution Accuracy,简称EX)和逻辑形式准确率(WxactMatch,简称EM)。
- 执行准确率
定义:计算SQL执行结果正确的数量在数据集中的比例。
缺点:存在高估的可能。因为一个完全不同的非标准的SQL可能查出于与标准SQL相同的结果(例如,空结果),这时也会判为正确。
举个例子:假如有个学生表,我们想要查询学生表中年龄等于19的学生姓名,就如“SELECT sname FROM Student where age = 19”所示,通过数据库执行标准SQL后得到结果为null;此时Text-to-SQL模型预测的SQL为“SELECT sname FROM Student where age = 20”,通过数据库执行后也得到结果为null。虽然预测的SQL跟标注的SQL不一致,但是结果是一样的,根据执行准确率指标来比较,那么就认为模型预测是正确的。
# groundtruth_SQL SELECT sname FROM Student where age = 19; # SQL执行结果 null # predict_SQL SELECT sname FROM Student where age = 20; # SQL执行结果 null
- 逻辑形式准确率
定义:计算模型生成的SQL和标注SQL的匹配程度。缺点:存在低估的可能。如一个SQL执行结果是正确的,但于标注SQL的字符串并非完全匹配,例如,只是select 列的顺序不同或SQL查询目的完全相同的不同SQL。为了解决一部分该问题,有研究指出了一种查询匹配精度query match accuracy:将生成的SQL和标注SQL都以标准形式表示,再计算两者匹配精度。这种方法只解决了由于排序问题而导致的误判。另外,通过对列和表进行排序并使用标准化别名来对SQL进行规范化,也可以消除不同SQL格式导致的误判问题。
举个例子:同样地,假如有个学生表,我们想要查询学生表中年龄等于19的学生姓名和学生学号。就如“SELECT sname FROM Student where age = 19”所示,通过数据库执行标准SQL后得到结果为(张三,123456);此时Text-to-SQL模型预测的SQL为“SELECT sno,sname FROM Student where age = 19”,通过数据库执行后也得到结果为(123456,张三),如果从逻辑形式准确率指标来看,因为SQL并不是一模一样,尽管两者只是筛选顺序的语序问题,所以会认为模型预测是错误的。
# groundtruth_SQL SELECT sname,sno FROM Student where age = 19; # SQL执行结果 张三,123456 # predict_SQL SELECT sno,sname FROM Student where age = 19; # SQL执行结果 123456,张三
▐ 研究方法
在深度学习的研究背景下,将 Text-to-SQL看作一个类似神经机器翻译的任务,主要采取seq2seq的模型框架。基线模型seq2seq在加入Attention、Copying等机制后,能够在ATIS、GeoQuery数据集上达到84%的精确匹配,但是在WikiSQL上只能达到23.3%的精确匹配,37.0%的执行正确率;在Spider上则只能达到5~6%的精确匹配。
究其原因,可以从编码和解码两个角度来看。首先编码方面,自然语言问句与数据库之间需要形成很好的对齐或映射关系,即问题中到底涉及了哪些表格中的哪些实体词,以及问句中的词语触发了哪些选择条件、聚类操作等;另一方面在解码部分,SQL作为一种形式定义的程序语言,本身对语法的要求更严格(关键字顺序固定)以及语义的界限更清晰,失之毫厘差之千里。普通的seq2seq框架并不具备建模这些信息的能力。
于是,主流模型的改进与后续工作主要围绕着以下几个方面展开:通过更强的表示(BERT、XLNet)、更好的结构(GNN)来显式地加强Encoder端的对齐关系及利用结构信息;通过树形结构解码、填槽类解码来减小搜索解空间,以增加SQL语句的正确性;通过中间表示等技术提高SQL语言的抽象性;通过定义新的对齐特征,利用重排序技术,对beamsearch得到的多条候选结果进行正确答案的挑选;以及非常有效的数据增强方法。
- 基于模板和匹配的方法
因为输出SQL本质上:是一个符合语法、有逻辑结构的序列,本身具有很强范式结构,所以可以采取基于模板和规则的方法。简单SQL语句都可以抽象成如下图:

简单SQL模板示例:
- AGG表示聚合函数,如求MAX,计数COUNT,求MIN。
- COLUMN表示需要查询的目标列。
- WOP表示多个条件之间的关联规则“与and /或 or”
- 三元组 [COLUMN, OP, VALUE] 构成了查询条件,分别代表条件列、条件操作符(>、=、<等)、条件值。
- *表示目标列和查询条件不止一个!
基于模板和匹配的方法,是早期的研究方法,适用于简单SQL,定义后的sql准确率高;不适合复杂SQL,没有定义模板的SQL不能识别。
- 基于Seq2Seq框架的方法
对于Text-to-SQL研究而言,本质上属于自然语言处理(Natural Language Processing,NLP),而在NLP领域中,常见的任务可以大概分为如下四个场景,1、N和M代表的是token的数量。
- 1 -> N:生成任务,比如输入为一张图片,输出图片的文本描述。
- N -> 1:分类任务,比如输入为一句话,输出这句话的情感分类。
- N -> N:序列标注任务,比如输入一句话,输出该句话的词性标注。
- N -> M:机器翻译任务,比如输入一句中文,输出英文翻译。
可以发现的是,Text-to-SQL任务是符合N -> M机器翻译任务的,处理机器翻译任务最主流的方法是基于Seq2Seq框架方法,Seq2Seq是一种基于序列到序列模型的神经网络架构,它由两个部分组成:编码器Encoder和解码Decoder。因此,Text-to-SQL最主流的方法也是基于Seq2Seq框架。
更多学习和研究Text-to-SQL相关内容,可以参考2篇综述文章:《A Survey on Text-to-SQL Parsing: Concepts, Methods, and Future Directions》Text-to-SQL解析的概念、方法和未来方向;《Recent Advances in Text-to-SQL: A Survey of What We Have and What We Expect》Text-to-SQL领域的最新进展:关于我们所拥有该领域的知识以及和所期盼的发展方向的综述。
大模型与数据分析:探索Text-to-SQL(中):https://developer.aliyun.com/article/1480725