

话接上文《图技术在 LLM 下的应用:知识图谱驱动的大语言模型 Llama Index》 同大家简单介绍过 LLM 和图、知识图谱相关的结合,现在我来和大家分享下最新的成果。毕竟,从 GPT-3 开始展现出超出预期的“理解能力“开始,我一直在做 Graph + LLM 技术组合、互补的研究、探索和分享,截止到现在 NebulaGraph 已经在 LlamaIndex 与 Langchain 项目做出了不少领先的贡献。
是时候,来给你展示展示我的劳动成果了。本文的主题是我们认为这个 LLM+ 领域最唾手可得、最容易摘取的果实,Text2Cypher:自然语言生成图查询。
Text2Cypher
顾名思义,Text2Cypher 做的就是把自然语言的文本转换成 Cypher 查询语句的这件事儿。和另一个大家可能已经比较熟悉的场景 Text2SQL:文本转换 SQL 在形式上没有什么区别。而本质上,大多数知识图谱、图数据库的应用都是在图上按照人类意愿进行查询,我们在图数据库上构造方便的可视化工具、封装方便的 API 的工作都是为这个目标服务的。
一直以来,阻碍图数据库、知识图谱被更广泛应用的主要因素可能就是图数据库的查询门槛了。那么,在没有大语言模型的时候,我们是怎么做的呢?
传统的 Text2Cypher
文本到查询这个领域,在大语言模型之前就一直存在这样的需求,一直是知识图谱最常见的应用之一,比如 KBQA(基于知识库的问答系统)的系统内部本质上就是 Text2Cypher。
这里以我之前写的项目 Siwi(发音:/ˈsɪwi/,一个基于篮球运动员数据集的问答应用)为例。
先来了解一下它的后端架构:
┌─────────────┬───────────────────────────────────┐
│ Speech │ Frontend │
│ ┌──────────▼──────────┐ Siwi, /ˈsɪwi/ │
│ │ Web_Speech_API │ A PoC of Dialog System │
│ │ Vue.JS │ With Graph Database │
│ │ │ Backed Knowledge Graph │
│ └──────────┬──────────┘ │
│ │ Sentence Backend │
│┌────────────┼────────────────────────────┐ │
││ ┌──────────▼──────────┐ │ │
││ │ Web API, Flask │ ./app/ │ │
││ └──────────┬──────────┘ │ │
││ │ Sentence ./bot/ │ │
││ ┌──────────▼──────────┐ │ │
││ │ Intent Matching, │ ./bot/classifier│ │
││ │ Symentic Processing │ │ │
││ └──────────┬──────────┘ │ │
││ │ Intent, Enties │ │
││ ┌──────────▼──────────┐ │ │
││ │ Intent Actor │ ./bot/actions │ │
│└─┴──────────┬──────────┴─────────────────┘ │
│ │ Graph Query │
│ ┌──────────▼──────────┐ │
│ │ Graph Database │ NebulaGraph │
│ └─────────────────────┘ │
└─────────────────────────────────────────────────┘
当一个问题语句发送过来之后,它首先要做意图识别(Intent)、实体识别(Entity),然后再利用 NLP 模型或者代码把相应的意图和实体构造成知识图谱的查询语句,最终查询图数据库,并根据返回结果构造答案。
可以想象,让程序能够:
- 从自然语言中理解意图:对应到哪一类支持回答的问题
- 找出实体:问题中涉及到的主要个体
- 从意图和实体构造查询语句
这不可能是一个容易的开发工作,一个真正能够落地的实现,其训练的模型或者实现的规则代码,所需考虑的边界条件可能非常多。
三行代码搞定 Text2Cypher
而在“后大语言模型”时代,这种从前需要专门训练或者写规则的“智能”应用场景成了通用模型 + 提示工程(Prompt Engineering)就能完成的任务。
注:提示工程(prompt)是指通过自然语言描述,让生成模型、语言模型完成“智能”任务的方法。
事实上,在 GPT-3 刚发布之后,我就开始利用它帮助我写很多非常复杂的 Cypher 查询语句了,我发现它可以写很多非常复杂的模式匹配、多步条件那种之前我需要一点点调试,半天才能写出来的语句。通常在它的答案之上,我只需要稍微修改就可以了,而且往往我还能从它的答案里知道我之前没了解到的 Cypher 语法盲区。
后来,在今年二月份的时候,我就试着实现了一个基于 GPT-3 (因为那时候还没有 GPT-3.5)的项目:ngql-GPT(代码仓库)。

图 1:Demo 图
它的工作原理非常简单,和 Text2SQL 没有区别。大语言模型已经通过公共领域学习了 Cypher 的语法表达,我们在提出任务的时候,只需要让 LLM 知道我们要查询的图的 Schema 作为上下文就可以了。
所以,基本上 prompt 就是:
你是一位 NebulaGraph Cypher 专家,请根据给定的图 Schema 和问题,写出查询语句。
schema 如下:
---
{schema}
---
问题如下:
---
{question}
---
下面写出查询语句:
然而,真实世界的 prompt 往往还需要增加额外的要求:
- 只返回语句,不用给出解释,不用道歉
- 强调不要写超出 schema 之外的点、边类型
感兴趣的同学,可以参考我在 LlamaIndex 的 KnowlegeGraph Query Engine 中的实现。
在真实场景中,我们想快速学习、构建大语言模型应用的时候,常常会用到 LangChain 或者 LlamaIndex 这样的编排(Orchestrator)工具,它们可以帮我们做很多合理的抽象,从而避免从头去实现很多通用的脚手架代码:
- 和不同语言模型交互
- 和不同向量数据库交互
- 数据分割
而且,这些编排工具还内置了很多工程方法的最佳实践。这样,我们常常调用一个方法就可以用到最新、最好用的大语言模型研究论文的方法了,比如 FLARE、Guidence。
为此,我在 LlamaIndex 和 LangChain 中都贡献了可以方便进行 NebulaGraph 上 Text2Cypher 的工具,真正做到 3 行代码,Text2Cypher。
NebulaGraph 上的 Text2Cypher
在 LlamaIndex 的 KnowledgeQueryEngine 和 LangChain 的 NebulaGraphQAChain 中:NebulaGraph 图数据库的 Schema 获取、Cypher 语句生成的 prompt、各种 LLM 的调用、结果的处理、衔接,我们可以全都不用关心,开箱即用!
使用 LlamaIndex
用 LlamaIndex,我们只需要:
- 创建一个
NebulaGraphStore实例 - 创建一个
KnowledgeQueryEngine
就可以直接进行问答了,是不是超级简单?具体的过程,可以参考文档:https://gpt-index.readthedocs.io/en/latest/examples/query_engine/knowledge_graph_query_engine.html
from llama_index.query_engine import KnowledgeGraphQueryEngine
from llama_index.storage.storage_context import StorageContext
from llama_index.graph_stores import NebulaGraphStore
graph_store = NebulaGraphStore(
space_name=space_name, edge_types=edge_types, rel_prop_names=rel_prop_names, tags=tags)
storage_context = StorageContext.from_defaults(graph_store=graph_store)
nl2kg_query_engine = KnowledgeGraphQueryEngine(
storage_context=storage_context,
service_context=service_context,
llm=llm,
verbose=True,
)
# 问答
response = nl2kg_query_engine.query(
"Tell me about Peter Quill?",
)
# 只生成语句
graph_query = nl2kg_query_engine.generate_query(
"Tell me about Peter Quill?",
)
使用 LangChain
类似的,在 Langchain 里,我们只需要:
- 创建一个
NebulaGraph实例 - 创建一个
NebulaGraphQAChain实例
就可以直接提问了。还是一样,具体过程参考文档:https://python.langchain.com/docs/modules/chains/additional/graph_nebula_qa
from langchain.chat_models import ChatOpenAI
from langchain.chains import NebulaGraphQAChain
from langchain.graphs import NebulaGraph
graph = NebulaGraph(
space=space_name,
username="root",
password="nebula",
address="127.0.0.1",
port=9669,
session_pool_size=30,
)
chain = NebulaGraphQAChain.from_llm(
llm, graph=graph, verbose=True
)
chain.run(
"Tell me about Peter Quill?",
)
Demo
如果你对 Text2Cypher 感兴趣,可以去 Demo 地址:https://www.siwei.io/demos/text2cypher/ 体验下。
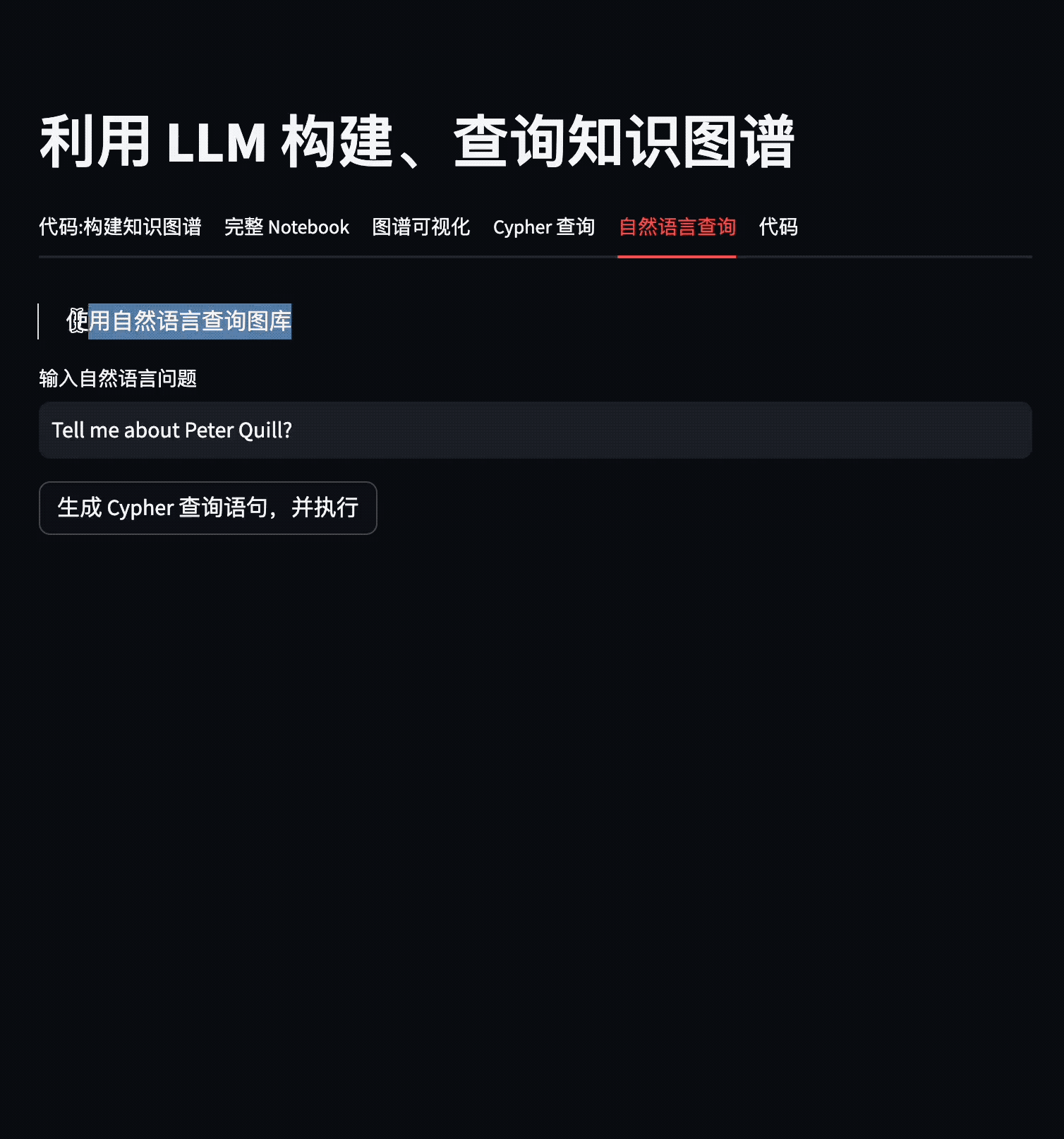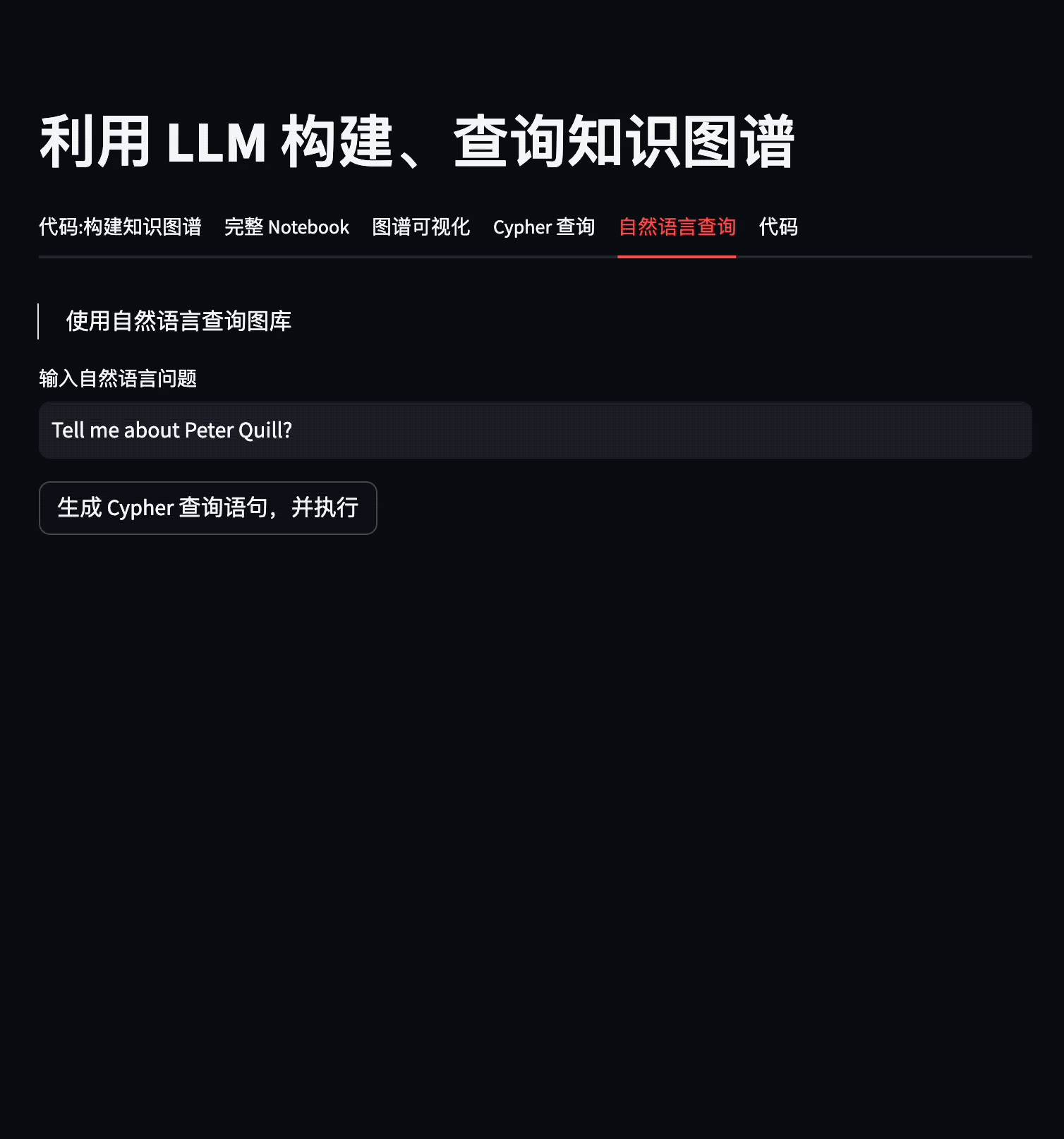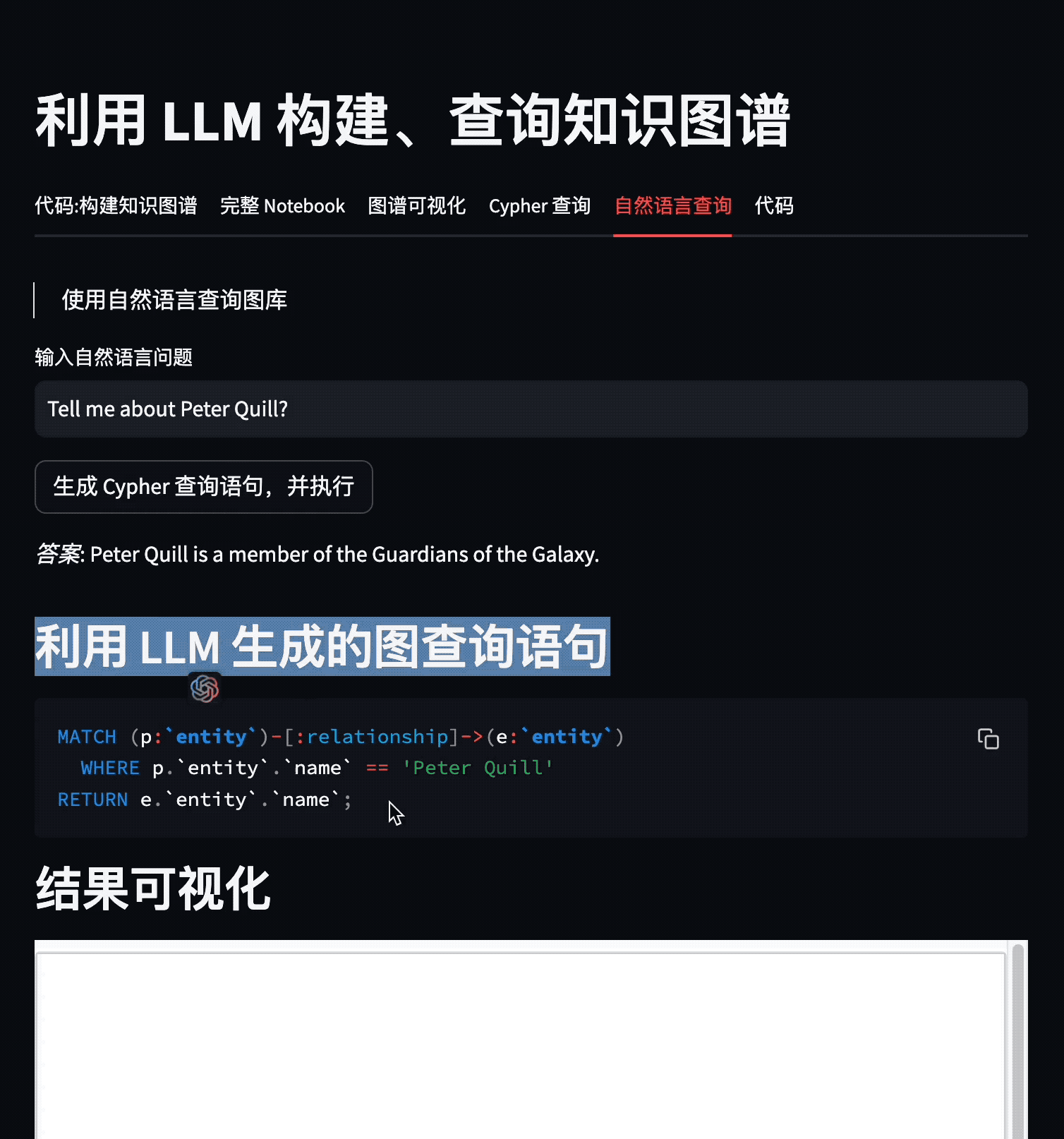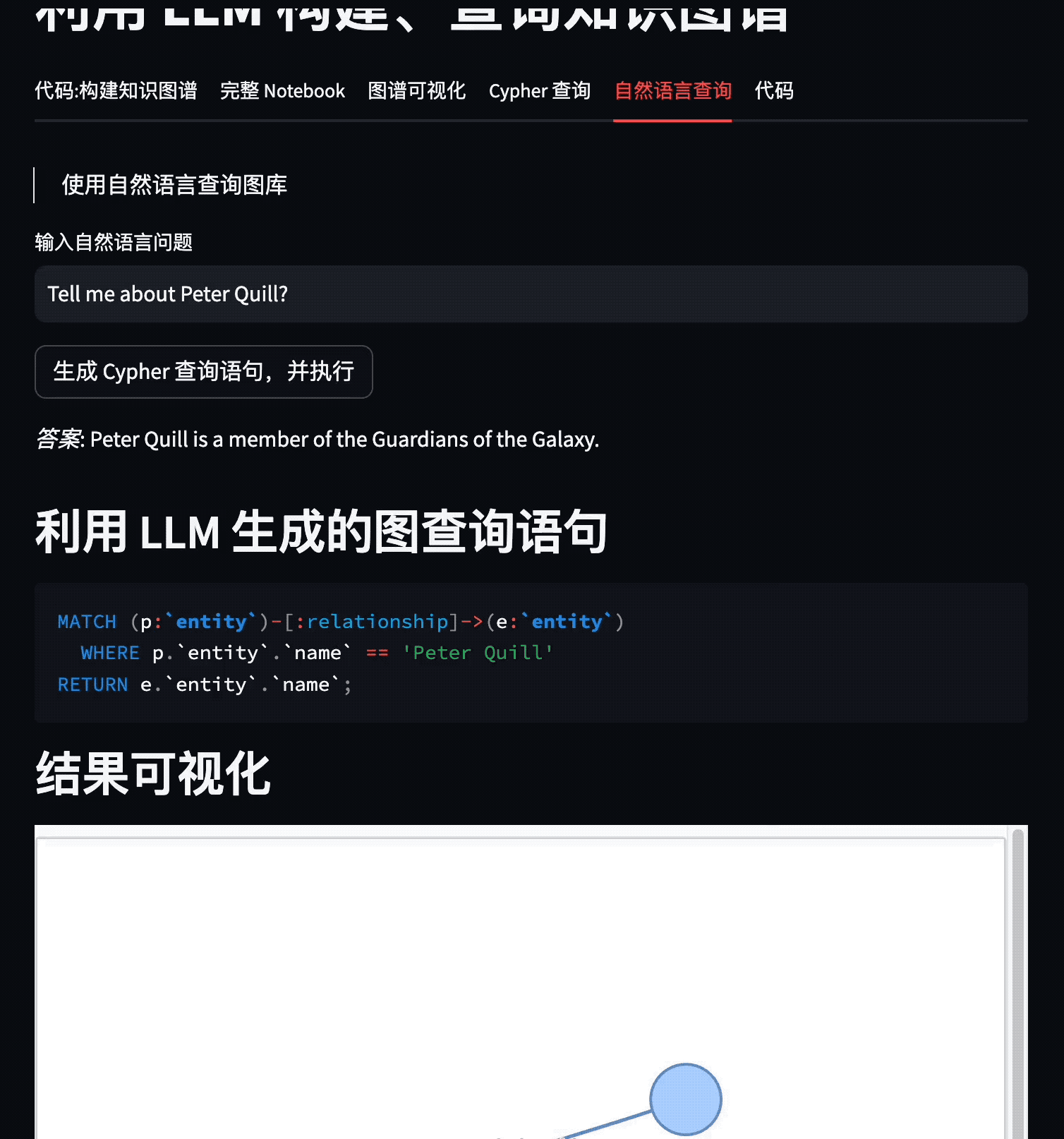
这个 Demo 展示了如何利用 LLM 从不同类型的信息源(以维基百科为例)中抽取知识三元组,并存储到图数据库 NebulaGraph 中。
本 Demo 中,我们先抽取了维基百科中关于《银河护卫队3》的信息,再利用 LLM 生成的知识三元组,构建了一个图谱。跟着,利用 Cypher 查询图谱,最后利用 LlamaIndex 和 LangChain 中的 Text2Cypher,实现了自然语言查询图谱的功能。
当然,你可以点击其他标签亲自试玩图谱的可视化、Cypher 查询、自然语言查询(Text2Cypher)等功能。
这里可以下载 完整的 Jupyter Notebook。
结论
有了 LLM,知识图谱、NebulaGraph 图数据库中的的数据中进行 Text2Cypher 从来没有这么简单过。
一个具有更强人机、机器接入的知识图谱可以代表了全新的时代,我们可能不需要从前那样高额成本去实现图库之上的后端服务,也不再需要培训才能让领域专家从图中获取重要的洞察了。
利用 LlamaIndex 或者 LangChain 中的生态集成,我们可以几乎没有开发成本地几行代码把自己的应用、图数据智能化。
然而,Text2Cypher 只是一个开始,请大家关注我们后续的文章,展现更多知识图谱、图数据库为大语言模型生态带来的变革。
相关阅读
谢谢你读完本文 (///▽///)
如果你想尝鲜图数据库 NebulaGraph,记得去 GitHub 下载、使用、(^з^)-☆ star 它 -> GitHub;和其他的 NebulaGraph 用户一起交流图数据库技术和应用技能,留下「你的名片」一起玩耍呀~
2023 年 NebulaGraph 技术社区年度征文活动正在进行中,来这里领取华为 Meta 60 Pro、Switch 游戏机、小米扫地机器人等等礼品哟~ 活动链接:https://discuss.nebula-graph.com.cn/t/topic/13970



