运用实证(实证依赖的是观察和经验,而不是理论和纯逻辑推理)方法进行调试可以充分利用软件的独特能力来告诉你软件运行的状态,而发挥这种能力的关键是找到能够重现问题的方法。
为什么重现问题如此重要?
不能重现问题,就几乎不可能取得进展,因为实证过程依赖于我们观察存在缺陷的软件执行的能力。
如何重现?
要做的第一件事很简单,就是按照缺陷报告描述(或提示)的步骤做,要做好问题重现就要抓好控制,而需要控制的因素如下:
1、软件本身:如果缺陷存在于最近修改的地方,那么你应该首先保证你调试运行的软件和缺陷被提交时使用的软件是同一个版本
2、软件的运行环境:如果要与外部系统进行交互,那么可能需要确保你使用的是相同的外部系统
3、你提供的输入:如果一段代码的运行情况受软件的配置影响很大,而缺陷又与这段代码有关,那么应该使用用户的配置来进行调试
控制软件本身:最好的办法就是创建一个自动化的构建过程
控制运行环境:要知道缺陷出现时软件所使用的环境,记住:软件环境包括了可能影响软件运行的所有因素。
控制输入:要找出输入数据以便准确重现问题。如果无法获得需要的所有信息,有两种选择:一是推测一下可能的输入是什么,二是把它们记录下来。
推测可能输入:出发点是假设问题确实存在,然后运用逆向工程的方法推测出能够导致问题的必要条件。
回溯:通常我们知道发生了什么事,但不清楚为什么会发生,此时可以使用回溯法,如果运气好,这个逻辑可以直接重现问题,即使不能完全重现,也可以提供有用的线索,再加上其他异常的现象,就可以排除某些可能性。
探测可能的输入值:黑盒技术中边界值分析可以在这里使用,因为输入值范围的边界是最有可能出现错误的地方,而相当于白盒测试中的边界值分析的分支覆盖,也可以在这里派上用场,可以尝试创建一些输入,使用这些输入可以覆盖同一代码块中的不同分支。
有效地识别能重现问题的输入顺序需要你转变思路——你不必证明系统工作正常,而要证明它不正常。
利用错误条件:当试图重现一个问题的时候,考虑一下是否有一些错误条件出现在运行的过程中,并去解释为什么问题会发生,然后,想想如何使错误条件表现出来或模拟出来,并且是否可以使你重现问题。
引入随机性:选取一系列不同输入值的一种方法就是引入一些随机输入值。
在推测重现问题时需要使用的数据过程中,记住:你需要验证与缺陷报告不符的结论。你找到了一种使软件出现缺陷的方法,并不意味着你找出了缺陷报告中的缺陷(尽管你已经清楚地发现了一个需要修正的缺陷)。
记录输入值:使用日志记录输入值。获取日志最简单的方法就是在整个代码中正确地放置了对System.out.printfln()或类似方法的调用,当然,也可以使用日志框架来完成更为复杂的功能(此处略去该方法)。
是否应该把日志留在代码中?
答案仁者见仁智者见智,如果在代码中嵌入日志,无疑,当问题再次发生时可以快速寻找到它,但是,它却容易导致代码变得难以理解,同时,它将类似注释内容而停滞,一成不变。因此,最佳的选择是注重实效,一旦将它嵌入代码,确保你的日志随时更新,与代码保持一致,而非为了日志而做日志。
负载和压力:关于负载测试工具的问题,通常是找到一个办法让它们重现真实的负载,但创建大量简单的交互行为可能并不会产生足够的负载来重现需要调试的问题。解决方法之一是使用日志记录真实的负载量,然后使用负载测试工具去重现它。
压力测试工具也是类似的,只是它不直接产生负载。
问题重现曾经是一个重要的障碍,下面我们将聊聊如何改进问题重现。不管是什么样的重现问题的方法,只要有,就比没有强。但是如何让重现问题既可靠又方便呢?
最小化反馈周期:和软件开发的其他众多领域一样,问题重现也是要使反馈周期最小,所经过的周期越短,反馈就越及时,其相关性就越高。
因此,最先要关注的就是找出问题重现中哪些方面是不需要的,将它们剔除掉,称为将问题重现最小化。那么,哪些元素可以被剔除呢?往往这要靠直觉。你了解软件,并且知道哪些模块可能被一些特定输入所影响,如果直觉不对,那么一些非直接的方法可能会帮助到你。
改进问题重现不是一蹴而就的事,而是在整个诊断过程中要牢记在心的东西。
将不确定的缺陷变为确定的:要做到这一点,需要明白不确定性从何来?
1、开始于不可预知的初始状态
当你的软件从未经初始化的内存读取数据时,通常会出问题。如果你有理由相信,是这个原因导致了不确定性问题,那么你最好的选择可能是使用调试内存分配器,来强制内存被初始化为一个众所周知的值,或用内存完整性检验软件来检测是否引用了未初始化的内存。
2、与外部系统进行交互
由此引起的不确定性问题往往不是因为二者表现不一,而是因为时间上微妙的不同。解决的策略是能够精确控制从外部系统接收了什么,以及何时接收的。最好的选择可能不是试图直接控制外部系统,而是用你能控制的东西替换它,比如调试子系统或代替测试。
3、故意地使用随机性
由此导致的不确定性听起来还是很正常的,幸运的是,大部分所谓使用随机数的软件都是通过确定性算法产生的伪随机数,因此这个是完全可以预测的行为。
4、多线程
由此引起的不确定性最难处理。在多核系统盛行的今天,往往我们处理的并不是真正的并发。而在缺乏并发控制的结构化方法下,我们不得不依靠一些特殊的方法。因此,在处理方法中最有效的工具之一就是不起眼的sleep()方法,它允许你强制一个线程长时间等待而出现竞争状态。
例如,假设你正在工作的软件中多个乖哦工作线程并行处理工作项目,工作线程使用下面的java代码来获得工作项目:
| if (item=workQueue.lockWorkItem()) { item.process(); workQueue.writeResultAndUnlock(item); } |
你试图跟踪一个间歇出现的缺陷,有时同一个工作项目会同时分配给两个工作线程。遗憾的事,这种情况极少出现,那么,你可以将代码更改为如下形式来增加重现该问题的几率:
| if (item=workQueue.lockWorkItem()) { Thread.sleep(1000); item.process(); workQueue.writeResultAndUnlock(item); } |
注意:尽管sleep()方法在重现问题和诊断阶段很有用,但在修复缺陷阶段它不是一个适合的方法。
自动化:一个自定义测试不仅能够方便的运行,而且当诊断结束开始修复的时候,对于即将编写完成的测试来说,它是一个很好的起点。如果确定缺陷重现需要通过日志,那么可以选择重放日志文件。
迭代:在诊断的过程中,你构建了足够多关于如何以及为何软件如此运行的信息,可以用此不断改进重现,如下图:
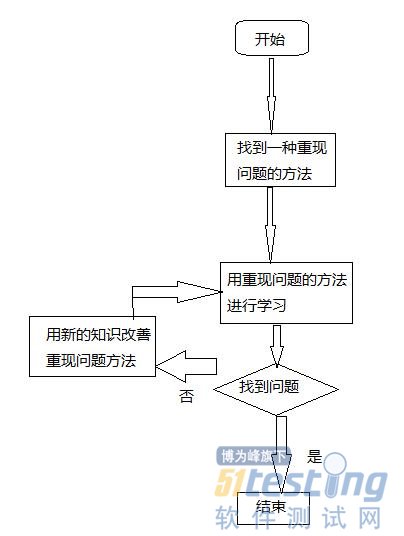
通过如下步骤反复改进:
1、你确定一个特定的模块已包含在内,其中有导致缺陷的元素,这样可以创建一个更小的文件。
2、进一步诊断,发现能通过用桩模块替代与第三方服务器交互的子系统,让问题每次都出现,桩模块可以很容易返回已经确定的响应。
3、最后,把跟踪范围缩小到一个特定函数,通过设置一组具体的参数调用该函数来创建单元测试,以便重现问题。
如果真的不能重现问题该怎么办?
首先,不要轻易给出“缺陷不存在”的结论,除非尽力获取了更多额外信息,用尽了所有可用的办法依然不能重现问题。其次,在相同区域解决不同的问题,尽管没有你目前跟踪的缺陷那么严重和紧急,也许它们蒙蔽了真正缺陷所在,也许会让你找到重现问题的关键因素,当然,也许没有任何帮助。第三,试着让其他人参与其中,这样可以获取其他人的不同角度看待问题,尤其是反馈错误的人。第四,充分利用用户群体,有些时候,缺陷出现在外部系统而非开发系统中,但这需要用户为你收集所需要的信息,从某种角度来说,并不理想。最后,可以使用推测法,你所需要做的是把自己融入到软件中,在想象中执行软件,执行每一步,考虑有哪些出现错误的可能性,尝试解释你跟踪的缺陷。
正常来说,我们有能力重现问题,而在下一章中,我们将会看到如何用重现来诊断问题。
最新内容请见作者的GitHub页:http://qaseven.github.io/