
三、选择排序
每一趟在后面
n-i-1个元素中选取最小的元素,作为有序序列的第i个元素,直到第n-1趟排序完成。最重要的还是堆排序。
1.简单选择排序
①算法执行过程可视化演示:
②算法代码:
void SelectSort(ElemType A[], int n){ for(int i = 0; i < n-1; i++){ //一共进行n-1趟 int min = i; //记录最小元素的位置 for(j = i+1; j < n; j++) //在待排序表中找到最小的元素 if(A[j] < A[min]) min = j; //更新最小元素下标 if(min != i) swap(A[i], A[min]);//交换位置 } }
③性能分析:
- 空间效率:使用常数个辅助单元,复杂度为O(1)。
- 时间效率:元素比较次数与初始状态无关,为n(n-1)/2次,移动次数最多为3(n-1)最少为0次,时间复杂度为O(n2)
- 稳定性:不稳定
2.堆排序
堆的定义: 满足n个关键字序列L[1...n]称为堆,堆可分为大根堆和小根堆,其在逻辑结构上可视为一棵完全二叉树。
如果满足每个结点的值都大于其左孩子和右孩子结点的值,则是大根堆;
如果满足每个结点的值都小于其左孩子和右孩子结点的值,则是小根堆。
①算法的执行过程:
- 首先将存放在表中的元素建成初始堆
- 输出堆顶元素,末尾元素补位
- 调整堆使其保持特性
- 重复以上步骤至所有元素都已输出
堆排序核心问题:①如何建堆;②输出元素后如何调整。
②算法执行过程可视化演示:
1.大根堆建堆
①从最后一个分支结点开始,与其孩子结点的值比较。如果不符合特性,则交换;如果是大根堆,选择孩子结点中的较大值,否则选择最小值;
②交换之后如果孩子结点也是分支结点,继续向下比较;
③反复利用上述过程构造下一级的堆,直至根结点。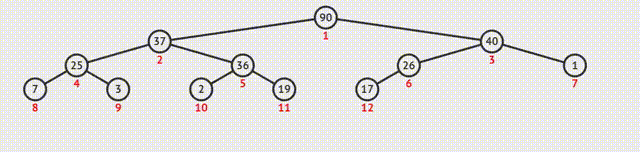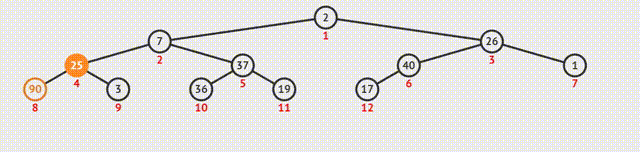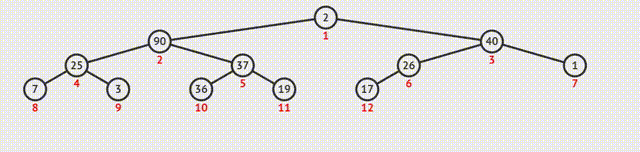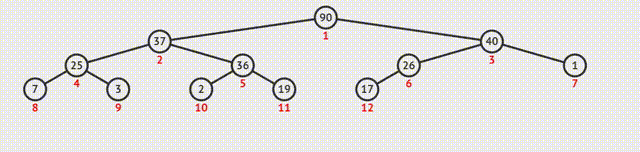
2.输出
①输出堆顶元素后,将最后一个元素与之交换;
②此时堆的结构特性被破坏,需要向下筛选;
③从上向下逐级比较,使每一级都符合特性。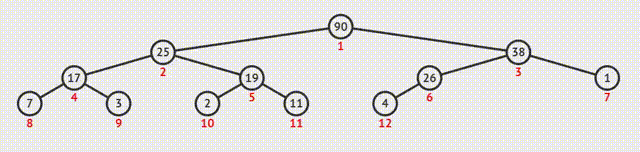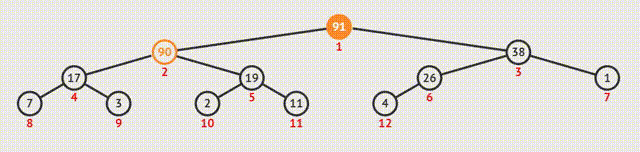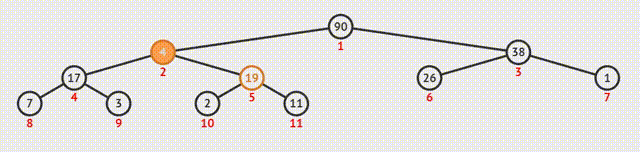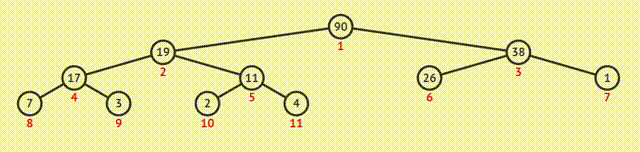
除了以上的主要功能,堆还具有以下的作用:
- 插入
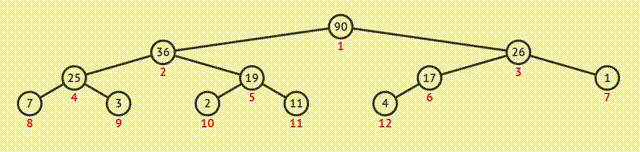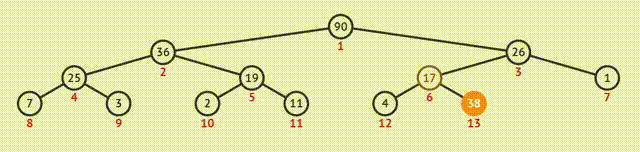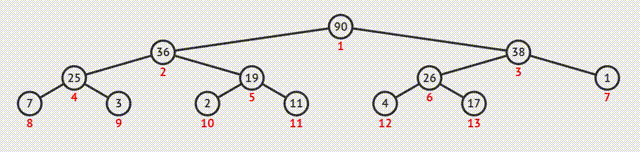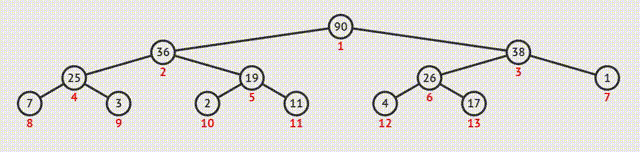
2.更新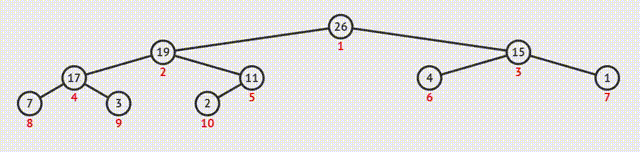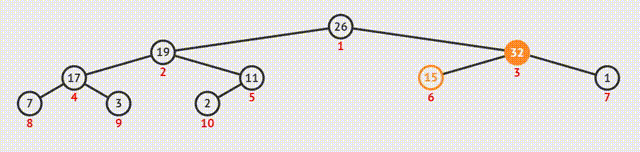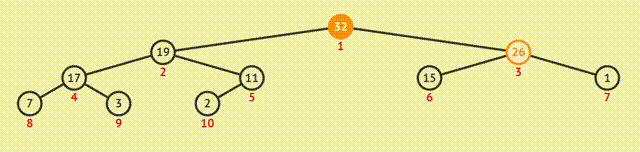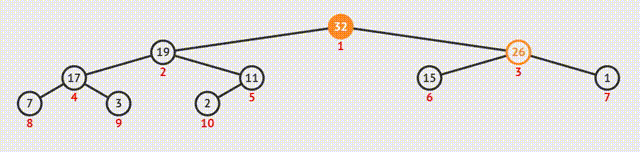
③算法代码:
//大根堆的建立 void BuildMaxHeap(ElemType A[], int len){ //从最后一个分支结点开始,逐级向上建堆 for(int i = len/2; i > 0; i--) HeapAdjust(A, i, len); } void HeapAdjust(ElemType A[], int k, int len){ A[0] = A[k]; //暂存这个分支结点 for(int i = 2*k; i <= len; i *= 2){ //从这个分支结点开始向下调整 if(i < len && A[i] < A[i+1]) i++; //右孩子更大 if(A[0] >= A[i]) break; //分支结点已是子堆中的最大值,符合特性 else{ //不符合特性,需要调整 A[k] = A[i]; //换的时候只是覆盖 k = i; //下标要交换,下次还说与A[0]比较 } } A[k] = A[0]; //放到最终符合特性的位置上 } //堆排序 void HeapSort(ElemType A[], int len){ BuildMaxHeap(A, len); //建堆 for(int i = len; i > 1; i--){ //n-1趟交换和建堆过程 swap(A[i], A[1]); //堆顶元素和堆底元素互换 HeapAdjust(A, 1, i-1); //将剩余的元素调整 } }
④性能分析:
- 空间效率:使用常数个辅助单元,空间复杂度为
O(1) - 时间效率:建堆时间为O(n),之后有n-1次向下调整,调整操作的时间复杂度为O(h)也就是O(log2n),所以堆排序的时间复杂度为O(nlog2n)。
- 稳定性:不稳定
- 适用性:适用于线性表为顺序存储的情况。
四、归并排序
归并排序与之前的算法思想不一样,它是将两个或以上的有序子表组合成一个新的有序表的过程。
我们称之为分治思想,在之前的快速排序中也有所体现。
①算法的执行过程:
对于n个元素的k路归并
首先可以开辟一块与表长度相同的辅助数组
分解: 将n个元素的待排序表分成各含n/2个元素的子表,每个表为长度为h的有序段。将每个子表进行递归的划分;
合并:每次归并时,将前后相邻且长度为h的有序段进行两两归并,得到前后相邻,长度为2h的有序段;
经过logkn次排序之后整个表变为有序表
②算法执行过程可视化演示:
③算法代码:
ElemType *B = (ElemType*)malloc((n+1)*sizeof(ElemType)); //辅助数组B void Merge(ElemType A[], int low, int mid, int high){ // for(int k = low; k <= high; k++) B[k] = A[k]; //将A的所有元素复制到B for(int i = low, j = mid+1, k = i; i <= mid && j <= high; k++){ //将两个子表归并成一个有序表 if(B[i] <= B[j]) A[k] = B[i++]; //小元素放到前面,指针后移 else A[k] = B[j++]; } while(i <= mid) A[k++] = B[i++]; //将A中剩余的元素复制到B while(i <= high) A[k++] = B[j++]; } void MergeSort(ElemType A[], int low, int high){ if(low < high){ int mid = (low+high)/2; //从中间划分两个子序列 MergeSort(A, low, mid); //对左子表进行递归的排序 MergeSort(A, mid+1, high); //对右子表进行递归的排序 Merge(A, low, mid, high); //最后将两个序列归并到一起 } }
④性能分析:
对于2路归并排序算法的性能分析如下:
- 空间效率:使用n个辅助单元,空间复杂度为
O(n) - 时间效率:每趟递归的时间复杂度为O(n),一共需要log2n次归并,所以总的时间复杂度为O(nlog2n)
- 稳定性:稳定
- 适用性:适用于线性表为顺序存储的情况。
五、基数排序
基数排序是一种很特别的排序,它不基于比较和移动,而是基于各个位上关键字的大小进行排序。
假设长度为n的线性表由d元组(kjd-1, kjd-2, …, kj1, kj0)组成,其中kjd-1为最主位关键字,kj0为最次位关键字。关键字排序有两种方法:
①最高位优先法:按关键字权重递减依次逐层划分成子序列,然后依次连接成有序序列。
②最低位优先法:按关键字权重递增依次逐层划分成子序列,然后依次连接成有序序列。
①算法的执行过程:
确定执行的轮数:确定数组中的最大元素有几位
创建编号为0-9的9个队列,因为所有的数字元素都是由0~9的十个数字组成
依次判断每个元素的个位,十位直至d位,根据相应数字存入对应的队列中
当表中的元素都放完后,依次出队,存入原数组,直至MAX轮结束输出数组。
②算法执行过程可视化演示: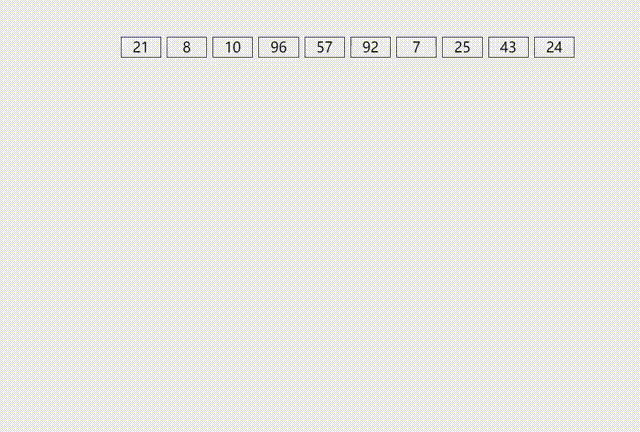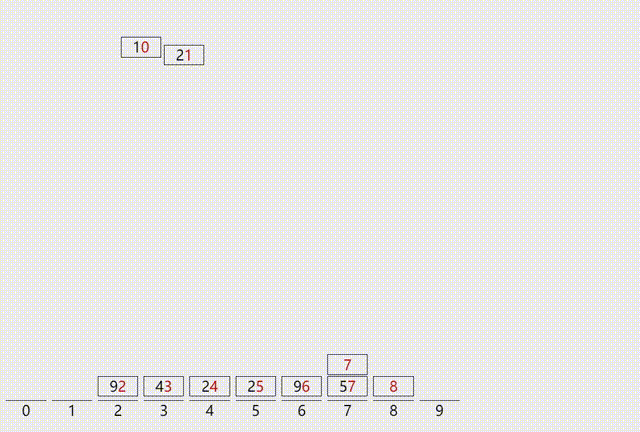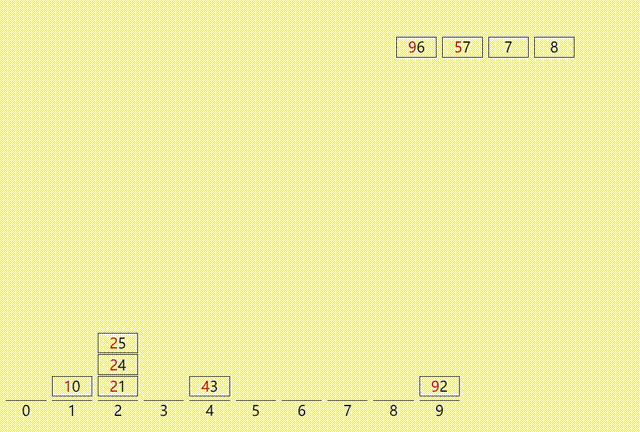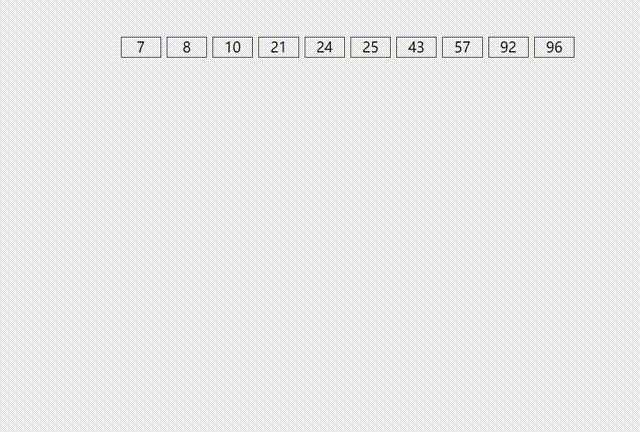
由于基数排序较为复杂且变化形式多样,这里的总结文章将不会给出代码
③性能分析:
1.空间效率:排序过程中使用r个队列,所以基数排序的空间复杂度为O(r)
2.时间效率:根据位数的多少,基数排序会进行d趟分配和收集。分配的时间与长度n呈线性关系,收集与队列的多少r有关,分别为O(n)和O(r)。所以基数排序的时间复杂度为O(d(n+r)),且与线性表的初始状态无关。
3.稳定性:稳定
4.适用性:适用于线性表为顺序存储和链式存储的情况。
六、对比总结
1.从时间复杂度看
平均情况下的时间复杂度为O(n2)的算法有:简单选择排序、直接插入排序和冒泡排序。(但直接插入排序和冒泡排序最好情况下的时间复杂度可以达到O(n),而简单选择排序则与序列的初始状态无关)
平均情况下的时间复杂度为O(nlog2n)的算法有:快速排序、堆排序、归并排序。(快速排序基于分治的思想,虽然最坏情况下快速排序时间会达到O(n2),但快速排序平均性能可以达到(nlog2n),在实际应用中常常优于其他排序算法。归并排序同样基于分治的思想,但由于其分割子序列与初始序列的排列无关,因此它的最好、最坏和平均时间复杂度均为O(nlog2n)。堆排序利用了一种称为堆的数据结构,可在线性时间内完成建堆)
希尔排序作为插入排序的拓展,对较大规模的排序都可以达到很高的效率,但目前未得出其精确的渐近时间。
基数排序与其他的都不同,它的最好、最坏和平均时间复杂度均为O(d(n+r))。
2.从空间复杂度看
- 简单选择排序、插入排序、冒泡排序、希尔排序和堆排序都仅需要借助常数个辅助空间。
- 快速排序在空间上只使用一个小的辅助栈,用于实现递归,平均情况下大小为O(log2n),当然在最坏情况下可能会增长到O(n)。
- 2路归并排序在合并操作中需要借助较多的辅助空间用于元素复制,大小为O(n)(虽然有方法能克服这个缺点,但其代价是算法会很复杂而且时间复杂度会增加)
3.从稳定性看
- 插入排序、冒泡排序、归并排序和基数排序是稳定的排序方法
- 简单选择排序、快速排序、希尔排序和堆排序都是不稳定的排序方法
4.从过程特征看
- 采用不同的排序算法,在一次循环或几次循环后的排序结果可能是不同的
- 冒泡排序和堆排序在每趟处理后都能产生当前的最大值或最小值
- 快速排序一趟处理就能确定一个元素的最终位置
5.性质对比
| 算法种类 | 时间复杂度 | 空间复杂度 | 稳定性 |
| \ | 最好情况 —平均情况—最坏情况 | \ | \ |
| 直接插入排序 | O(n)------O(n2)------O(n2) | O(1) | 是 |
| 冒泡排序 | O(n)------O(n2)------O(n2) | O(1) | 是 |
| 简单选择排序 | O(n2)------O(n2)------O(n2) | O(1) | 否 |
| 快速排序 | O(log2n)—O(log2n)—O(n2) | O(log2n) | 否 |
| 堆排序 | O(log2n)—O(log2n)—O(log2n) | O(1) | 否 |
| 二路归并排序 | O(log2n)—O(log2n)—O(log2n) | O(n) | 是 |
| 基数排序 | O(d(n+r))—O(d(n+r))—O(d(n+r)) | O( r ) | 是 |


