像是 NebulaGraph 这类基础设施上云,通用的方法一般是将线下物理机替换成云端的虚拟资源,依托各大云服务厂商实现“服务上云”。但还有一种选择,就是依托云数据基础设施,将数据库产品变成为云生态的一环,不只是提供自身的数据云服务,还能同其他的数据库一起分析挖掘业务数据价值。
在本篇分享中,让你在了解何为云原生基础设施之余,可以获得更多的 NebulaGraph 部署使用方法。又有新的使用姿势了,下面一起来了解下这个集成过程以及相关的使用方法。
KubeBlocks 是什么
在介绍之前,可能有了解云生态的小伙伴,会好奇标题中的 “KubeBlocsk”是什么?它带有 Kube- 前缀,和云原生什么关系?
KubeBlocks 的名字源自 Kubernetes(K8s)和乐高积木(Blocks),致力于让 K8s 上的数据基础设施管理就像搭乐高积木一样,既高效又有趣。
它是基于 Kubernetes 的云原生数据基础设施,为用户提供了关系型数据库、NoSQL 数据库、向量数据库以及流计算系统的管理控制功能。
下面开始进入主菜,KubeBlocsk 对 NebulaGraph 的集成。别看本文篇幅不短,事实上集成过程非常便捷,三步就能完成本次集成实践。
KubeBlocks 快速集成图数据库 NebulaGraph
因为本身 KubeBlocks 是 K8s 生态的框架基础设施,因此,你如果要基于 KubeBlocks 集成数据库或者是计算引擎的话,本章节内容就是相关的分享。简单来说,只要你熟悉 K8s,不需要学习任何新概念,像下面这样,3 步就搞定一个数据库的集成。
如果你不想了解集成过程,可以跳过本章节,直接进入到下一个章节的使用部分,了解如何在 KubeBlocks 上使用数据库。
下面,讲述本次 NebulaGraph 的集成过程,虽然本文以 NebulaGraph 为例,但是集成过程是相似的,可以举一反三。
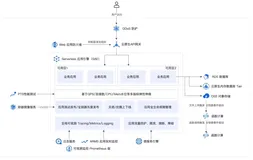
1. NebulaGraph 的服务架构
第一步,我们需要理解集群的组成,了解图数据库 NebulaGraph 的每个模块作用,以及其配置启动方式。

图 1: Nebula Graph 的架构图(来源:https://github.com/vesoft-inc/nebula)
如上图所示,完整的 NebulaGraph 系统是由内核和周边工具组成,包括不限于 nebula-console、nebula-python、nebula-java 等客户端。而其中的内核 Core 部分主要由三大服务组成,分别是:
- Meta Service:由 nebula-metad 进程提供,负责元数据管理,例如 Schema 操作、集群管理和用户权限管理等。如果集群部署的话,多个 metad 之间通过 raft 保证数据一致性;
- Graph Service:由 nebula-graphd 进程提供,负责处理计算请求;
- Storage Service:由 nebula-storaged 进程提供,负责存储数据。
2. 创建集群模板
在这一步,定义下集群拓扑、配置和版本等信息。
KubeBlocks Addon 支持多种扩展方式,目前主流的扩展方式是 Helm。因此,这里采用 Helm 方式来搞定相关部署配置:
创建一个 NebulaGraph 的 Helm Chart,并增加以下模板文件:
clusterdefinition.yaml:用来定义集群拓扑、组件配置和组件启动脚本。根据第一步的分析,我们知道 NebulaGraph 集群是一个多组件的形态,如果我们要正常使用图数据的话,需要用到 3 个内核组件,和 1 个客户端组件。因此,在这个文件中,组件配置中需要包括 4 个组件,后面使用实践部分会讲到,这里不做赘述;clusterversion.yaml:用来定义版本信息,例如:每个组件的 Docker Images。在本次实践中,支持的是 NebulaGraph v3.5.0 版本。此外,一个clusterdefinition.yaml文件可以关联多个clusterversion.yaml文件。因此,后续即使 NebulaGraph 发布了新版本,我们只用添加新的clusterversion.yaml文件就好。
搞定模版后,来快速地在本地环境调试下 Helm Chart,来校验正确性。
3. 添加 Addon 配置
最后,只用再添加大约 30 行 YAML 代码,就可以将新添加的 NebulaGraph 配置为 KubeBlocks 的 addon,非常方便。
就这样,三个步骤,就完成了 KubeBlocks 对 NebulaGraph 的集成。
附上相关的 PR 方便你做参考,整个过程非常简单:

图 2. NebulaGraph Helm Chart PR

图 3. NebulaGraph Addon PR
当然,如果你想在 KubeBlocks 上集成其他数据,一统你的那些数据库们,可以参考上面的思路。按照官方说法:“目前 KubeBlocks 已经支持了非常丰富的数据库架构和部署形态,如 MySQL、Redis、MongoDB 等,包括多种使用主备复制架构和基于 Paxos/Raft 的分布式架构”。
下面,来说说如何在 KubeBlocks 上使用图数据库 NebulaGraph。
如何在 KubeBlocks 上使用 NebulaGraph
你可以通过以下方式在 KubeBlocks 上体验 NebulaGraph 集群。
1. 安装 kbcli 和 KubeBlocks
安装最新版的 kbcli 和 KubeBlocks,下面是参考文档:
- kbcli:https://kubeblocks.io/docs/preview/user_docs/installation/install-kbcli
- KubeBlocks:https://kubeblocks.io/docs/preview/user_docs/installation/install-kubeblocks
2. 激活 Addon
安装了最新版本的 KubeBlocks 后,可以看到 NebulaGraph 已经出现在 KubeBlocks 的 addon 列表中。
下面命令可以查看到所有的 addon:
kbcli addon list
执行之后,我们可以看到 nebula 已经出现在列表中,但是它的状态是 Disabled。为了有效地控制服务资源,KubeBlocks 默认不会激活相关 addon 服务,只激活了几个主流数据库。

注: 如果在列表中,没有找到 nebula addon,请检查下你安装的软件版本,确保已安装新版本的 kbcli 和 KubeBlocks。
因为 nebula 服务处于未激活的状态,下面我们来激活下服务:
执行下面命令:
kbcli addon enable nebula
因为网络原因, 激活 Addon 可能需要一点时间, 可通过如下 addon describe 命令查看是否激活成功。
kbcli addon describe nebula
Name: nebula
Description: NebulaGraph is an Apache 2.0 licensed distributed graph database.
Labels: kubeblocks.io/provider=community
Type: Helm
Status: Enabled
Auto-install: false
若状态显示 Enabled 则表示服务已经激活成功。
3. 创建 NebulaGraph 集群
- 创建 NebulaGraph 集群
激活我们的 nebula 服务后,我们可以像创建 MySQL、PostgreSQL 集群一样,快速创建一个 NebulaGraph 集群,这里我们管它叫“mynebula”。像下面一样,一行命令搞定集群创建:
kbcli cluster create mynebula --cluster-definition nebula
其中:
mynebula是集群名称, 可以替换为你想要的集群名。--cluster-definition指定了从哪个预定义的集群模板开始创建,我们选择 nebula。
- 查看集群的各个组件
list-components 命令可查看集群的组件信息:
kbcli cluster list-components mynebula
这是执行结果:
NAME NAMESPACE CLUSTER TYPE IMAGE
nebula-console default mynebula nebula-console docker.io/vesoft/nebula-storaged:v3.5.0
nebula-graphd default mynebula nebula-graphd docker.io/vesoft/nebula-storaged:v3.5.0
nebula-metad default mynebula nebula-metad docker.io/vesoft/nebula-storaged:v3.5.0
nebula-storaged default mynebula nebula-storaged docker.io/vesoft/nebula-storaged:v3.5.0
可以看到,一个完整的 NebulaGraph 集群由 4 个组件组成,包括 nebula-console、nebula-graphd、nebula-metad、和 nebula-storaged,这也和前文介绍的 NebulaGraph 服务架构相呼应。
- 查看集群的各个实例
list-instances 命令用来查看实例信息:
kbcli cluster list-instances mynebula
可以看到,每个组件各自有多少实例,每个实例是什么配置规格。
NAME NAMESPACE CLUSTER COMPONENT STATUS ROLE ACCESSMODE AZ CPU(REQUEST/LIMIT) MEMORY(REQUEST/LIMIT) STORAGE NODE CREATED-TIME
mynebula-nebula-console-65844d578b-vf9kz default mynebula nebula-console Running <none> <none> <none> 1 / 1 1Gi / 1Gi data:20Gi kind-control-plane/172.19.0.2 Jul 09,2023 17:03 UTC+0800
mynebula-nebula-graphd-0 default mynebula nebula-graphd Running <none> <none> <none> 1 / 1 1Gi / 1Gi data:20Gi kind-control-plane/172.19.0.2 Jul 09,2023 17:03 UTC+0800
mynebula-nebula-metad-0 default mynebula nebula-metad Running <none> <none> <none> 1 / 1 1Gi / 1Gi data:20Gi kind-control-plane/172.19.0.2 Jul 09,2023 17:03 UTC+0800
mynebula-nebula-storaged-0 default mynebula nebula-storaged Running <none> <none> <none> 1 / 1 1Gi / 1Gi data:20Gi kind-control-plane/172.19.0.2 Jul 09,2023 17:03 UTC+0800
- 查看集群状态
list 命令用来查看集群整体状态:
kbcli cluster list mynebula
NAME NAMESPACE CLUSTER-DEFINITION VERSION TERMINATION-POLICY STATUS CREATED-TIME
mynebula default nebula nebula-v3.5.0 Delete Running Jul 09,2023 17:03 UTC+0800
若显示 Status 为 Running,表示集群已经创建成功并正在运行。
- 连接集群后,就可以像其他部署方式一样正常使用 NebulaGraph 的图服务了。像用
SHOW HOSTS命令,查看当前数据和分布状态:
kbcli cluster connect mynebula
Connect to instance mynebula-nebula-console-65844d578b-vf9kz
Welcome!
(root@nebula) [(none)]> SHOW HOSTS;
+------------------------------------------------------------------------------------------+------+----------+--------------+----------------------+------------------------+---------+
| Host | Port | Status | Leader count | Leader distribution | Partition distribution | Version |
+------------------------------------------------------------------------------------------+------+----------+--------------+----------------------+------------------------+---------+
| "mynebula-nebula-storaged-0.mynebula-nebula-storaged-headless.default.svc.cluster.local" | 9779 | "ONLINE" | 0 | "No valid partition" | "No valid partition" | "3.5.0" |
+------------------------------------------------------------------------------------------+------+----------+--------------+----------------------+------------------------+---------+
Got 1 rows (time spent 7.119ms/9.574125ms)
Sun, 09 Jul 2023 08:53:00 UTC
至此,你已经能正常使用 NebulaGraph 服务了。进阶使用的话,可以参考官方的文档:https://docs.nebula-graph.com.cn/3.5.0/
- 运维 Nebula Graph Cluster
当集群状态为 Running 后,你可以登录集群查看信息,并进行常见的运维操作,像是扩缩容、服务启停:hscale、vscale、volume-expand、start、stop 等操作。
下面,以水平扩缩容 hscale 为例,示范下对 NebulaGraph 集群的运维过程。
通过 kbcli 的hscale 命令,可以对集群的指定组件进行扩缩容。例如,将 nebula-storaged 组件扩展为 3 个节点:
kbcli cluster hscale mynebula --components nebula-storaged --replicas 3
通过 kbcli cluster list mynebula 命令再次查看集群状态,可以看到状态变更为 HorizontalScaling,说明它正在扩节点:
NAME NAMESPACE CLUSTER-DEFINITION VERSION TERMINATION-POLICY STATUS CREATED-TIME
mynebula default nebula nebula-v3.5.0 Delete HorizontalScaling Jul 09,2023 17:03 UTC+0800
等待几十秒后,扩容成功。我们再来查看下实例信息,可以看到已经有 3 个 nebula-storaged 节点:
kbcli cluster list-instances mynebula
NAME NAMESPACE CLUSTER COMPONENT STATUS ROLE ACCESSMODE AZ CPU(REQUEST/LIMIT) MEMORY(REQUEST/LIMIT) STORAGE NODE CREATED-TIME
mynebula-nebula-console-65844d578b-vf9kz default mynebula nebula-console Running <none> <none> <none> 1 / 1 1Gi / 1Gi data:20Gi kind-control-plane/172.19.0.2 Jul 09,2023 17:03 UTC+0800
mynebula-nebula-graphd-0 default mynebula nebula-graphd Running <none> <none> <none> 1 / 1 1Gi / 1Gi data:20Gi kind-control-plane/172.19.0.2 Jul 09,2023 17:03 UTC+0800
mynebula-nebula-metad-0 default mynebula nebula-metad Running <none> <none> <none> 1 / 1 1Gi / 1Gi data:20Gi kind-control-plane/172.19.0.2 Jul 09,2023 17:03 UTC+0800
mynebula-nebula-storaged-0 default mynebula nebula-storaged Running <none> <none> <none> 1 / 1 1Gi / 1Gi data:20Gi kind-control-plane/172.19.0.2 Jul 09,2023 17:03 UTC+0800
mynebula-nebula-storaged-1 default mynebula nebula-storaged Running <none> <none> <none> 1 / 1 1Gi / 1Gi data:20Gi kind-control-plane/172.19.0.2 Jul 09,2023 17:46 UTC+0800
mynebula-nebula-storaged-2 default mynebula nebula-storaged Running <none> <none> <none> 1 / 1 1Gi / 1Gi data:20Gi kind-control-plane/172.19.0.2 Jul 09,2023 17:47 UTC+0800
再次连接 NebulaGraph 集群,查看存储节点信息,可以看到新增的两个节点也已经可用,状态为 online:
kbcli cluster connect mynebula
Connect to instance mynebula-nebula-console-65844d578b-vf9kz
Welcome!
(root@nebula) [(none)]> SHOW HOSTS
+------------------------------------------------------------------------------------------+------+----------+--------------+----------------------+------------------------+---------+
| Host | Port | Status | Leader count | Leader distribution | Partition distribution | Version |
+------------------------------------------------------------------------------------------+------+----------+--------------+----------------------+------------------------+---------+
| "mynebula-nebula-storaged-0.mynebula-nebula-storaged-headless.default.svc.cluster.local" | 9779 | "ONLINE" | 0 | "No valid partition" | "No valid partition" | "3.5.0" |
| "mynebula-nebula-storaged-1.mynebula-nebula-storaged-headless.default.svc.cluster.local" | 9779 | "ONLINE" | 0 | "No valid partition" | "No valid partition" | "3.5.0" |
| "mynebula-nebula-storaged-2.mynebula-nebula-storaged-headless.default.svc.cluster.local" | 9779 | "ONLINE" | 0 | "No valid partition" | "No valid partition" | "3.5.0" |
+------------------------------------------------------------------------------------------+------+----------+--------------+----------------------+------------------------+---------+
Got 3 rows (time spent 1.971ms/5.443458ms)
Sun, 09 Jul 2023 10:00:06 UTC
后续,我们还会逐步集成 NebulaGraph 的备份/恢复、监控、参数变更等能力。
如果你想要了解更多 kbcli 支持的运维命令,可翻阅文档:https://kubeblocks.io/docs/preview/user_docs/cli。
丰富 NebulaGraph 生态
熟悉 NebulaGraph 周边生态的小伙伴,可能知道在 KubeBlocks 之前,NebulaGraph 对接了 Spark 和 Flink 生态,主要对接大数据生态,从而方便大家使用大数据的计算引擎。而这次,NebulaGraph 往云原生这边迈了一步,通过在 KubeBlocks 的集成,希望能给社区的大家带来更加丰富的生态环境。
正如本次完成集成工作的内核研发 @xtcylist 所说:“用开源的方式解决开源的问题”,我们希望联合和上下游的开源生态,构建更完善的 NebulaGraph 图生态。而他同样认为“数据库全部容器化部署是大趋势;全部 K8s 化部署也是一个比较热的预言。”。
因此,拥抱未来,NebulaGraph 先在 KubeBlocks 上进行了集成工作。如果你想要加入,完善 NebulaGraph 的生态,欢迎留言交流你的看法。
谢谢你读完本文 (///▽///)
欢迎前往 GitHub 来阅读 NebulaGraph 源码,或是尝试用它解决你的业务问题 yo~ GitHub 地址:https://github.com/vesoft-inc/nebula 想要交流图技术和其他想法,请前往论坛:https://discuss.nebula-graph.com.cn/
想要了解更多 KubeBlocks 和 NebulaGraph 的集成故事,欢迎来本周六的 meetup 同我们线下面对面交流~分享现场更有 NebulaGraph 绕坑秘籍放送 🧐 报名传送门:https://3393206724443.huodongxing.com/event/1711136721400