
大家好,我是水滴~
我们自己制作的 PDF 文件,为了避免被别人滥用,通常会加上水印。而市面上很多工具都是收费的,这无疑增加了我们的成本。
所以,我使用 Python 编写了一段加水印的代码,可以批量的为多个 PDF 文件加水印,完全是免费的,在这里分享给大家。
上面的 GIF 图片就是批量加水印的过程。在使用前,需要准备水印文件,并安装
PyPDF2库,下面是详细教程。
制作水印文件
创建一个 Word 文档,用 WPS 工具插入一个水印。水印可以是图片,也可以是文字,根据自己的需要编辑即可。最后将 Word 文件转换成 PDF ,这样水印文件就制作完成了。
下面截图是我制作的一个水印文件,文件名为“水印.pdf”。

安装 PyPDF2 库
PyPDF2 是一个免费且开源的 Python 第三方库,主要用来操作 PDF 文件。其功能主要包括拆分、合并、裁剪、转换、加密、加水印等。
下面是安装命令:
pip install PyPDF2
批量加水印代码
获取指定目录下所有 PDF 文件:
def get_pdf_files(input_path):
# 创建一个空的列表,用于存放所有PDF文件
pdf_files = list()
# 获取该目录下所有文件,并遍历
for filename in os.listdir(input_path):
# 筛选出所有PDF文件,并放入 pdf_files 中
if filename.endswith(".pdf"):
if filename.endswith("水印.pdf"):
# 忽略带水印的PDF文件
continue
pdf_files.append(input_path + filename)
return pdf_files
为单个 PDF 文件添加水印:
def add_watermark(watermark_file, pdf_file):
# 读取水印文件,并获取含有水印的页
watermark_reader = PdfReader(watermark_file)
watermark_page = watermark_reader.pages[0]
# 创建一个写缓存,用于缓存合并后的结果页
pdf_writer = PdfWriter()
# 读取PDF文件
pdf_reader = PdfReader(pdf_file)
# 获取PDF所有页,并遍历
for pdf_page in pdf_reader.pages:
# 将水印页合并到当前页上,并添加到写缓存中
pdf_page.merge_page(watermark_page)
pdf_writer.add_page(pdf_page)
# 将合并后的PDF文件,写入到指定地址
with open("_水印".join(os.path.splitext(pdf_file)), "wb") as result_path:
pdf_writer.write(result_path)
批量加水印:
# 获取指定目录下所有PDF文件
pdf_files = get_pdf_files("E:\\XXX\\")
# 遍历这些PDF文件,并添加水印
for pdf_file in pdf_files:
print("开始添加水印 -> " + pdf_file)
add_watermark("E:\\XXX\\水印.pdf", pdf_file)
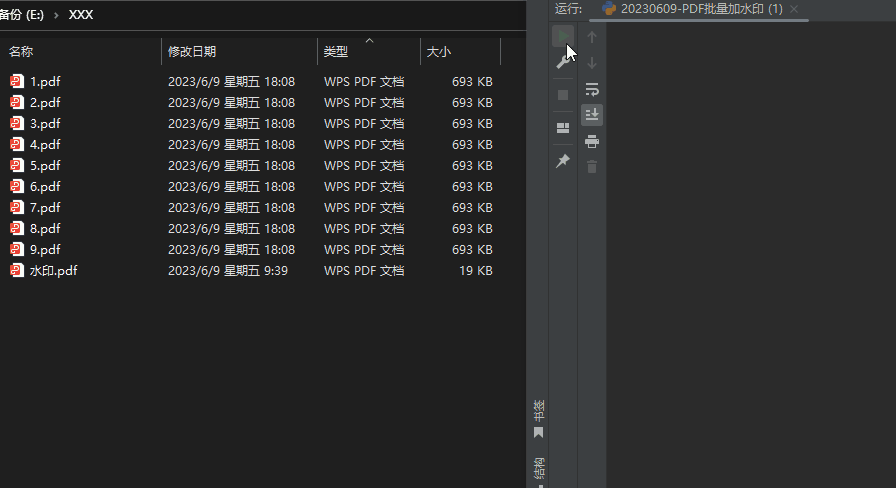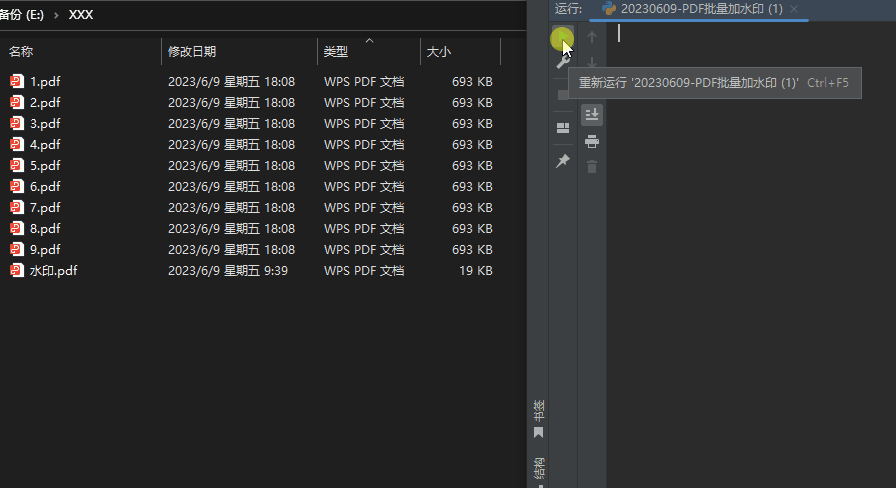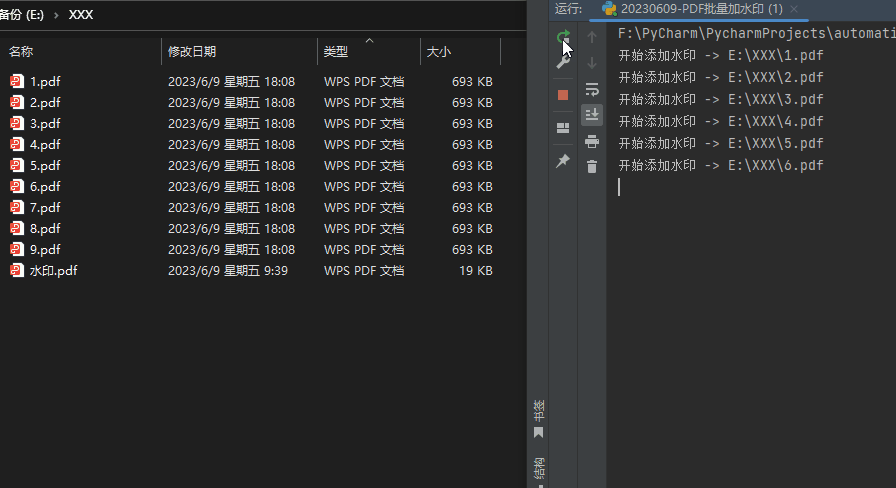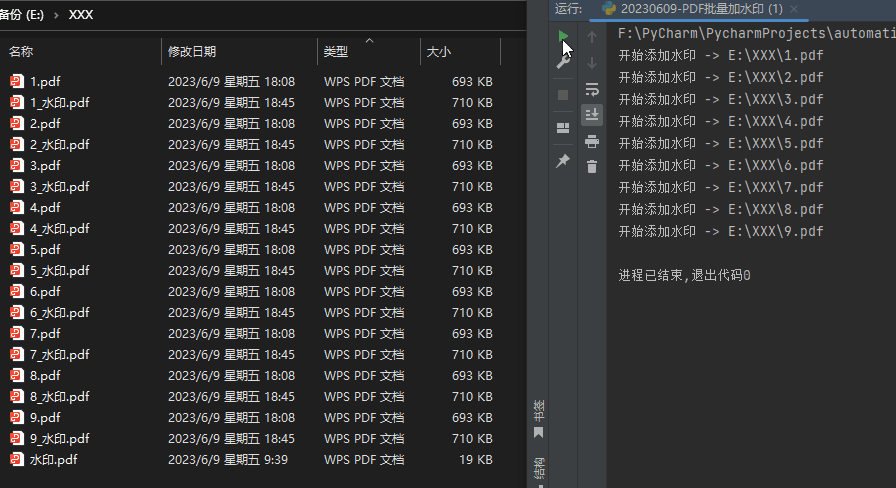
加水印后的效果:

🍅🍅🍅 获取源码,请在下方「水滴技术」公众号回复:20230609

