

前言
经过一段时间的加班,终于是把项目熬上线了。本以为可以轻松一点,但往往事与愿违,出现了各种各样的问题。由于做的是POS前置交易系统,涉及到和商户进件以及交易相关的业务,需要向上游支付机构上送“联行号”,但是由于系统内的数据不全,经常出现找不到银行或者联行号有误等情况,导致无法进件。
为了解决这个问题,我找上游机构要了一份支行信息。好家伙,足足有14w条记录。在导入系统时,发现有一些异常的数据。有些是江西的银行,地区码竟然是北京的。经过一段时间排查,发现这样的数据还挺多的。这可愁死我了,本来偷个懒,等客服反馈的时候,出现一条修一条。
经过2分钟的思考,想到以后每天都要修数据,那不得烦死。于是长痛不如短痛,还不如一次性修了。然后我反手就打开了百度,经过一段时间的遨游。发现下面3个网站的支行信息比较全,准备用来跟系统内数据作对比,然后进行修正。
- http://www.jsons.cn/banknum/
- http://www.5cm.cn/bank/支行编号/
- https://www.appgate.cn/branch/bankBranchDetail/支行编号
分析网站

输入联行号,然后选择查询方式,点击开始查询就可以。但是呢,结果页面一闪而过,然后被广告页面给覆盖了,这个时候就非常你的手速了。对于这样的,自然是难不倒我。从前端的角度分析,很明显展示结果的table标签被隐藏了,用来显示广告。于是反手就是打开控制台,查看源代码。

经过一顿搜寻,终于是找到了详情页的地址。

通过上面的操作,我们要想爬到数据,需要做两步操作。先输入联行号进行查询,然后进去详情页,才能取到想要的数据。所以第一步需要先获取查询的接口,于是我又打开了熟悉的控制台。

从上图可以发现这些请求都是在获取广告,并没有发现我们想要的接口,这个是啥情况,难道凭空变出来的嘛。并不是,主要是因为这个网站不是前后端分离的,所以这个时候我们需要从它的源码下手。

<html>
<body>
<form id="form1" class="form-horizontal" action="/banknum/" method="post">
<div class="form-group">
<label class="col-sm-2 control-label"> 关键词:</label>
<div class="col-sm-10">
<input class="form-control" type="text" id="keyword" name="keyword" value="102453000160" placeholder="请输入查询关键词,例如:中关村支行" maxlength="50" />
</div>
</div>
<div class="form-group">
<label class="col-sm-2 control-label"> 搜索类型:</label>
<div class="col-sm-10">
<select class="form-control" id="txtflag" name="txtflag">
<option value="0">支行关键词</option>
<option value="1" selected="">银行联行号</option>
<option value="2">支行网点地址</option>
</select>
</div>
</div>
<div class="form-group">
<label class="col-sm-2 control-label"> </label>
<div class="col-sm-10">
<button type="submit" class="btn btn-success"> 开始查询</button>
<a href="/banknum/" class="btn btn-danger">清空输入框</a>
</div>
</div>
</form>
</body>
</html>
通过分析代码可以得出:
- 请求地址:http://www.jsons.cn/banknum/
- 请求方式:POST
- 请求参数:
- keyword: 联行号
- txtflag :1
我们可以用PostMan来验证一下接口是否有效,验证结果如下图所示:
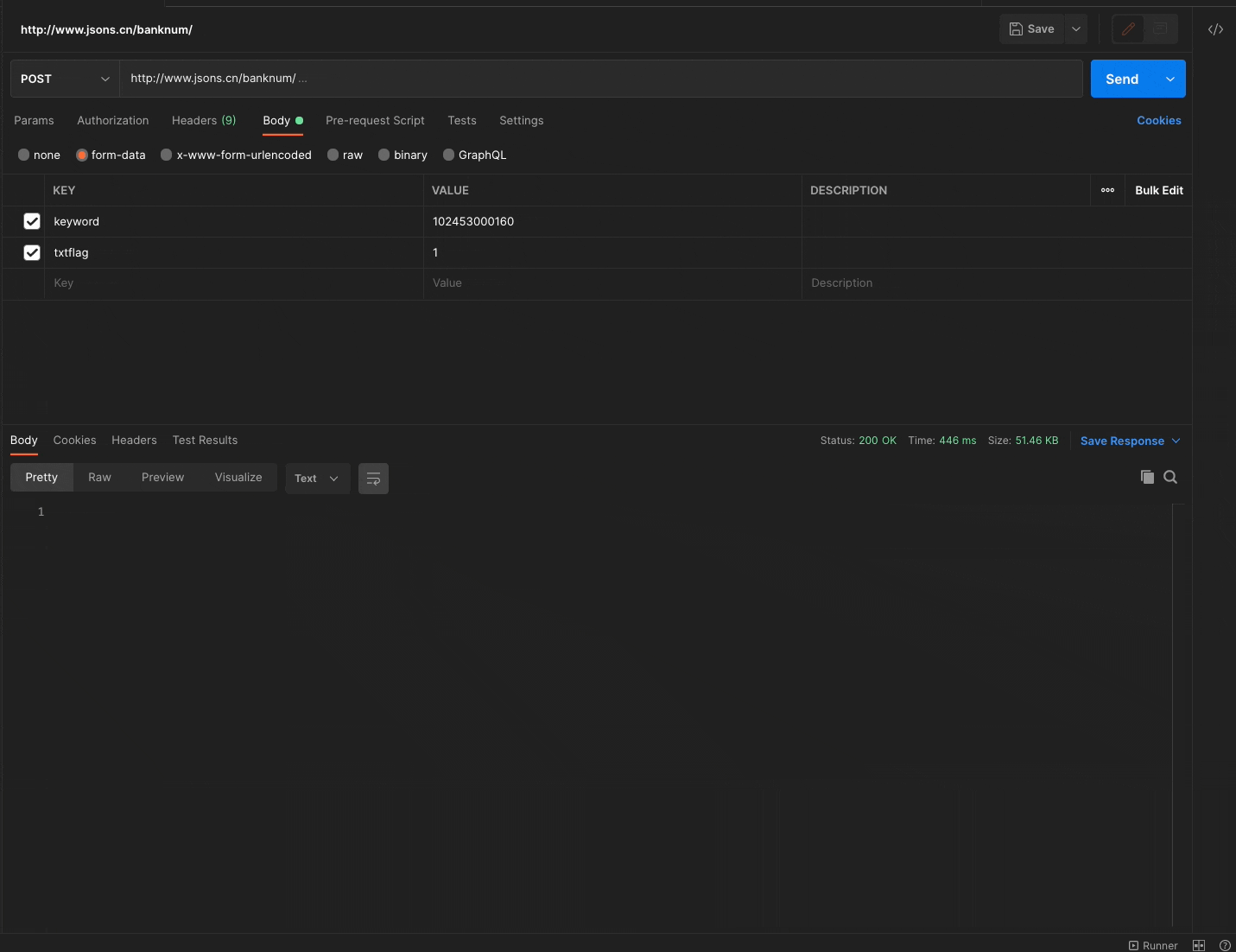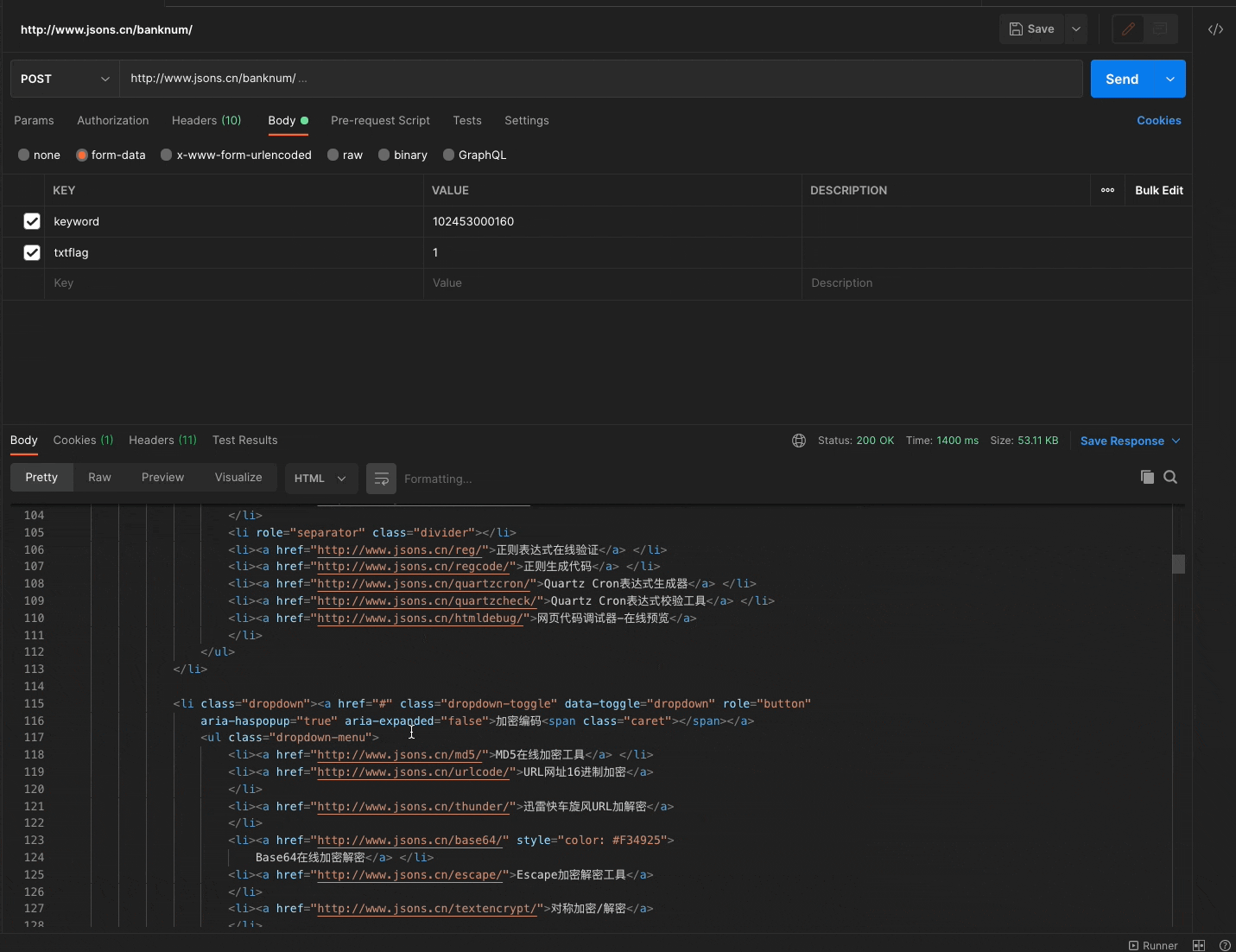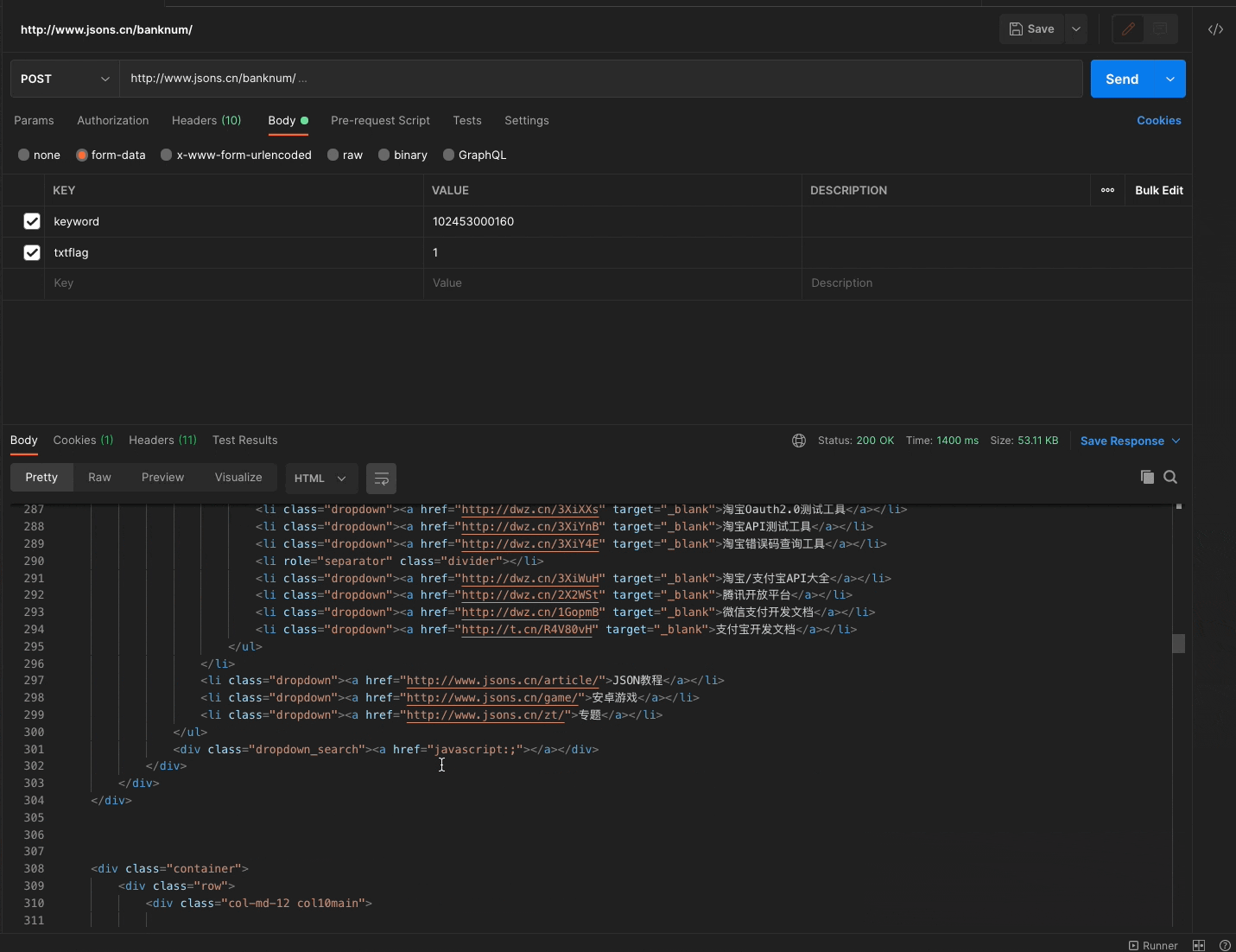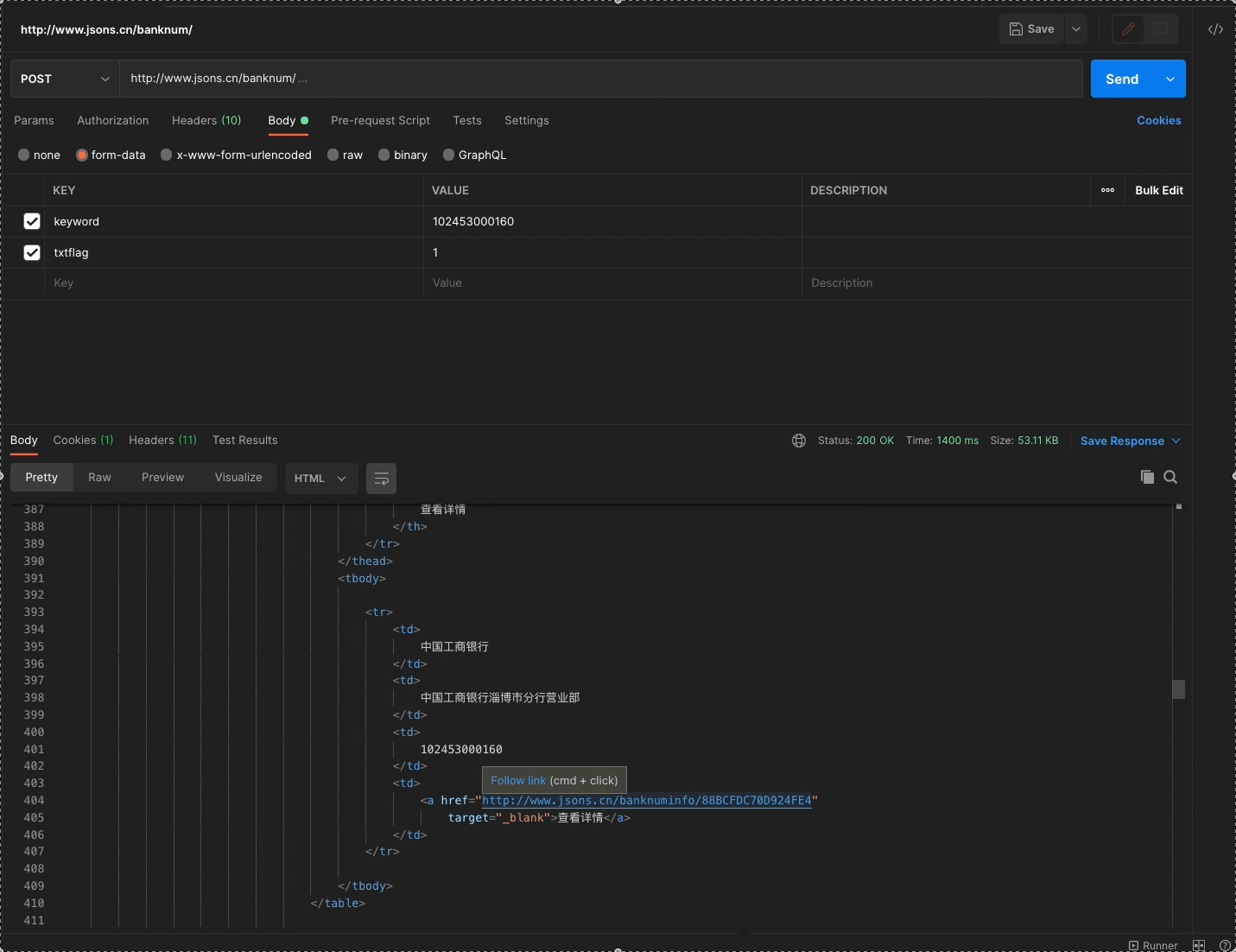
剩下的两个网站相对比较简单,只需要更改相应的联行号,进行请求就可以获取到相应的数据,所以这里不过多赘述。
爬虫编写
经过上面的分析了,已经取到了我们想要的接口,可谓是万事俱备,只欠代码了。爬取原理很简单,就是解析HTML元素,然后获取到相应的属性值保存下来就好了。由于使用Java进行开发,所以选用Jsoup来完成这个工作。
<!-- HTML解析器 -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.13.1</version>
</dependency>
由于单个网站的数据可能不全,所以我们需要逐个进行抓取。先抓取第一个,如果抓取不到,则抓取下一个网站,这样依次进行下去。这样的业务场景,我们可以使用变种的责任链设计模式来进行代码的编写。
BankBranchVO支行信息
@Data
@Builder
public class BankBranchVO {
/**
* 支行名称
*/
private String bankName;
/**
* 联行号
*/
private String bankCode;
/**
* 省份
*/
private String provName;
/**
* 市
*/
private String cityName;
}
BankBranchSpider抽象类
public abstract class BankBranchSpider {
/**
* 下一个爬虫
*/
private BankBranchSpider nextSpider;
/**
* 解析支行信息
*
* @param bankBranchCode 支行联行号
* @return 支行信息
*/
protected abstract BankBranchVO parse(String bankBranchCode);
/**
* 设置下一个爬虫
*
* @param nextSpider 下一个爬虫
*/
public void setNextSpider(BankBranchSpider nextSpider) {
this.nextSpider = nextSpider;
}
/**
* 使用下一个爬虫
* 根据爬取的结果进行判定是否使用下一个网站进行爬取
*
* @param vo 支行信息
* @return true 或者 false
*/
protected abstract boolean useNextSpider(BankBranchVO vo);
/**
* 查询支行信息
*
* @param bankBranchCode 支行联行号
* @return 支行信息
*/
public BankBranchVO search(String bankBranchCode) {
BankBranchVO vo = parse(bankBranchCode);
while (useNextSpider(vo) && this.nextSpider != null) {
vo = nextSpider.search(bankBranchCode);
}
if (vo == null) {
throw new SpiderException("无法获取支行信息:" + bankBranchCode);
}
return vo;
}
}
针对不同的网站解析方式不太一样,简言之就是获取HTML标签的属性值,对于这步可以有很多种方式实现,下面贴出我的实现方式,仅供参考。
JsonCnSpider
@Slf4j
public class JsonCnSpider extends BankBranchSpider {
/**
* 爬取URL
*/
private static final String URL = "http://www.jsons.cn/banknum/";
@Override
protected BankBranchVO parse(String bankBranchCode) {
try {
log.info("json.cn-支行信息查询:{}", bankBranchCode);
// 设置请求参数
Map<String, String> map = new HashMap<>(2);
map.put("keyword", bankBranchCode);
map.put("txtflag", "1");
// 查询支行信息
Document doc = Jsoup.connect(URL).data(map).post();
Elements td = doc.selectFirst("tbody")
.selectFirst("tr")
.select("td");
if (td.size() < 3) {
return null;
}
// 获取详情url
String detailUrl = td.get(3)
.selectFirst("a")
.attr("href");
if (StringUtil.isBlank(detailUrl)) {
return null;
}
log.info("json.cn-支行详情-联行号:{}, 详情页:{}", bankBranchCode, detailUrl);
// 获取详细信息
Elements footers = Jsoup.connect(detailUrl).get().select("blockquote").select("footer");
String bankName = footers.get(1).childNode(2).toString();
String bankCode = footers.get(2).childNode(2).toString();
String provName = footers.get(3).childNode(2).toString();
String cityName = footers.get(4).childNode(2).toString();
return BankBranchVO.builder()
.bankName(bankName)
.bankCode(bankCode)
.provName(provName)
.cityName(cityName)
.build();
} catch (IOException e) {
log.error("json.cn-支行信息查询失败:{}, 失败原因:{}", bankBranchCode, e.getLocalizedMessage());
return null;
}
}
@Override
protected boolean useNextSpider(BankBranchVO vo) {
return vo == null;
}
}
FiveCmSpider
@Slf4j
public class FiveCmSpider extends BankBranchSpider {
/**
* 爬取URL
*/
private static final String URL = "http://www.5cm.cn/bank/%s/";
@Override
protected BankBranchVO parse(String bankBranchCode) {
log.info("5cm.cn-查询支行信息:{}", bankBranchCode);
try {
Document doc = Jsoup.connect(String.format(URL, bankBranchCode)).get();
Elements tr = doc.select("tr");
Elements td = tr.get(0).select("td");
if ("".equals(td.get(1).text())) {
return null;
}
String bankName = doc.select("h1").get(0).text();
String provName = td.get(1).text();
String cityName = td.get(3).text();
return BankBranchVO.builder()
.bankName(bankName)
.bankCode(bankBranchCode)
.provName(provName)
.cityName(cityName)
.build();
} catch (IOException e) {
log.error("5cm.cn-支行信息查询失败:{}, 失败原因:{}", bankBranchCode, e.getLocalizedMessage());
return null;
}
}
@Override
protected boolean useNextSpider(BankBranchVO vo) {
return vo == null;
}
}
AppGateSpider
@Slf4j
public class AppGateSpider extends BankBranchSpider {
/**
* 爬取URL
*/
private static final String URL = "https://www.appgate.cn/branch/bankBranchDetail/";
@Override
protected BankBranchVO parse(String bankBranchCode) {
try {
log.info("appgate.cn-查询支行信息:{}", bankBranchCode);
Document doc = Jsoup.connect(URL + bankBranchCode).get();
Elements tr = doc.select("tr");
String bankName = tr.get(1).select("td").get(1).text();
if(Boolean.FALSE.equals(StringUtils.hasText(bankName))){
return null;
}
String provName = tr.get(2).select("td").get(1).text();
String cityName = tr.get(3).select("td").get(1).text();
return BankBranchVO.builder()
.bankName(bankName)
.bankCode(bankBranchCode)
.provName(provName)
.cityName(cityName)
.build();
} catch (IOException e) {
log.error("appgate.cn-支行信息查询失败:{}, 失败原因:{}", bankBranchCode, e.getLocalizedMessage());
return null;
}
}
@Override
protected boolean useNextSpider(BankBranchVO vo) {
return vo == null;
}
}
初始化爬虫
@Component
public class BankBranchSpiderBean {
@Bean
public BankBranchSpider bankBranchSpider() {
JsonCnSpider jsonCnSpider = new JsonCnSpider();
FiveCmSpider fiveCmSpider = new FiveCmSpider();
AppGateSpider appGateSpider = new AppGateSpider();
jsonCnSpider.setNextSpider(fiveCmSpider);
fiveCmSpider.setNextSpider(appGateSpider);
return jsonCnSpider;
}
}
爬取接口
@RestController
@AllArgsConstructor
@RequestMapping("/bank/branch")
public class BankBranchController {
private final BankBranchSpider bankBranchSpider;
/**
* 查询支行信息
*
* @param bankBranchCode 支行联行号
* @return 支行信息
*/
@GetMapping("/search/{bankBranchCode}")
public BankBranchVO search(@PathVariable("bankBranchCode") String bankBranchCode) {
return bankBranchSpider.search(bankBranchCode);
}
}
演示
爬取成功


爬取失败的情况

代码地址
总结
这个爬虫的难点主要是在于Jsons.cn。因为数据接口被隐藏在代码里面,所以想取到需要花费一些时间。并且请求地址和页面地址一致,只是请求方式不一样,容易被误导。比较下来其他的两个就比较简单,直接替换联行号就可以了,还有就是这个三个网站也没啥反扒的机制,所以很轻松的就拿到了数据。
结尾
如果觉得对你有帮助,可以多多评论,多多点赞哦,也可以到我的主页看看,说不定有你喜欢的文章,也可以随手点个关注哦,谢谢。
我是不一样的科技宅,每天进步一点点,体验不一样的生活。我们下期见!




