
链表的奇偶重排

思路
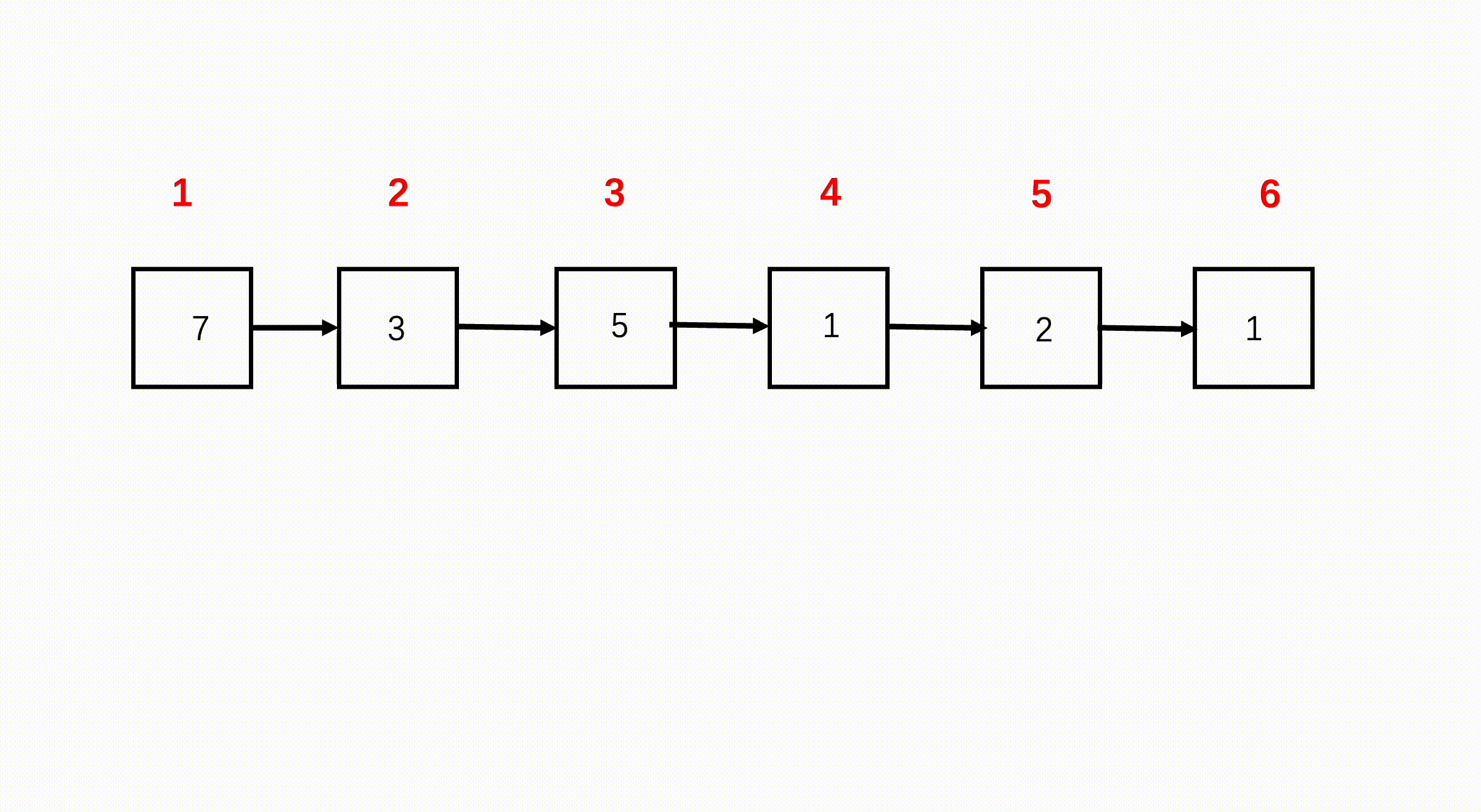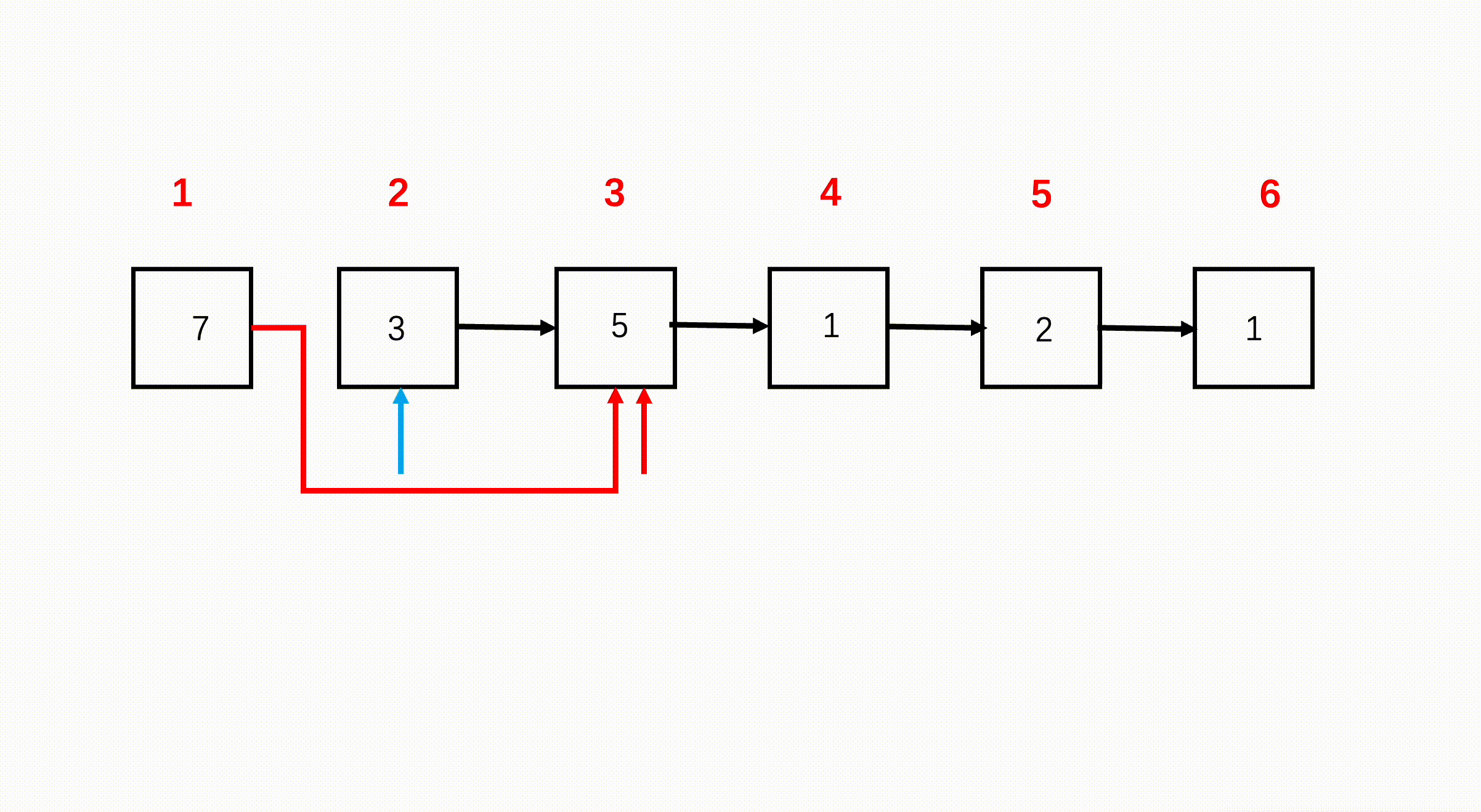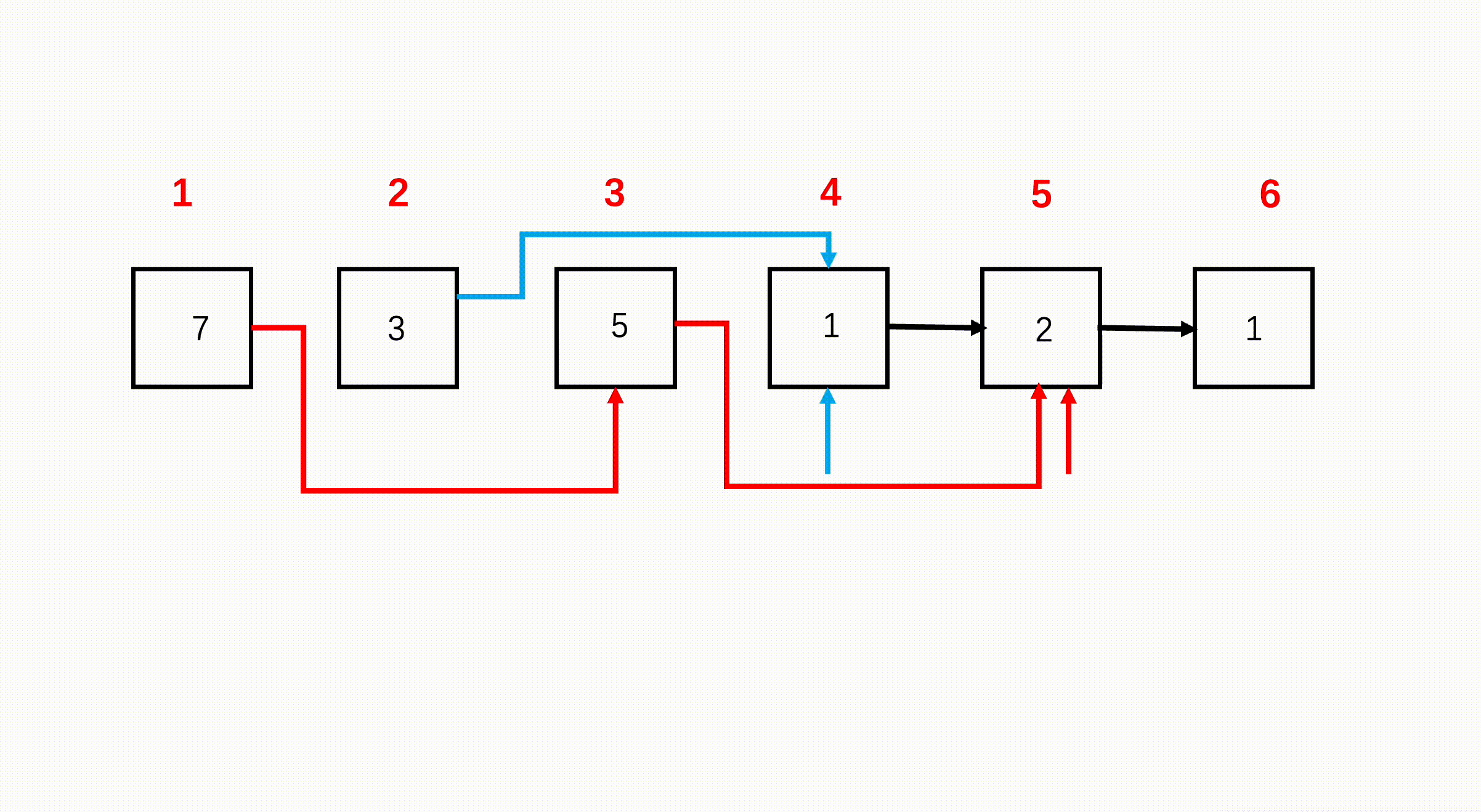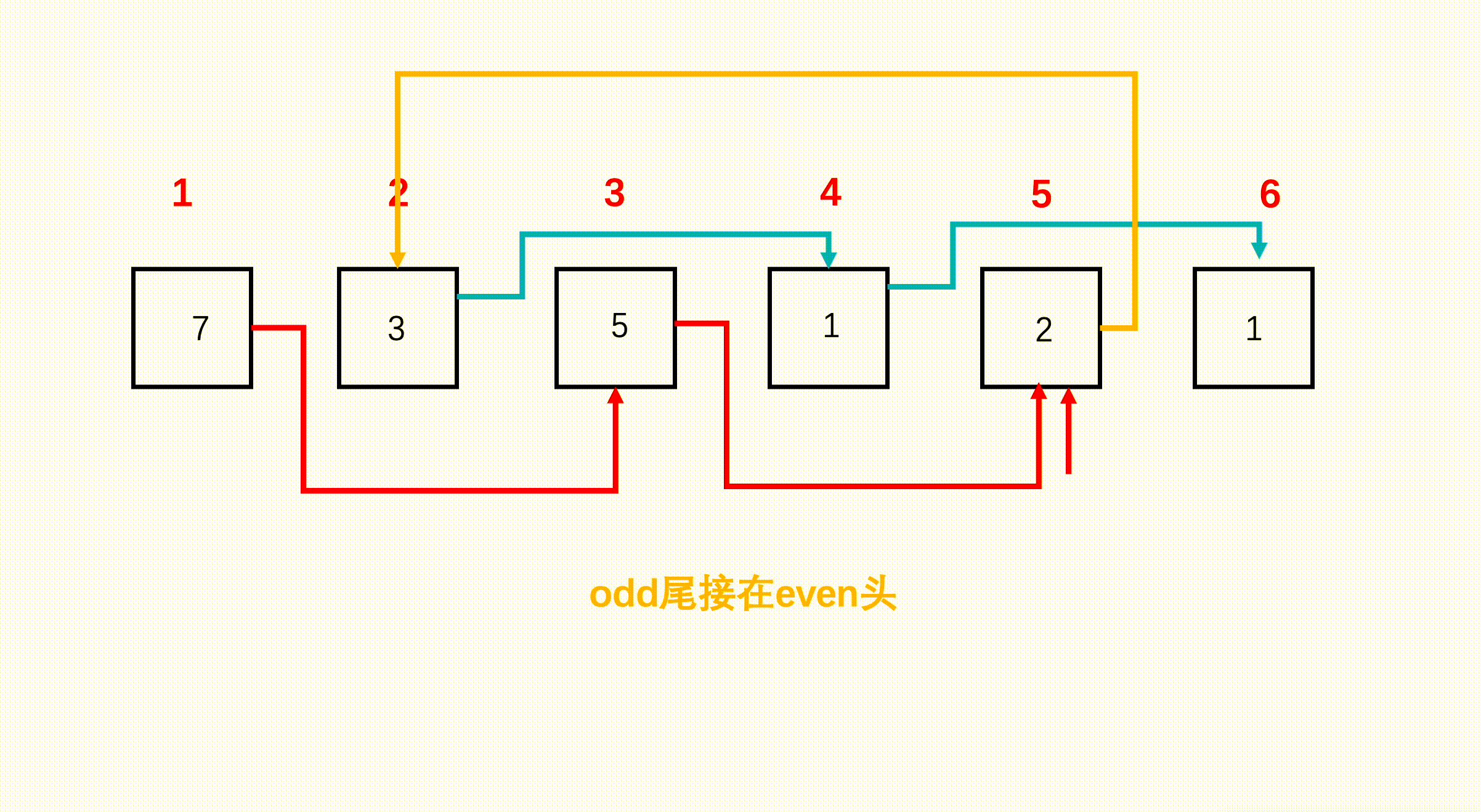
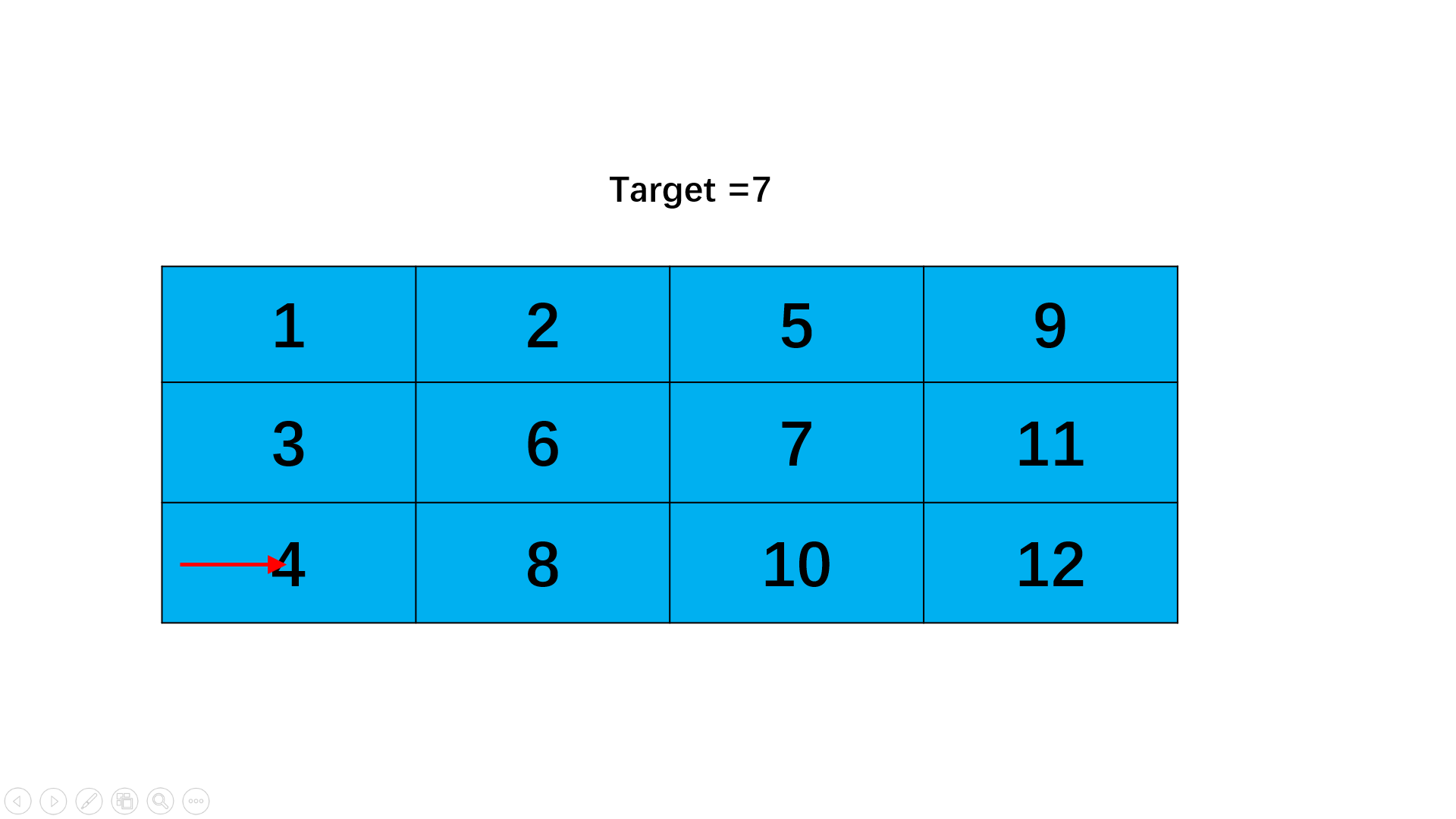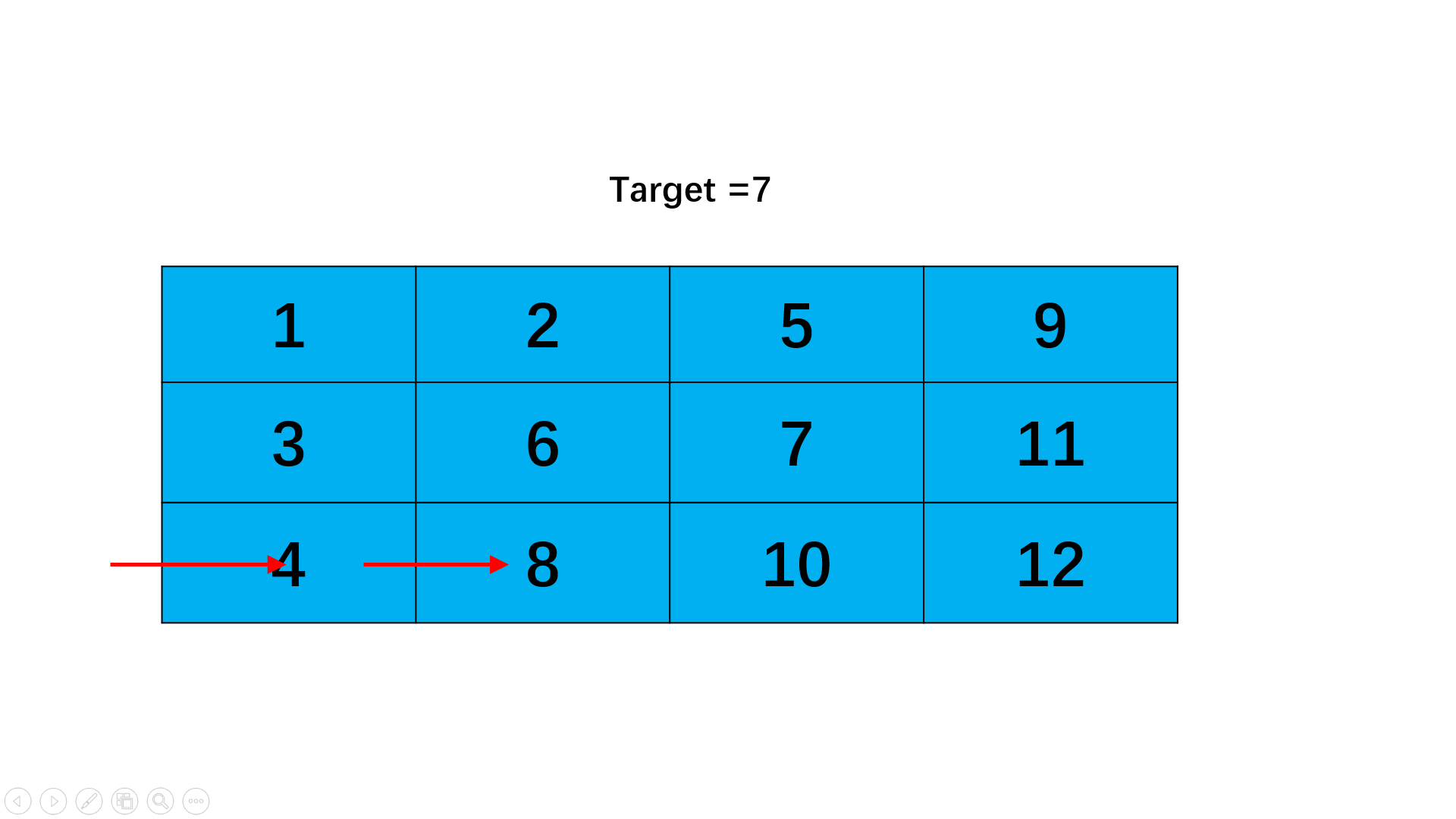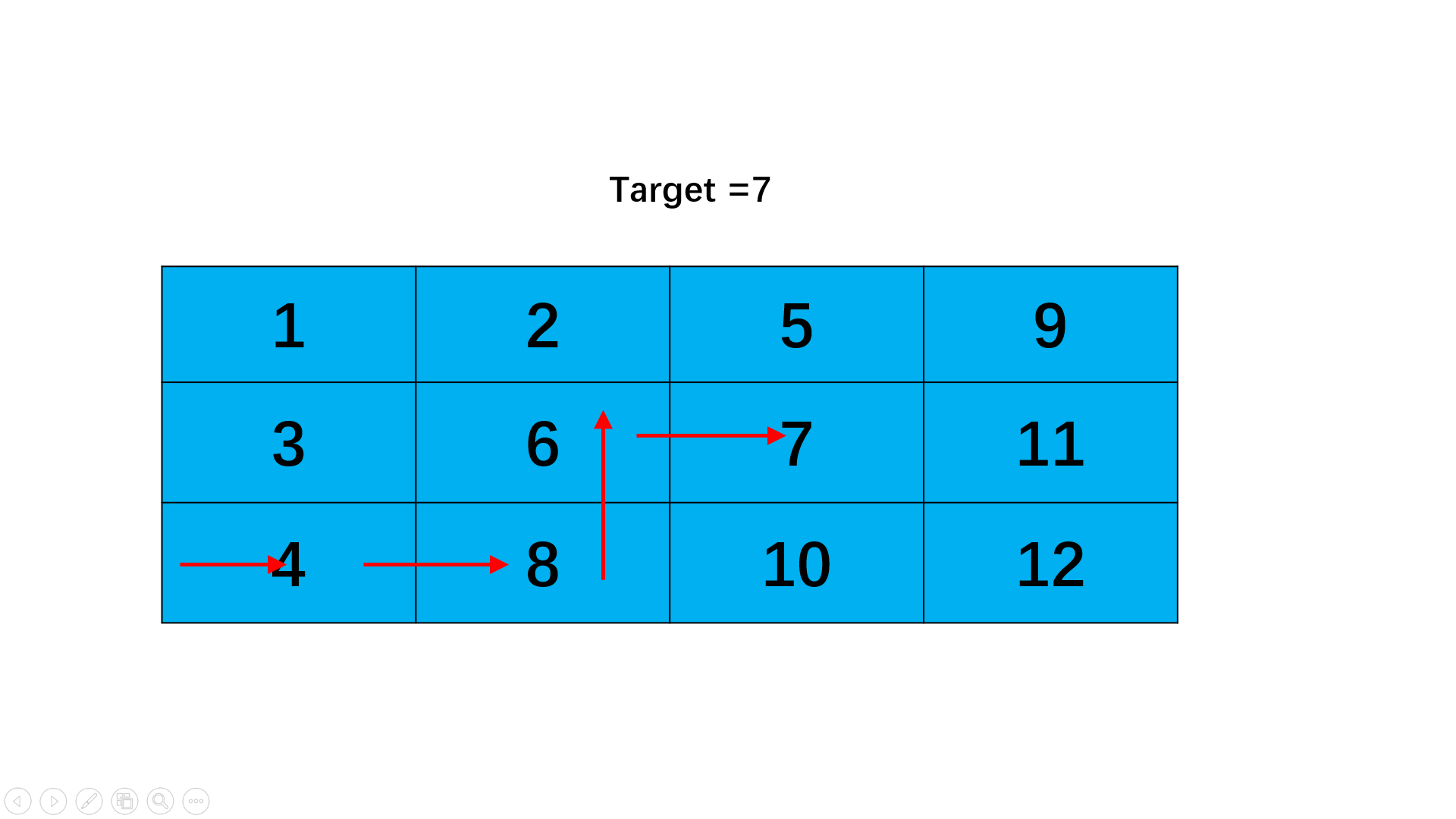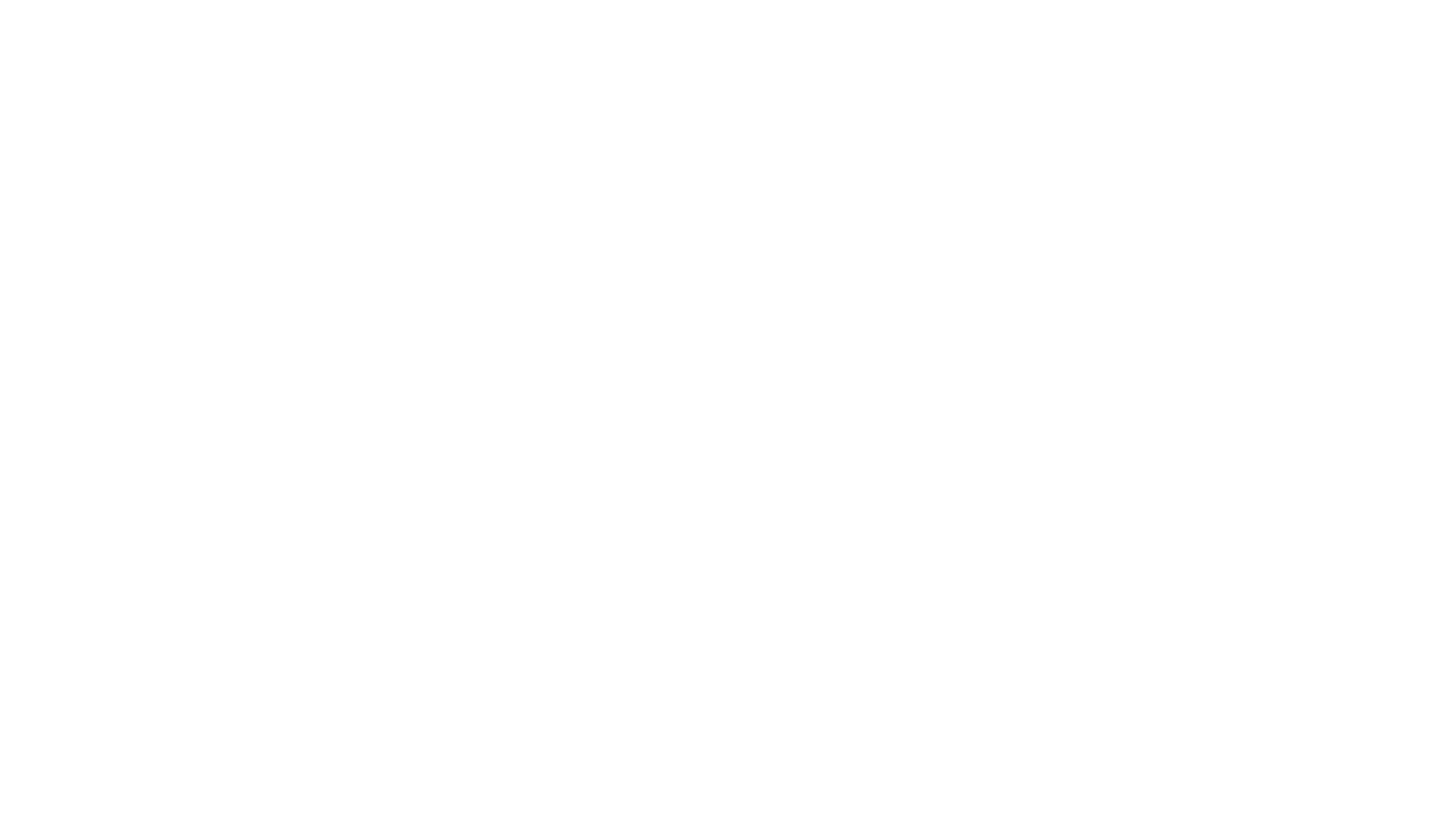
如下图所示,第一个节点是奇数位,第二个节点是偶数,第二个节点后又是奇数位,因此可以断掉节点1和节点2之间的连接,指向节点2的后面即节点3,如红色箭头。如果此时我们将第一个节点指向第三个节点,就可以得到那么第三个节点后为偶数节点,因此我们又可以断掉节点2到节点3之间的连接,指向节点3后一个节点即节点4,如蓝色箭头。那么我们再将第二个节点指向第四个节点,又回到刚刚到情况了。

//odd连接even的后一个,即奇数位 odd.next = even.next; //odd进入后一个奇数位 odd = odd.next; //even连接后一个奇数的后一位,即偶数位 even.next = odd.next; //even进入后一个偶数位 even = even.next;
具体做法
step 1:判断空链表的情况,如果链表为空,不用重排。
step 2:使用双指针odd和even分别遍历奇数节点和偶数节点,并给偶数节点链表一个头。
step 3:上述过程,每次遍历两个节点,且even在后面,因此每轮循环用even检查后两个元素是否为NULL,如果不为再进入循环进行上述连接过程。
step 4:将偶数节点头接在奇数最后一个节点后,再返回头部。
import java.util.*; /* * public class ListNode { * int val; * ListNode next = null; * public ListNode(int val) { * this.val = val; * } * } */ public class Solution { public ListNode oddEvenList (ListNode head) { //如果链表为空,不用重排 if(head == null) return head; //even开头指向第二个节点,可能为空 ListNode even = head.next; //odd开头指向第一个节点 ListNode odd = head; //指向even开头 ListNode evenhead = even; while(even != null && even.next != null){ //odd连接even的后一个,即奇数位 odd.next = even.next; //odd进入后一个奇数位 odd = odd.next; //even连接后一个奇数的后一位,即偶数位 even.next = odd.next; //even进入后一个偶数位 even = even.next; } //even整体接在odd后面 odd.next = evenhead; return head; } }
删除有序链表中重复的元素-I


import java.util.*; /* * public class ListNode { * int val; * ListNode next = null; * } */ import java.util.*; public class Solution { public ListNode deleteDuplicates (ListNode head) { //空链表 if(head == null) return null; //遍历指针 ListNode cur = head; //指针当前和下一位不为空 while(cur != null && cur.next != null){ //如果当前与下一位相等则忽略下一位 if(cur.val == cur.next.val) cur.next = cur.next.next; //否则指针正常遍历 else cur = cur.next; } return head; } }
*删除有序链表中重复的元素-II

import java.util.*; /* * public class ListNode { * int val; * ListNode next = null; * } */ public class Solution { public ListNode deleteDuplicates (ListNode head) { //空链表 if (head == null) return null; ListNode res = new ListNode(0); //在链表前加一个表头 res.next = head; ListNode cur = res; while (cur.next != null && cur.next.next != null) { //遇到相邻两个节点值相同 if (cur.next.val == cur.next.next.val) { int temp = cur.next.val; //将所有相同的都跳过 while (cur.next != null && cur.next.val == temp) cur.next = cur.next.next; } else cur = cur.next; } //返回时去掉表头 return res.next; } }
二分查找/排序
二分查找

具体做法
step 1:从数组首尾开始,每次取中点值。
step 2:如果中间值等于目标即找到了,可返回下标,如果中点值大于目标,说明中点以后的都大于目标,因此目标在中点左半区间,如果中点值小于目标,则相反。
step 3:根据比较进入对应的区间,直到区间左右端相遇,意味着没有找到。
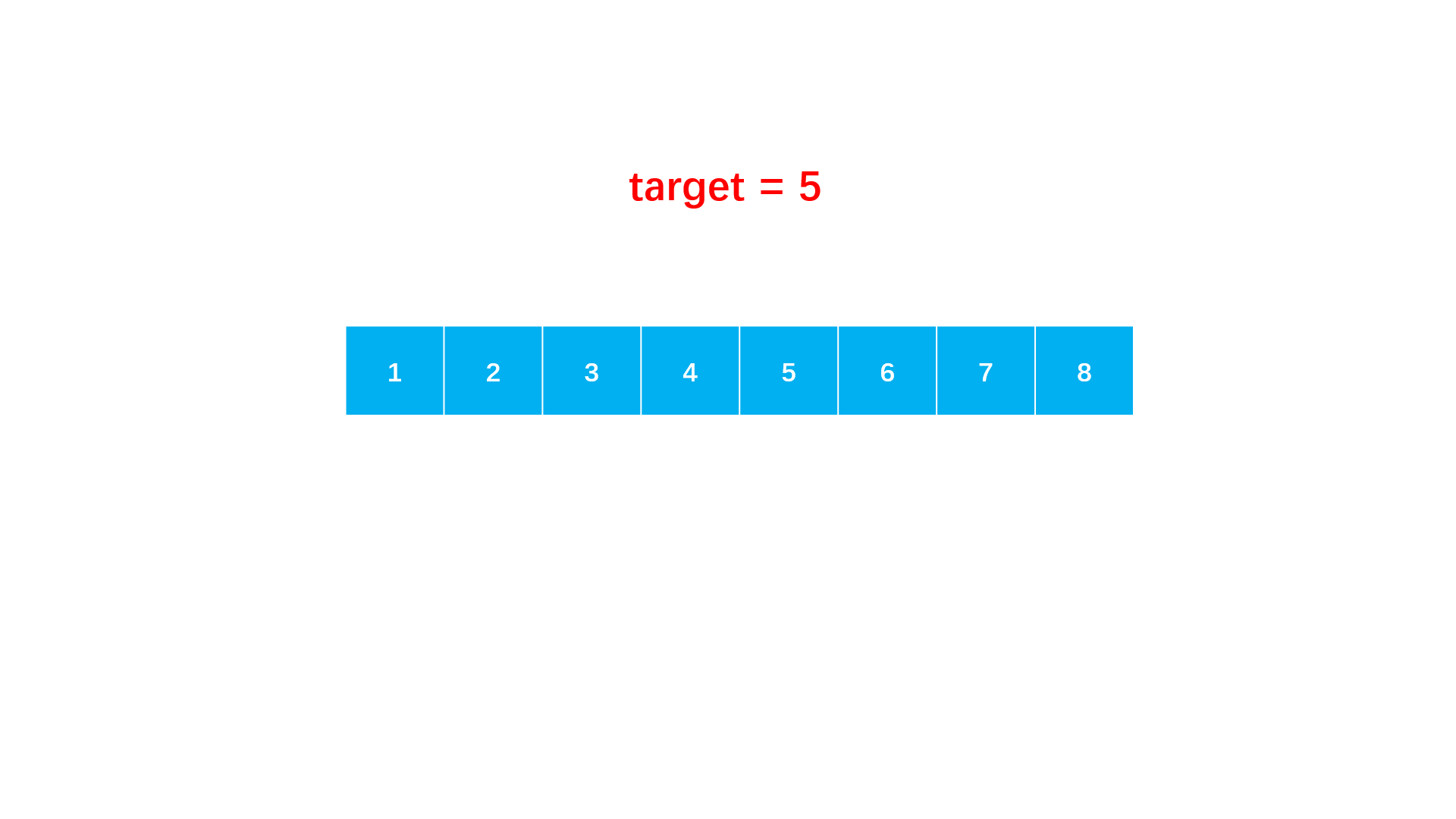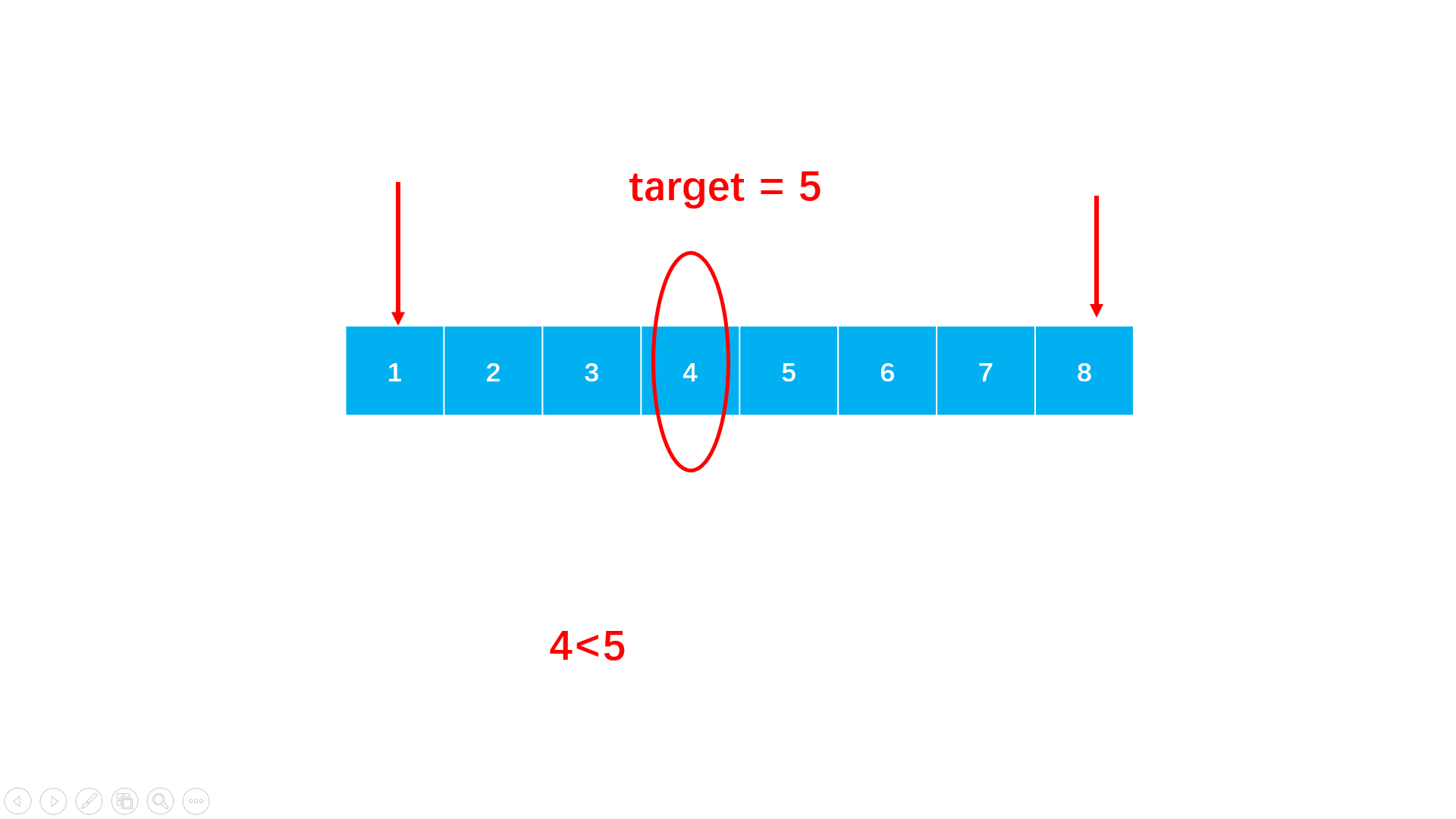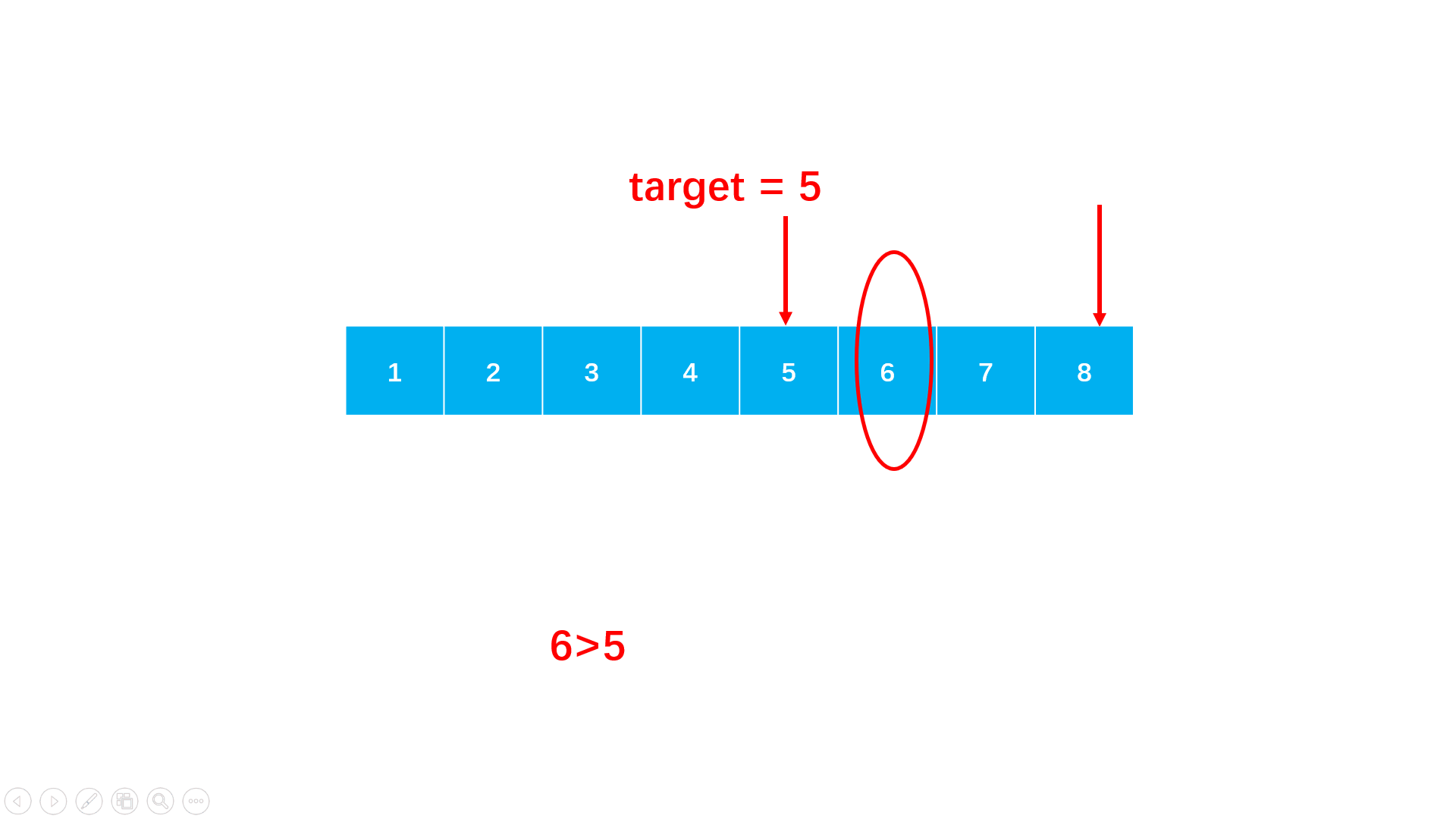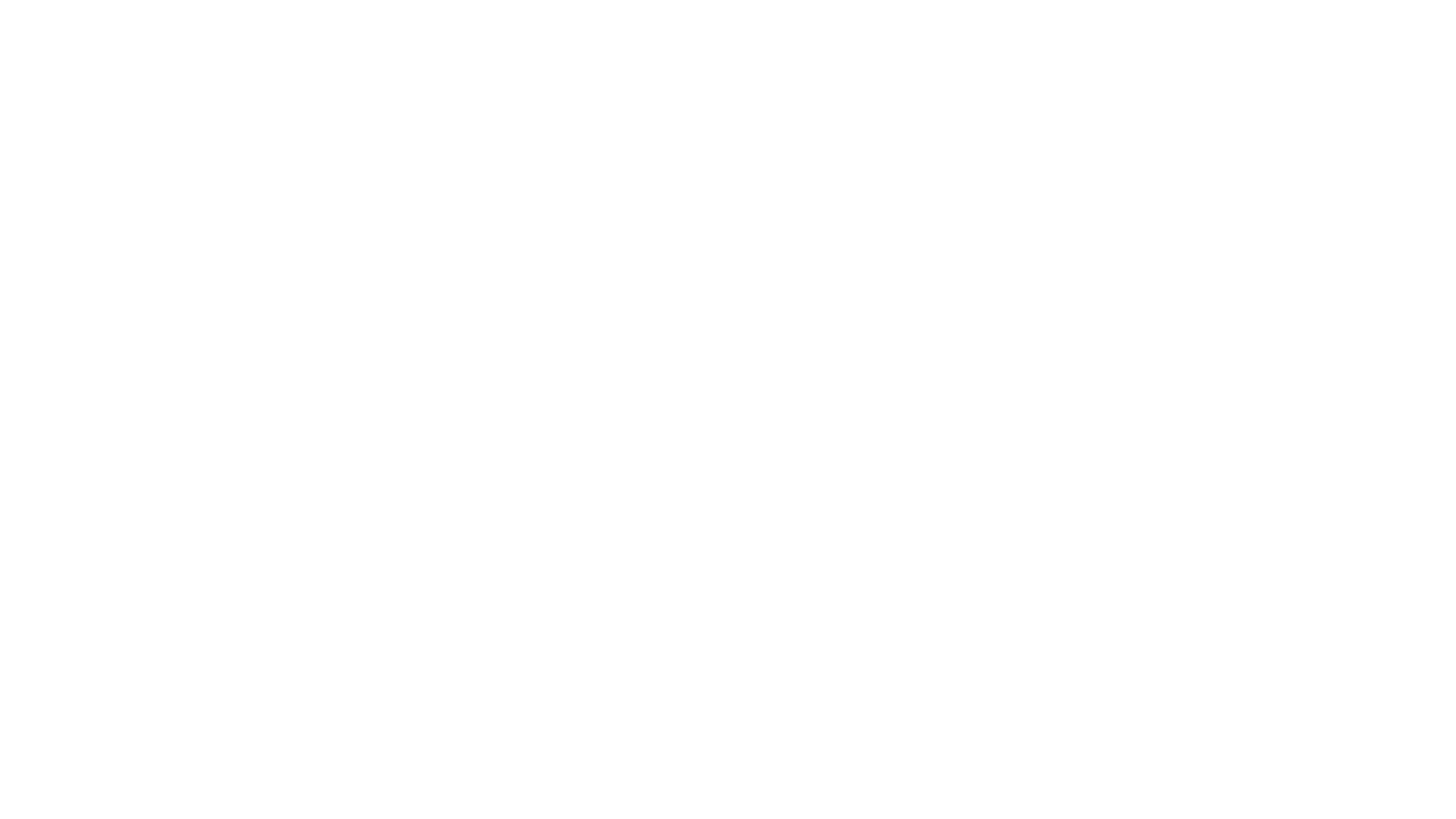
import java.util.*; public class Solution { public int search (int[] nums, int target) { int l = 0; int r = nums.length - 1; //从数组首尾开始,直到二者相遇 while (l <= r) { //每次检查中点的值 int m = (l + r) / 2; if (nums[m] == target) return m; //进入左的区间 if (nums[m] > target) r = m - 1; //进入右区间 else l = m + 1; } //未找到 return -1; } }
二维数组中的查找

首先看四个角,左上与右下必定为最小值与最大值,而左下与右上就有规律了:左下元素大于它上方的元素,小于它右方的元素,右上元素与之相反。既然左下角元素有这么一种规律,相当于将要查找的部分分成了一个大区间和小区间,每次与左下角元素比较,我们就知道目标值应该在哪部分中,于是可以利用分治思维来做。
具体做法
step 1:首先获取矩阵的两个边长,判断特殊情况。
step 2:首先以左下角为起点,若是它小于目标元素,则往右移动去找大的,若是他大于目标元素,则往上移动去找小的。
step 3:若是移动到了矩阵边界也没找到,说明矩阵中不存在目标值。
public class Solution { public boolean Find(int target, int [][] array) { //优先判断特殊(一行都没有) if (array.length == 0) return false; //获取二位数组的行数 int n = array.length; //优先判断特殊(一列都没有) if (array[0].length == 0) return false; //获取二位数组的列数 int m = array[0].length; //从最左下角的元素开始往左或往上 for (int i = n - 1, j = 0; i >= 0 && j < m; ) { //元素较大,往上走 if (array[i][j] > target) i--; //元素较小,往右走 else if (array[i][j] < target) j++; //元素等于目标值 else return true; } return false; } }
注意for循环的i >= 0 && j < m;这个条件
*寻找峰值

具体做法
step 1:二分查找首先从数组首尾开始,每次取中间值,直到首尾相遇。
step 2:如果中间值的元素大于它右边的元素,说明往右是向下,我们不一定会遇到波峰,但是那就往左收缩区间。
step 3:如果中间值大于右边的元素,说明此时往右是向上,向上一定能有波峰,那我们往右收缩区间。
step 4:最后区间收尾相遇的点一定就是波峰。

import java.util.*; public class Solution { public int findPeakElement (int[] nums) { int left = 0; int right = nums.length - 1; //二分法 while(left < right){ int mid = (left + right) / 2; //右边是往下,不一定有坡峰 if(nums[mid] > nums[mid + 1]) right = mid; //右边是往上,一定能找到波峰 else left = mid + 1; } //其中一个波峰 return right; } }
*数组中的逆序对


具体做法
step 1: 划分阶段:将待划分区间从中点划分成两部分,两部分进入递归继续划分,直到子数组长度为1.
step 2: 排序阶段:使用归并排序递归地处理子序列,同时统计逆序对,因为在归并排序中,我们会依次比较相邻两组子数组各个元素的大小,并累计遇到的逆序情况。而对排好序的两组,右边大于左边时,它大于了左边的所有子序列,基于这个性质我们可以不用每次加1来统计,减少运算次数。
step 3: 合并阶段:将排好序的子序列合并,同时累加逆序对。
public class Solution { public int mod = 1000000007; public int mergeSort(int left, int right, int [] data, int [] temp){ //停止划分 if(left >= right) return 0; //取中间 int mid = (left + right) / 2; //左右划分合并 int res = mergeSort(left, mid, data, temp) + mergeSort(mid + 1, right, data, temp); //防止溢出 res %= mod; int i = left, j = mid + 1; for(int k = left; k <= right; k++) temp[k] = data[k]; for(int k = left; k <= right; k++){ if(i == mid + 1) data[k] = temp[j++]; else if(j == right + 1 || temp[i] <= temp[j]) data[k] = temp[i++]; //左边比右边大,答案增加 else{ data[k] = temp[j++]; // 统计逆序对 res += mid - i + 1; } } return res % mod; } public int InversePairs(int [] array) { int n = array.length; int[] res = new int[n]; return mergeSort(0, n - 1, array, res); } }
旋转数组的最小数字

思路
旋转数组将原本有序的数组分成了两部分有序的数组,因为在原始有序数组中,最小的元素一定是在首位,旋转后无序的点就是最小的数字。我们可以将旋转前的前半段命名为A,旋转后的前半段命名为B,旋转数组即将AB变成了BA,我们想知道最小的元素到底在哪里。
因为A部分和B部分都是各自有序的,所以我们还是想用分治来试试,每次比较中间值,确认目标值(最小元素)所在的区间。
具体做法
step 1:双指针指向旋转后数组的首尾,作为区间端点。
step 2:若是区间中点值大于区间右界值,则最小的数字一定在中点右边。
step 3:若是区间中点值等于区间右界值,则是不容易分辨最小数字在哪半个区间,比如[1,1,1,0,1],应该逐个缩减右界。
step 4:若是区间中点值小于区间右界值,则最小的数字一定在中点左边。
step 5:通过调整区间最后即可锁定最小值所在。

import java.util.ArrayList; public class Solution { public int minNumberInRotateArray(int [] array) { int left = 0; int right = array.length - 1; while (left < right) { int mid = (left + right) / 2; //最小的数字在mid右边 if (array[mid] > array[right]) left = mid + 1; //无法判断,一个一个试 else if (array[mid] == array[right]) right--; //最小数字要么是mid要么在mid左边 else right = mid; } return array[left]; } }
*比较版本号

具体做法
step 1:利用两个指针表示字符串的下标,分别遍历两个字符串。
step 2:每次截取点之前的数字字符组成数字,即在遇到一个点之前,直接取数字,加在前面数字乘10的后面。(因为int会溢出,这里采用long记录数字)
step 3:然后比较两个数字大小,根据大小关系返回1或者-1,如果全部比较完都无法比较出大小关系,则返回0.

import java.util.*; public class Solution { public int compare (String version1, String version2) { int n1 = version1.length(); int n2 = version2.length(); int i = 0, j = 0; //直到某个字符串结束 while(i < n1 || j < n2){ long num1 = 0; //从下一个点前截取数字 while(i < n1 && version1.charAt(i) != '.'){ num1 = num1 * 10 + (version1.charAt(i) - '0'); i++; } //跳过点 i++; long num2 = 0; //从下一个点前截取数字 while(j < n2 && version2.charAt(j) != '.'){ num2 = num2 * 10 + (version2.charAt(j) - '0'); j++; } //跳过点 j++; //比较数字大小 if(num1 > num2) return 1; if(num1 < num2) return -1; } //版本号相同 return 0; } }
二叉树
二叉树的前序遍历

这里的#应该只是区分根节点和其他节点的,不是数组的内容
思路
我们都知道递归,是不断调用自己,计算内部实现递归的时候,是将之前的父问题存储在栈中,先去计算子问题,等到子问题返回给父问题后再从栈中将父问题弹出,继续运算父问题。因此能够递归解决的问题,我们似乎也可以用栈来试一试。
根据前序遍历“根左右”的顺序,首先要遍历肯定是根节点,然后先遍历左子树,再遍历右子树。递归中我们是先进入左子节点作为子问题,等左子树结束,再进入右子节点作为子问题。
这里我们同样可以这样做,它无非相当于把父问题挂进了栈中,等子问题结束再从栈中弹出父问题,从父问题进入右子树,我们这里已经访问过了父问题,不妨直接将右子节点挂入栈中,然后下一轮先访问左子节点。要怎么优先访问左子节点呢?同样将它挂入栈中,依据栈的后进先出原则,下一轮循环必然它要先出来,如此循环,原先父问题的右子节点被不断推入栈深处,只有左子树全部访问完毕,才会弹出继续访问。
具体做法
step 1:优先判断树是否为空,空树不遍历。
step 2:准备辅助栈,首先记录根节点。
step 3:每次从栈中弹出一个元素,进行访问,然后验证该节点的左右子节点是否存在,存的话的加入栈中,优先加入右节点。
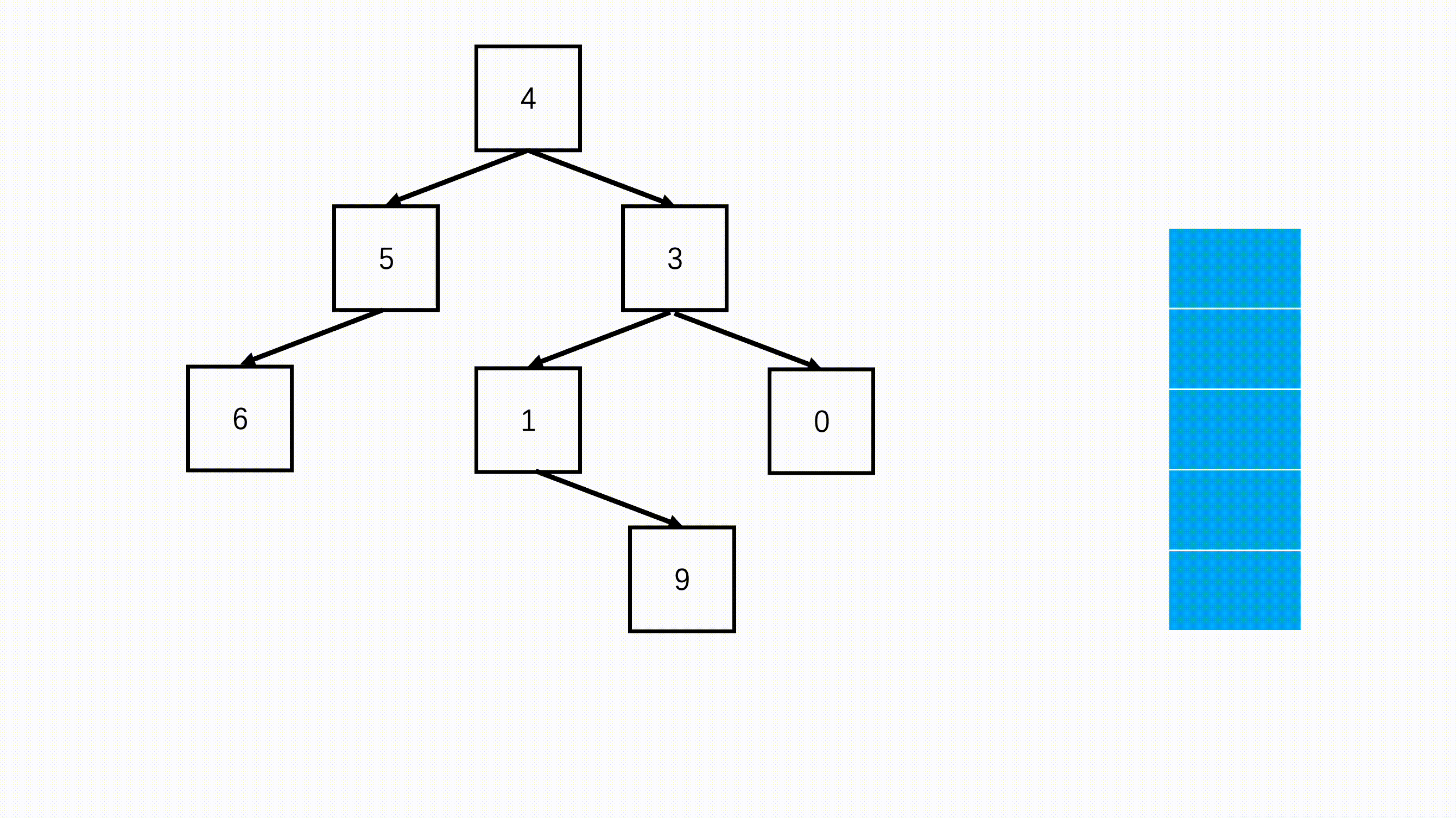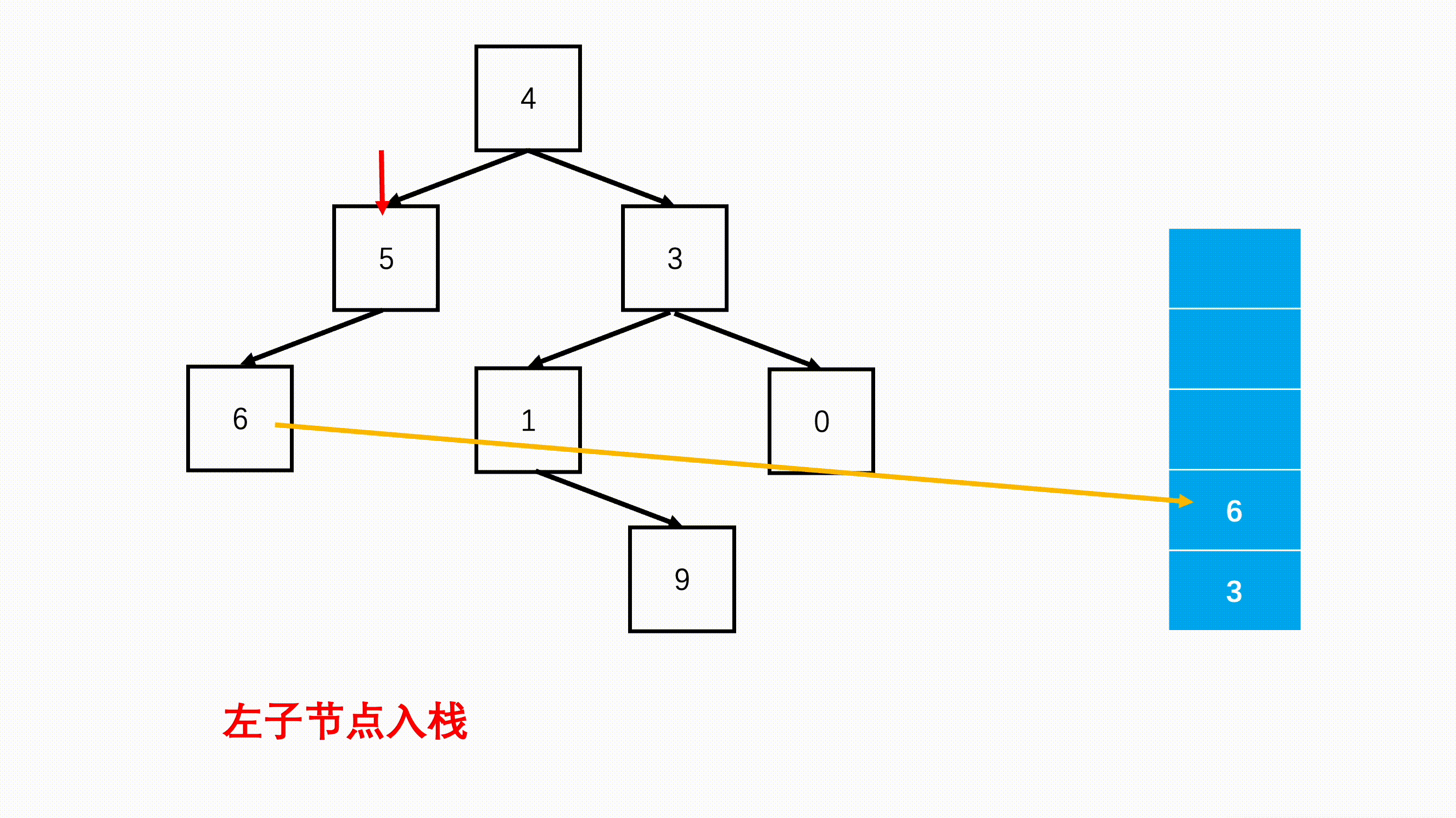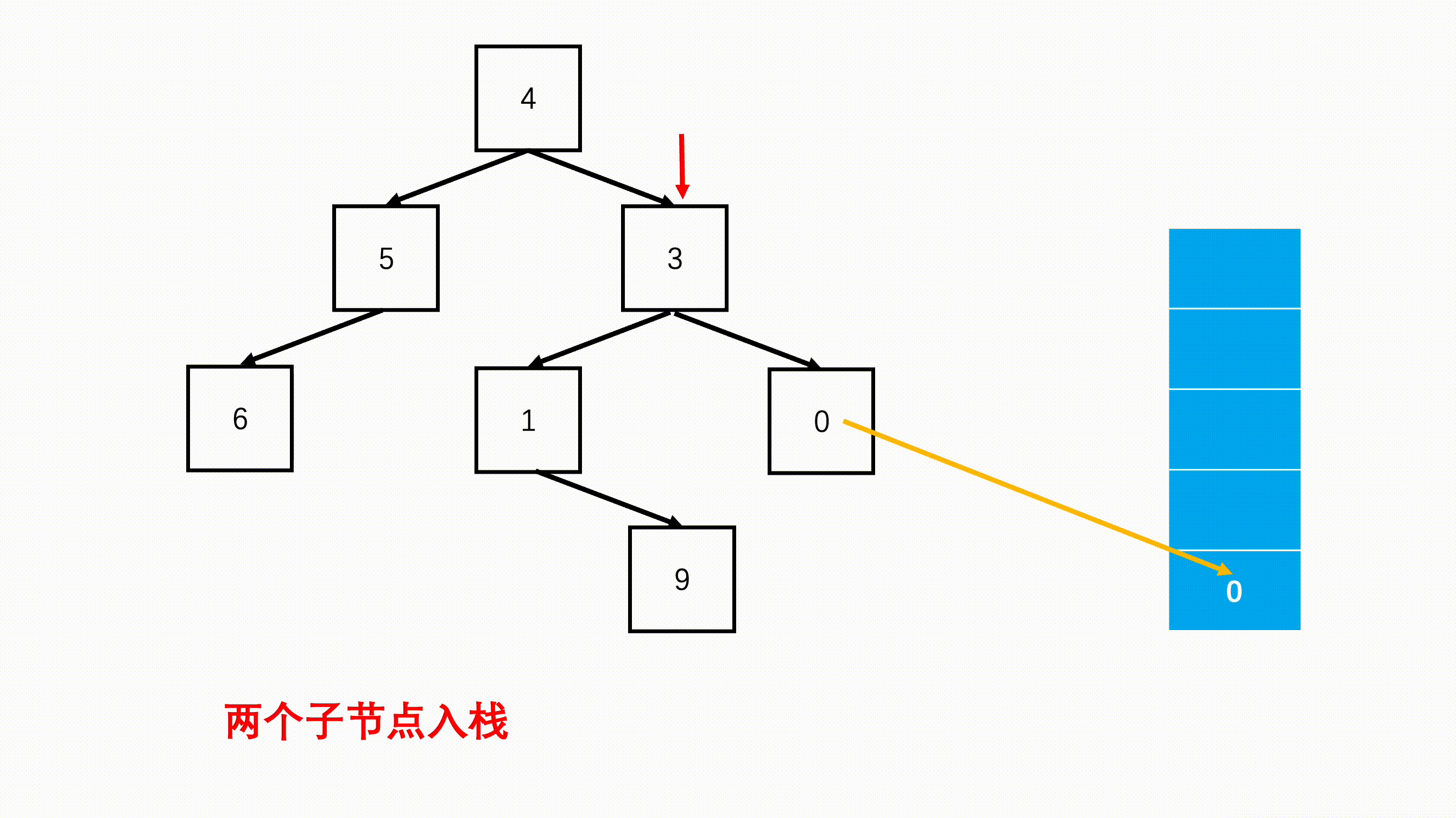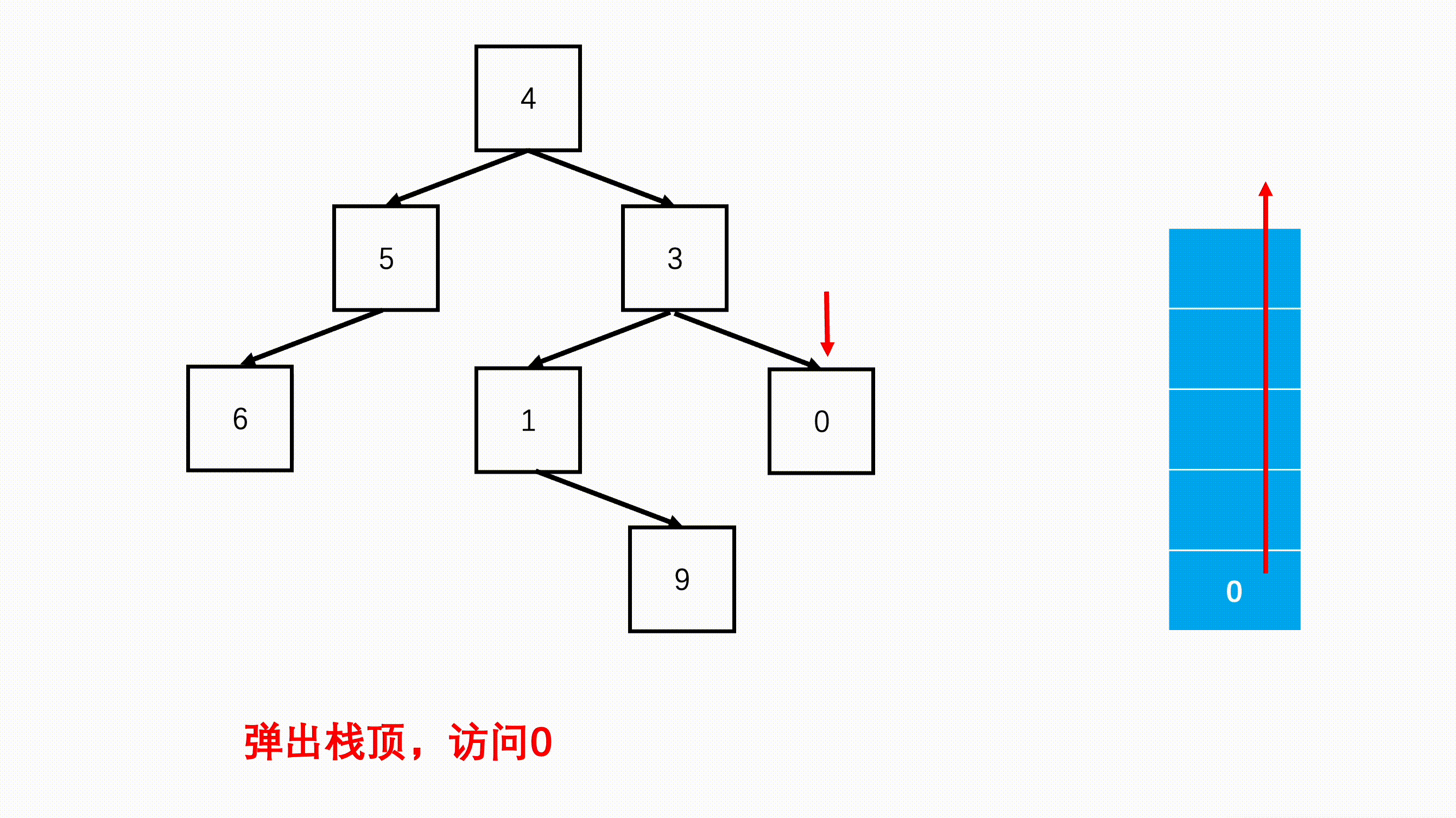
import java.util.*; /* * public class TreeNode { * int val = 0; * TreeNode left = null; * TreeNode right = null; * public TreeNode(int val) { * this.val = val; * } * } */ public class Solution { public int[] preorderTraversal (TreeNode root) { //添加遍历结果的数组 List<Integer> list = new ArrayList(); Stack<TreeNode> s = new Stack<TreeNode>(); //空树返回空数组 if(root == null) return new int[0]; //根节点先进栈 s.push(root); while(!s.isEmpty()){ //每次栈顶就是访问的元素 TreeNode node = s.pop(); list.add(node.val); //如果右边还有右子节点进栈 if(node.right != null) s.push(node.right); //如果左边还有左子节点进栈 if(node.left != null) s.push(node.left); } //返回的结果 int[] res = new int[list.size()]; for(int i = 0; i < list.size(); i++) res[i] = list.get(i); return res; } }


