

多智能体强化学习 (MARL) 是一个具有挑战性的问题,它不仅需要识别每个智能体的策略改进方向,而且还需要将单个智能体的策略更新联合起来,以提高整体性能。最近,这一问题得到初步解决,有研究人员引入了集中训练分散执行 (CTDE) 的方法,使智能体在训练阶段可以访问全局信息。然而,这些方法无法涵盖多智能体交互的全部复杂性。
事实上,其中一些方法还被证明是失败的。为了解决这个问题,有人提出多智能体优势分解定理。在此基础上,HATRPO 和 HAPPO 算法被推导出来。然而,这些方法也存在局限性,这些方法仍然依赖于精心设计的最大化目标。
近年来,序列模型(SM)在自然语言处理(NLP)领域取得了实质性进展。如 GPT 系列、BERT 在广泛的下游任务上表现出色,并且在小样本泛化任务上取得了较强的性能。
由于序列模型与语言的序列特性自然契合,因此可用于语言任务,但是序列方法不仅限于 NLP 任务,而是一种广泛适用的通用基础模型。例如,在计算机视觉 (CV) 中,可以将图像分割成子图并将它们按序列排列,就好像它们是 NLP 任务中的 token 一样 。近期比较出名的模型 Flamingo、DALL-E 、 GATO 等都有序列方法的影子。
随着 Transformer 等网络架构的出现,序列建模技术也引起了 RL 社区的极大关注,这促进了一系列基于 Transformer 架构的离线 RL 开发。这些方法在解决一些最基本的 RL 训练问题方面显示出了巨大的潜力。
尽管这些方法取得了显著的成功,但没有一种方法被设计用来建模多智能体系统中最困难 (也是 MARL 独有的) 的方面——智能体之间的交互。事实上,如果简单地赋予所有智能体一个 Transformer 策略,并对其进行单独训练,这仍然不能保证能提高 MARL 联合性能。因此,虽然有大量强大的序列模型可用,但 MARL 并没有真正利用序列模型性能优势。
如何用序列模型解决 MARL 问题?来自上海交通大学、Digital Brain Lab、牛津大学等的研究者提出一种新型多智能体 Transformer(MAT,Multi-Agent Transformer)架构,该架构可以有效地将协作 MARL 问题转化为序列模型问题,其任务是将智能体的观测序列映射到智能体的最优动作序列。
本文的目标是在 MARL 和 SM 之间建立桥梁,以便为 MARL 释放现代序列模型的建模能力。MAT 的核心是编码器 - 解码器架构,它利用多智能体优势分解定理,将联合策略搜索问题转化为序列决策过程,这样多智能体问题就会表现出线性时间复杂度,最重要的是,这样做可以保证 MAT 单调性能提升。与 Decision Transformer 等先前技术需要预先收集的离线数据不同,MAT 以在线策略方式通过来自环境的在线试验和错误进行训练。

- 论文地址:https://arxiv.org/pdf/2205.14953.pdf
- 项目主页:https://sites.google.com/view/multi-agent-transformer
为了验证 MAT,研究者在 StarCraftII、Multi-Agent MuJoCo、Dexterous Hands Manipulation 和 Google Research Football 基准上进行了广泛的实验。结果表明,与 MAPPO 和 HAPPO 等强基线相比,MAT 具有更好的性能和数据效率。此外,该研究还证明了无论智能体的数量如何变化,MAT 在没见过的任务上表现较好,可是说是一个优秀的小样本学习者。
背景知识
在本节中,研究者首先介绍了协作 MARL 问题公式和多智能体优势分解定理,这是本文的基石。然后,他们回顾了现有的与 MAT 相关的 MARL 方法,最后引出了 Transformer。

传统多智能体学习范式(左)和多智能体序列决策范式(右)的对比。
问题公式
协作 MARL 问题通常由离散的部分可观察马尔可夫决策过程(Dec-POMDPs) 来建模。
来建模。
多智能体优势分解定理
智能体通过 Q_π(o, a)和 V_π(o)来评估行动和观察的值,定义如下。

定理 1(多智能体优势分解):令 i_1:n 为智能体的排列。如下公式始终成立,无需进一步假设。

重要的是,定理 1 提供了一种用于指导如何选择渐进式改进行动的直觉。
现有 MARL 方法
研究者总结了目前两种 SOTA MARL 算法,它们都构建在近端策略优化(Proximal Policy Optimization, PPO)之上。PPO 是一种以简洁性和性能稳定性闻名的 RL 方法。
多智能体近端策略优化(MAPPO)是首个将 PPO 应用于 MARL 中的最直接方法。

异构智能体近端策略优化(HAPPO)是目前的 SOTA 算法之一,它可以充分利用定理 (1) 以实现具有单调提升保证的多智能体信任域学习。

Transformer 模型
基于定理 (1) 中描述的序列属性以及 HAPPO 背后的原理,现在可以直观地考虑用 Transformer 模型来实现多智能体信任域学习。通过将一个智能体团队视作一个序列,Transformer 架构允许建模具有可变数量和类型的智能体团队,同时可以避免 MAPPO/HAPPO 的缺点。
多智能体 Transformer
为了实现 MARL 的序列建模范式,研究者提供的解决方案是多智能体 Transformer(MAT)。应用 Transformer 架构的思路源于这样一个事实,即智能体观察序列 (o^i_1,...,o^i_n) 输入与动作序列(a^ i_1 , . . . , a^i_n)输出之间的映射是类似于机器翻译的序列建模任务。正如定理 (1) 所回避的,动作 a^i_m 依赖于先前所有智能体的决策 a ^i_1:m−1。
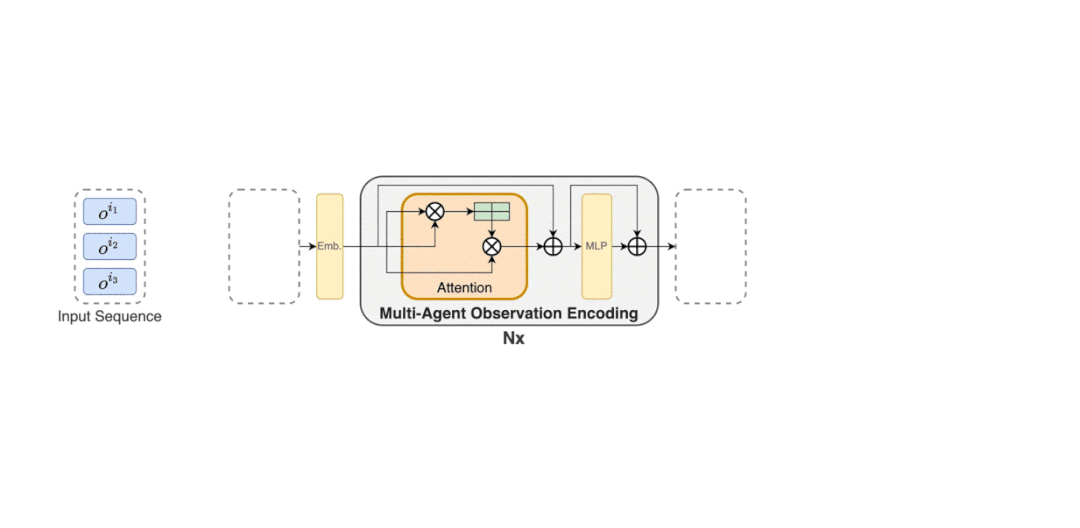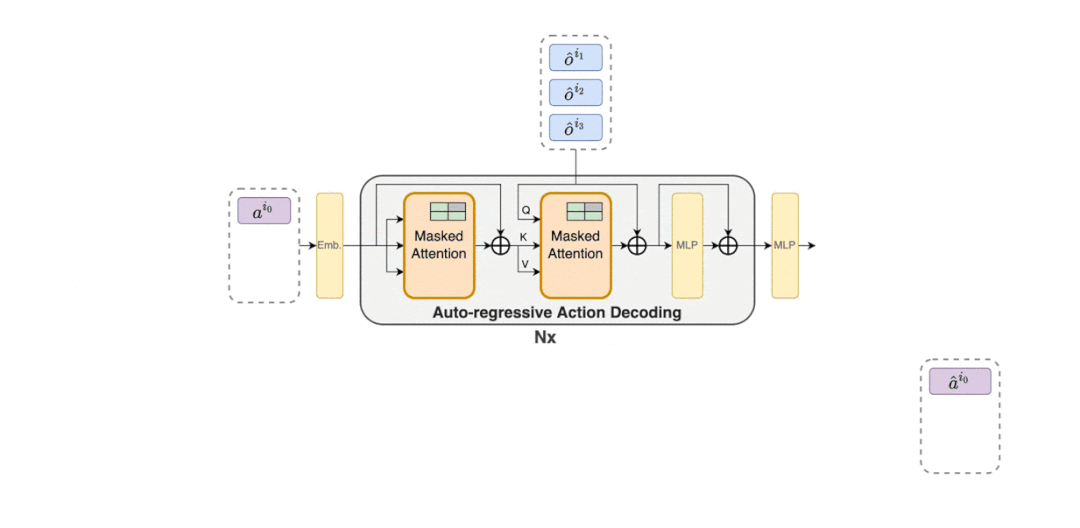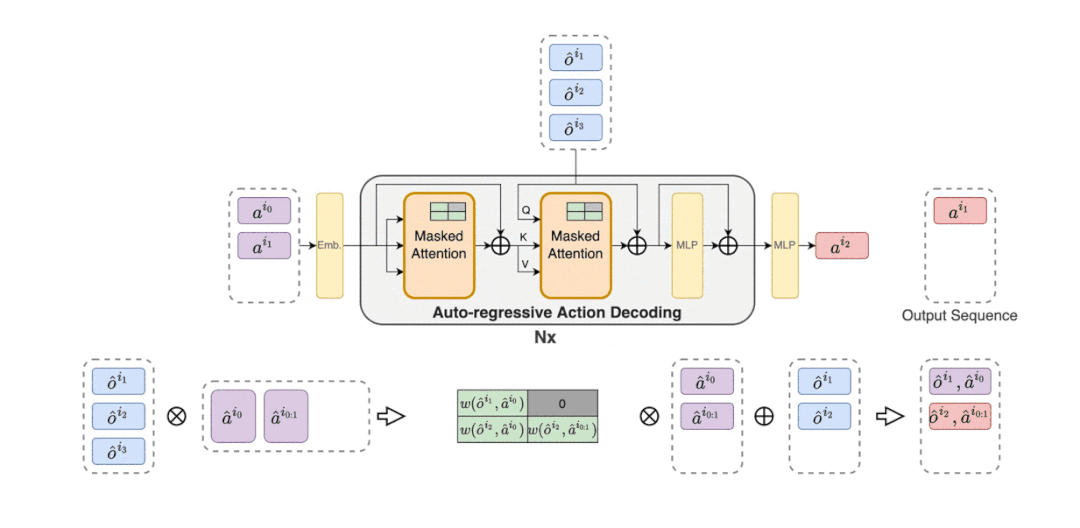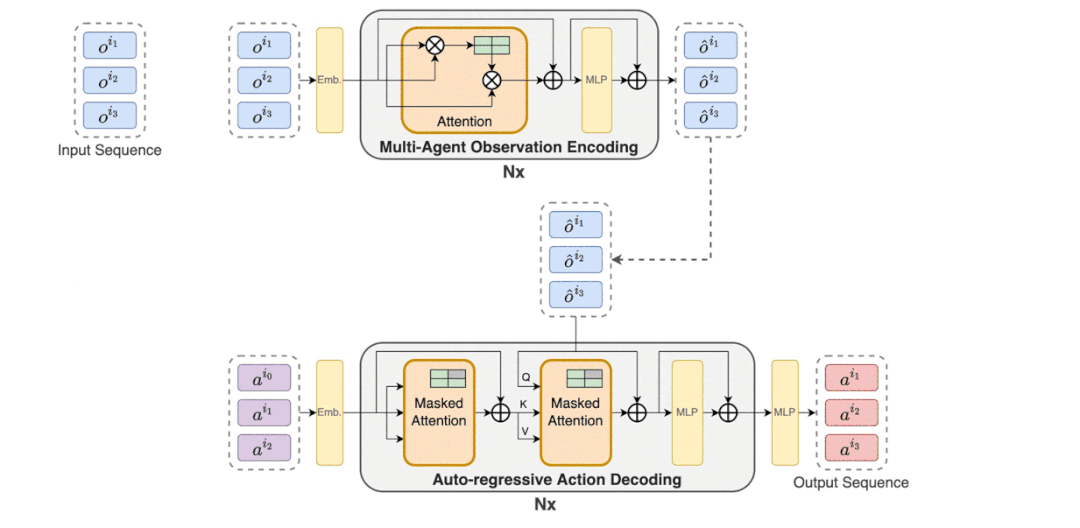
因此,如下图(2)所示,MAT 中包含了一个用于学习联合观察表示的编码器和一个以自回归方式为每个智能体输出动作的解码器。

编码器的参数用φ 表示,它以任意顺序获取观察序列(o^i_1 , . . . , o^i_n),并将它们传递通过几个计算块。每个块都由一个自注意力机制、一个多层感知机(MLP)和残差连接组成,以防止随深度增加出现梯度消失和网络退化。
解码器的参数用θ表示,它将嵌入的联合动作 a^i_0:m−1 , m = {1, . . . n}(其中 a^i_0 是指示解码开始的任意符号)传递到解码块序列。至关重要的是,每个解码块都有一个掩码的自注意力机制。为了训练解码器,研究者将如下裁剪 PPO 目标最小化。

MAT 中的详细数据流如下动图所示。
实验结果
为了评估 MAT 是否符合预期,研究者在星际争霸 II 多智能体挑战(SMAC)基准(MAPPO 在之上具有优越性能)和多智能体 MuJoCo 基准上(HAPPO 在之上具有 SOTA 性能)对 MAT 进行了测试。
此外,研究者还在 Bimanual Dxterous Hand Manipulation (Bi-DexHands)和 Google Research Football 基准上了对 MAT 进行了扩展测试。前者提供了一系列具有挑战性的双手操作任务,后者提供了一系列足球游戏中的合作场景。
最后,由于 Transformer 模型通常在小样本任务上表现出强大的泛化性能,因此研究者相信 MAT 在未见过的 MARL 任务上也能具有类似强大的泛化能力。因此,他们在 SMAC 和多智能体 MuJoCo 任务上设计了零样本和小样本实验。
协作 MARL 基准上的性能
如下表 1 和图 4 所示,对于 SMAC、多智能体 MuJoCo 和 Bi-DexHands 基准来说,MAT 在几乎所有任务上都显著优于 MAPPO 和 HAPPO,表明它在同构和异构智能体任务上强大的构建能力。此外,MAT 还得到了优于 MAT-Dec 的性能,表明了 MAT 设计中解码器架构的重要性。


同样地,研究者在 Google Research Football 基准上也得到了类似的性能结果,如下图 5 所示。

MAT 用于小样本学习
表 2 和表 3 中总结了每种算法的零样本和小样本结果,其中粗体数字表示最佳性能。
研究者还提供了数据相同情况下 MAT 的性能,其与对照组一样从头开始训练。如下表所示,MAT 获得了大多数最好成绩,这证明了 MAT 小样本学习的强大泛化性能。



