


新智元报道
编辑:Aeneas 昕朋
【新智元导读】2022年有哪些人工智能的突破?今天,李飞飞高徒Jim Fan盘点了年度十大AI亮点。
人工智能的爆炸正在扭曲我们的时间感。
你能相信Stable Diffusion只有4个月大,而ChatGPT的出现还不到一个月吗?
打个形象的比喻,只要眨一下眼,你就会错过一个全新的行业。
2022年的AI领域,大规模的生成模型像雨后春笋一样地冒出,改变了整个AI界的格局。
而且,这些模型正在迅速走出实验室,在现实中被应用。
比如,LLM技术就启发了两个新兴的领域——决策代理(游戏、机器人等等)和 AI4Science。
李飞飞高徒Jim Fan为我们总结了2022年的十大AI高光时刻。让我们把时间倒转,看看2022年都有哪些令人惊叹的AI突破。

一、文字-图像生成
DALLE-2是第一个可以从任意标题生成逼真的高分辨率图像的大规模扩散模型。
它启动了AI的艺术革命,催生了许多新的应用程序、初创公司和思维方式。

但 DALLE-2被保护在OpenAI的围墙后面,并没有开源。在OpenAI之后,LMU的StabilityAI和runwayml迈出了英勇的一步,基于「潜在扩散」算法训练了他们自己的互联网规模的text2image模型。他们称该模型为「稳定扩散」,并开源了代码和权值(weighs)。

事实证明,Stable Diffusion的开放性,让它给游戏带来了巨变。现在,许多初创公司和研究实验室都在Stable Diffusion的基础上创建新的应用程序,Stable Diffusion本身也被开源社区不断改进。最近,Stable Diffusion已经达到了v2.1版本,可以在单个GPU上运行了。 另外,今年还有来自GoogleAI的两个image2text模型。GoogleAI既没有发布模型也没有发布API,但从论文中,我们仍然可以看到不少有趣的见解。
另外,今年还有来自GoogleAI的两个image2text模型。GoogleAI既没有发布模型也没有发布API,但从论文中,我们仍然可以看到不少有趣的见解。
Imagen
https://imagen.research.google

Parti
https://parti.research.google。它是一个没有diffusion的Transformer模型。

二、文字-文字生成
大家都知道,我说的是ChatGPT!
这是历史上唯一一个在5天内就获得了100万用户的应用程序。ChatGPT也大大启发了我们人类的创造力。在这个列表中,可以看到所有有用的和有想象力的关于ChatGPT想法:https://github.com/f/awesome-chat ChatGPT和GPT-3.5都使用了一种叫做RLHF(「从人类反馈中强化学习」)的新技术。这也就意味着,提示工程或许很快就会消失了。
ChatGPT和GPT-3.5都使用了一种叫做RLHF(「从人类反馈中强化学习」)的新技术。这也就意味着,提示工程或许很快就会消失了。 ChatGPT的流行,已经催生了一波新的创业公司和竞争者,比如Jasper Chat、YouChat、Replit的Ghostwriter chat,以及perplexity_ai。这些竞争者提供了如此直观的搜索方式,连谷歌的高管们都开始出汗了!
ChatGPT的流行,已经催生了一波新的创业公司和竞争者,比如Jasper Chat、YouChat、Replit的Ghostwriter chat,以及perplexity_ai。这些竞争者提供了如此直观的搜索方式,连谷歌的高管们都开始出汗了!
三、文本- 机器人模型
如何给GPT提供胳膊和腿,让它们能打扫你混乱的厨房?
与NLP不同,机器人模型需要与物理世界互动。在今年,大的预训练Transformer终于开始解决机器人领域最难的问题了!
VIMA
10月,我和同事创建了一个 「机器人GPT 」——名为VIMA的tranformer。它可以接收任何混合的文本、图像和视频作为prompt,并输出机器人手臂的控制。我们的模型被称为VIMA(「VisuoMotor Attention」),已经完全开源了。现在,单个智能体已经能够解决视觉目标、视频的一次性模仿、新概念基础、视觉约束等,具有了模型容量和数据的强大扩展性。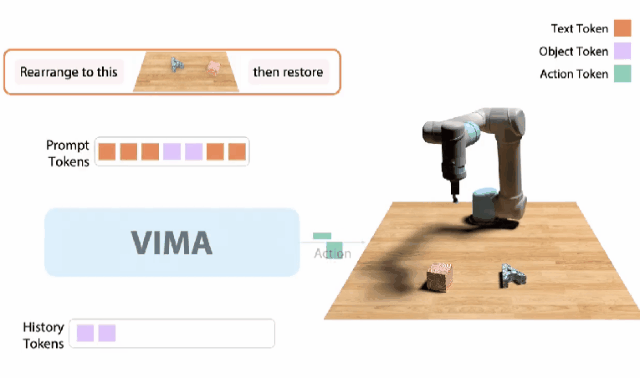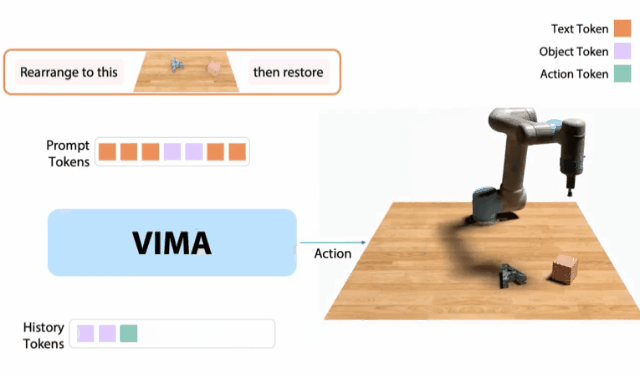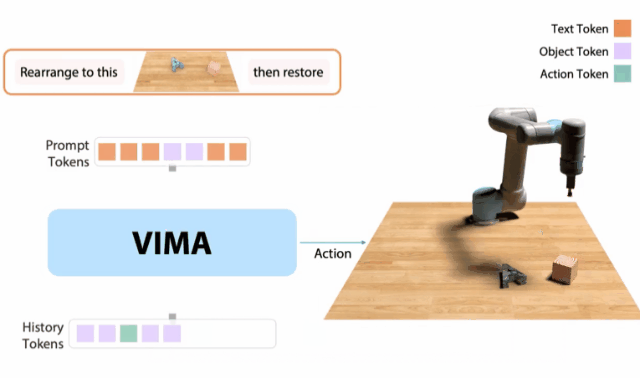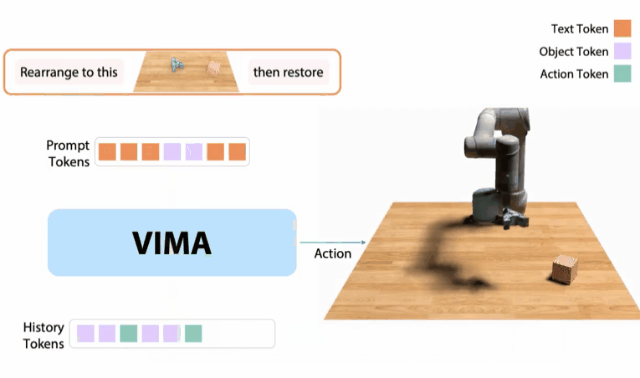
RT-1
沿着与VIMA类似的路径,来自GoogleAI的研究人员发布了RT-1,这是一种在700项任务和130K的人类演示上训练的机器人transformer。这些数据是由13个机器人在17个月内收集的,是字面意义上的钢铁部队!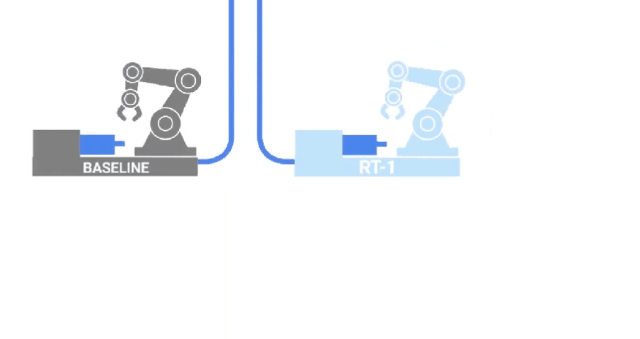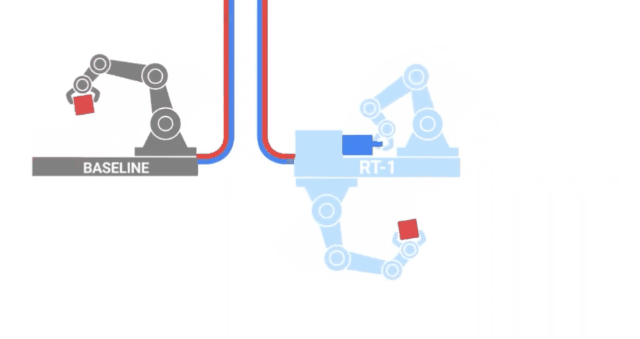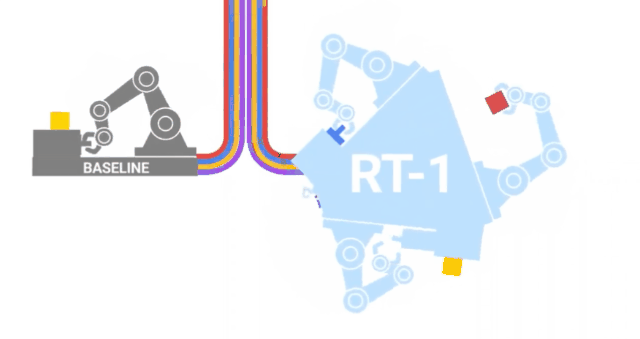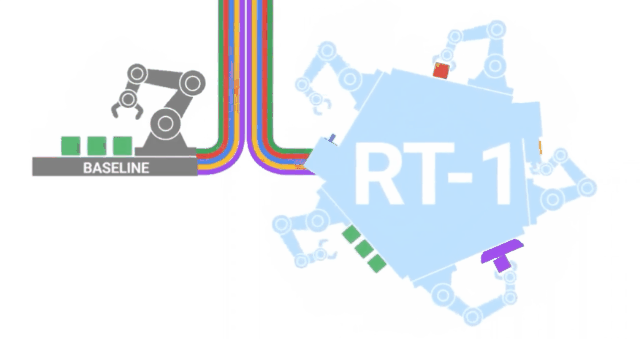
四、文本 - 视频
本质上说,视频就是随着时间的推移捆绑在一起的一系列图像,给我们创造了运动的错觉。
如果我们可以做text2image,那为什么不在里面加上时间轴,来获得额外的乐趣呢?目前,文本 - 视频领域有3个重大的工作,但没有一个是开源的。
Make-A-Video
首先是Meta AI的Make-A-Video:不需要成对的文本-视频数据,就可以得到文本-视频的生成。您可以在此处注册试用访问权限:https://makeavevideo.studio

论文链接:https://arxiv.org/abs/2209.14792



