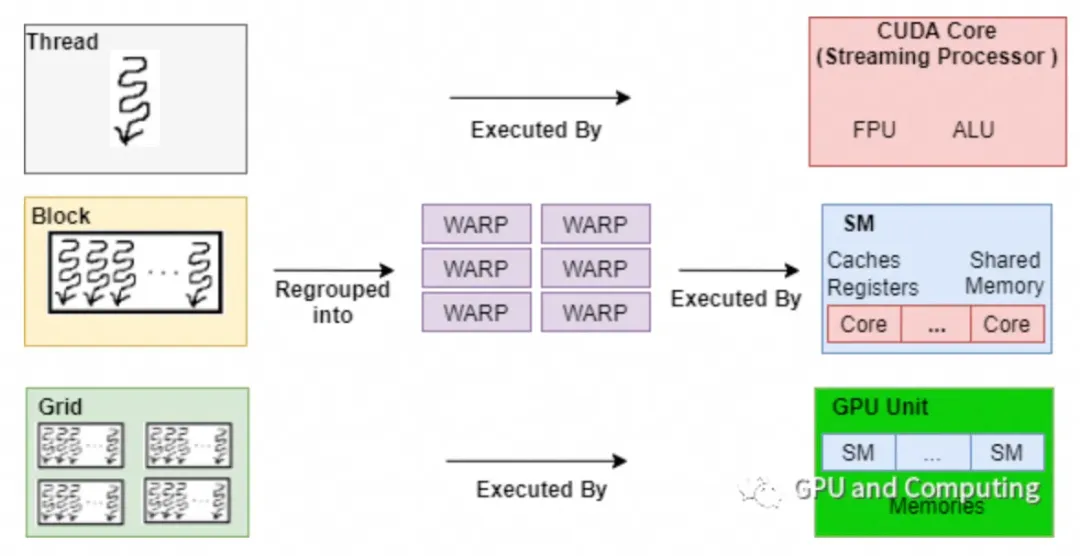
2023年3月23日14:00(中国时间),NVIDIA GTC开发者大会阿里云开发者社区观看入口正式开放,阿里云高级技术专家李伟男;阿里云弹性计算产品专家宋迪共同带来了题为《基于阿里云eRDMA的GPU实例大幅提升多机训练性能》的分享,以下是他们的演讲内容整理:

eRDMA基于RDMA技术研发,RDMA具有的特性和优势在eRDMA上同样适用。
最初,RDMA技术的出现以及被广泛应用,得益于其相对于传统的TCP网络通信协议有着明显的优势。数据从内存到网卡的搬移不再需要CPU的持续介入,而是通过集成在物理网卡中的DMA引擎,通过直接内存访问的方式完成数据搬移。同时,在搬移过程中避免了频繁的用户态和内核态切换,由应用层直接触发物理网卡上的DMA访问,从而大幅节约了CPU的开销,降低了延时,最终大幅提升了通讯效率。
在服务器节点间的数据通信过程中,CPU仅负责指定RDMA通信的源及目的物理地址,并触发通信动作,其余工作全部由物理网卡上的DMA引擎负责完成。
相比传统的TCP通信,近端及远端的物理网卡通过协作可以直接将本地的内存数据写入远端的内存地址空间,或从远端的物理内存空间读取数据到本地内存,待数据传输全部完成后,再通知CPU进行下一步动作,将数据传输和计算分开,从而实现高效的并行计算处理。

RDMA高效处理分布式节点间的内存数据搬移,其本质是DMA的访问。
DMA引擎同样可以对设备地址进行直接访问。在异构计算的应用场景中,服务器节点间同步的不仅是内存的数据,还有GPU显存的数据。GDR便是为了实现物理绑卡在服务节点间直接搬移GPU显存的数据而实现。
为了支持该功能,NVIDIA的GPU驱动提供了一套标准接口,用于获取应用层申请的显存对应的物理地址。物理网卡可以使用这一物理地址完成DMA的直接访问。该部分详细的实现以及应用实例代码可以在NVIDIA的官网上获取到。
GPU作为标准的PCI设备,根据物理服务器的硬件拓扑结构不同,与RDMA设备通信的链路也会有很大不同。如上图所示,展示了不同的硬件拓扑结构下GDR通信的链路以及效率的对比。
RDMA设备与上图中的GPU1连接在同一PCIe Switch下,两者之间的通信通过PCIe Switch即可完成。该种类型被称为PIX通信,通讯效率最好。
而RDMA设备和GPU2位于两个不同的Root Complex下,两者之间的通信需要穿过两个PCIe Switch以及两个RC。该种类型的通信被称为PHB,通讯效率会受到影响。
RDMA设备与GPU3的距离更远,它位于两个CPU的socket下,两者之间的通信需要穿过CPU之间的UPI通道才能完成。该种通信的类型被命名为SYS,效率最差。在一些CPU架构上能够支持这一级别的GDR,但在实际使用中需要根据实际应用情况进行权衡,选择打开或关闭。

eRDMA技术由阿里云在2021年云栖大会发布,与RDMA生态完全兼容。在RDMA环境中运行的应用层代码可实现无修改、直接迁移至eRDMA环境中。
另外,其基于阿里云弹性VPC的特点,可以支持更高的弹性扩展,同时可以复用VPC网络的租户隔离,实现数据通信安全。在VPC网络覆盖的区域均可以实现eRDMA组网,突破集群限制,实现近10万级的超大规模组网。
eRDMA基于第四代神龙CIPU,带宽可达200G,可以通过扩展硬件的方式实现更高的带宽,极限时延可低至5us,吞吐量可达到30M数据包/s。

如何在阿里云弹性计算实例中激活eRDMA?
可以通过弹性RDMA网卡(ERI)实现。它是可以绑定到ECS实例的虚拟网卡,但必须依附于弹性网卡,在弹性网卡的基础上开启RDMA的功能。
ERI复用了弹性网卡所属的网络(VPC),无需改变业务组网,可在原有的网络上使用RDMA功能,体验RDMA带来的超低延时。在基于第四代神龙架构的阿里云服务器上均可使用eRDMA。
eRDMA基于阿里云的VPC网络,因此不论是纯粹的CPU服务器还GPU服务器,均可以通过添加eRDMA设备激活eRDMA功能。现有业务可以平滑进行升级,完全继承阿里云的用户界面。
上图右侧展示了两种视角,下方为神龙底层视角,上方为用户侧视角。
在神龙底层的实现上,它由神龙CIPU模拟出VirtIO网卡设备和ERI设备,通过神龙的虚拟化层分配给弹性服务器。在用户视角有两个设备,分别为VirtIO和ERI,底层物理设备的访问对用户完全透明,用户仅需要安装阿里云提供的eRDMA驱动即可使用。

eRDMA在技术上具有哪些优势?
首先,在eRDMA的实现中,使用了自研的拥塞控制算法,能够容忍VPC网络中的传输质量变化,比如延时的抖动、丢包问题,在有损的网络环境中依然能够拥有良好的性能表现。
另外,相比IB以及RoCE网络,其基础设施无需重新部署,也不需要进行特有的网络交换机配置。它依托于阿里云的VPC网络,可以在全地域任意扩容部署,用户可以按需购买,弹性伸缩,确保资源高效利用。更重要的是,它继承了云服务器高可用性的特点,可以实现任意节点的故障迁移,保障业务快速恢复。
另外,结合阿里云控制台全面的性能监控工具,可以实现快速诊断网络异常,或根据性能监控的分析优化业务通讯模型,提升性能。
eRDMA全面兼容RDMA的生态以及Verbs接口,上图右侧展示了当前eRDMA能够支持的Verbs Opcode,覆盖了RDMA的主要操作代码。但同时,需要注意,eRDMA基于可靠连接服务(RC)实现的通信,同时支持TCP及CM两种建链方式,用户可以根据自己的应用进行选择。

阿里云推出了第一款支持eRDMA的GPU实例ebmgn7ex,它是ebmgn7e的升级版,搭配了8张NVIDIA Ampere架构的GPU,GPU间通过NVLink互联。整机内嵌两张eRDMA网卡,分别挂载在两个CPU Socket上,实现均衡的节点间数据通道。每4张GPU卡共用一个eRDMA设备,共用最大100G的eRDMA网络带宽。
与现有的弹性计算实例不同,ebmgn7ex使用的eRDMA、EBS存储以及VPC网络均为共享带宽模式。在没有存储及VPC网络流量的情况下,eRDMA可以使用最大200G带宽;存储或VPC网络存在流量时,会按照权重在不同的数据流量间进行带宽分配。但神龙CIPU在底层可以保证存储的性能,可以使得带宽的利用更高效,充分释放神龙CIPU的效能。

主流的AI框架底层通过多种不同的通讯后端进行多机或多卡通信等,几大集合通讯库比如OpenMPI、Gloo、NCCL对各种集合通信的模式和算法都有各自的实现。
NVIDIA 针对DPU实现了一套开源通讯库,可以通过PCIe和NVLink等通道,实现高速的机器间或GPU卡间的互联。借助软硬件协同,在性能优化上有得天独厚的优势,也是主流AI框架的推荐通讯后端。eRDMA对NCCL提供了很好的支持,可以做到无修改使用开源的NCCL通讯库,可以使能底层的eRDMA设备。相比较传统的TCP通信有更低的延时实现更高的吞吐能力,但可以做到与RDMA通信链路相当的性能。
另外,相比较RDMA,它更适合在云上大规模部署,为用户提供超高性价比、普惠的大带宽通信链路解决方案。

ebmgn7ex相比于ebmgn7e,采用同样的CPU和GPU配置,但底层采用了第四代神龙CIPU,将整机的网络带宽从65G提升至200G,提升幅度接近200%。同时,通过eRDMA技术使得通信延迟相比于VPC网络降低了80%。
我们选择了几个典型的多机训练应用场景对两者进行了对比测试。ebmgn7ex整体性能提升大约30%,尤其在对时延以及带宽强依赖的场景中,比如vgg16、语音变换以及mae等,性能提升超过40%。
与此同时,在用户成本接近的基础上,ebmgn7ex显然展示出了更好的性价比。初步估计,根据用户的业务场景,可实现20%-30%的成本优化。

阿里云在2022年发布了CIPU云处理单元。如今,在阿里云上,云服务已经远远不是将一台服务器通过虚拟化分割资源后提供给用户,而通过CIPU智能调度和管理能力,将CIPU、GPU存储网络等分拆为不同的资源池,根据用户的需求灵活地提供相应的服务。
由于存储网络和计算资源相互独立,在使用计算服务时,几类资源都可以根据用户的需求进行动态调整。比如CPU的核数、挂载ESSD数据盘的容量、网络带宽等,都可以根据业务对性能的需求而变化,相对于自建IDC提供了极大的弹性。
基于CIPU,我们做了两件事:
第一,将软件硬件化。将原来的虚拟化软件、网络传输、可信计算等功能通过CIPU的硬件加速来实现,将云软件功能从服务器的CPU内存里解放出来,让计算资源池独立地提供服务。通过软件硬件化也提高了虚拟化和网络传输等功能的性能。

第二,硬件软件化。通过软件定义硬件的方式,在CPU上提供了原本由硬件才能提供的RDMA功能。
当前,支持RDMA功能的主要解决方案有三种,分别为IB、RoCE以及iWARP。CIPU即通过软件定义网络的方式,基于iWARP协议提供RDMA功能。
市面上采用iWARP协议的方案并不多,原因在于iWARP协议基于TCP传输,相较于RoCE和IB,需要大量内存访问,在大型网络中会影响服务器的CPU性能。并且由于采用了通用的TCP/IP网络设施,无法实现对RDMA传输的监控,在控制拥塞等方面也存在问题。
然而,阿里云采用了CIPU,通过软件定义的方式,实现了对网络数据的拥塞控制和流量管理。同时,CIPU将原来网络和虚拟化层上的内存和计算工作offload到CIPU的处理器上,不会影响计算节点的性能。
 ·
·
通过以上方式,CIPU规避了iWARP的缺点,以TCP/IP overlay的方式组网。原先阿里云以RoCE协议提供的计算产品,首先需要一套overlay网络来做VPC网络,另外需要再组一套RoCE来进行RDMA的数据传输。eRDMA相较于原来的方案,将RDMA合并至VPC网络里,整个拓扑变得非常简单便捷。
阿里云的网络存储计算资源都连接在VPC网络里,通过CIPU,可以让AZ内所有资源都通过RDMA来进行数据的传输。传统的RoCE、IB网络需要独立新建专门的机房,机房建好后网络拓扑难以改变。而eRDMA实例无需新建机房,因此在机房成本方面相较于RoCE网络的方式有很大降低,极具性价比。
另外,CIPU软件定义硬件可以实现弹性网络,因此eRDMA的计算集群无需额外的网络配置即可在overlay类上链接AZ里所有资源。只要是部署于单一AZ的资源,都可以被拉起提供给同一个计算资源集群使用,弹性能力大幅增强。同时,eRDMA基于通用计算网络,兼容性非常好,可以兼容几乎所有API。

正由于eRDMA能够让AZ里几乎任意规模的计算资源汇合成为独立的计算集群,因此它非常适合于搭建AI训练集群。基于eRDMA协议,该实例采用了ICL处理器,每一台机器可以通过eRDMA的200G网络进行互联,在可用区内申请的所有此类实例,互相之间都可以实现RDMA传输。

需要特别说明,云上提供资源时一般通过虚拟化层,算力在虚拟化层会有一定的损耗,而阿里云采用CIPU提供的裸金属实例则有所不同。实例前面的ebm三个字母代表了这一台裸金属实例整机的物理资源均通过CIPU直接透传给用户,中间没有虚拟化层的损耗,在CIPU的云管理加持下,用户可以获得一台完整的物理机能力。
该实例的价格相比于此前64G网络带宽的裸金属实例ebmgn7e反而有所降低,这正是CIPU对网络的兼容性带来的高性价比红利。同时,并非只有训练集群业务才能选择该实例,一些通用的单机训练以及推理业务也可以选择。比如当前非常火的ChatGPT,ChatGPT模型在推理时需要500G以上的显存,因此该实例也是大模型推理的最优选择。
当前在云上可以通过邀测链接申请使用eRDMA实例。申请实例时的步骤选项也于此前有所不同。
第一,在操作系统选择时新增了自动安装eRDMA驱动选项,建议勾选,勾选后在实例内可以自动安装eRDMA的网络驱动;
第二,在网络配置方面,ebmgn7ex需要选择两个固定的弹性网卡,该两个弹性网卡不可释放,每个网卡可以提供100G的网络带宽,在勾选上右侧的eRDMA后,即可支持RDMA传输。若在使用或测试中某些应用出现异常,也可以将勾选取消,此时实例的网络带宽仍然不变,但是仅支持VPC网络连接实例。

阿里云将会逐步推出更多产品来支持eRDMA。ebmgn7ex实例也会在阿里云上形成完整的生态,通过基于eRDMA互联,用户在集群中可以接入ECS通用计算实例,可以接入支持eRDMA的CPFS分布式存储来获得更低延时。并且由于裸金属与CPFS实现了RDMA传输,因此借助GPU Direct Storage功能,可以在快速获取训练数据时节省更多NC的资源。
同时,公共云上原有的安全功能以及阿里云在人工智能方面提供的各类PaaS服务,比如ACK容器服务、serverless计算服务、PAI平台的所有功能也都可以运行在基于eRDMA的实例上。

使用阿里云支持eRDMA的实例用户,可以获得极高的计算集群弹性能力,以分钟级的极快速度在云上搭建RDMA训练集群,并可根据需求进行弹性扩容,将极大节省训练业务的时间。
eRDMA具有非常高的带宽,所有支持eRDMA的实例可以以数百G的带宽进行RDMA的低延时通信,并且不会增加成本,节省了搭建机房的费用。更重要的是,公共云的生态可以提供非常优质的计算服务,比如基于业务实现弹性伸缩、OSS、CPFS等各类存储。
eRDMA还提供方便的管理能力,以及公共云基于神龙架构提供的针对计算、存储、网络的稳定性保障,极高的稳定性也节省了运维和维护成本。
在阿里云,the more you buy,the more you save。

点击链接进入阿里云开发者社区直播间 / 扫描上方海报中的二维码进入NVIDIA GTC官网,均可观看完整视频。