
1.结合对性能度量部分的阅读,简述错误率、精度、查准率与查全率的含义。
答:
错误率(Error Rate):是分类错误的样本数占样本总数的比例。

精度(Accuracy):是分类正确的样本数占样本总数的比例。

对于二分类问题,可将样例根据其真实类别与学习器预测类别的组合划分为真正例(true positive)、假正例(false positive)、真反例(true negative)、假反例(false negative)四种情形,令TP、FP、TN、FN分别表示其对应的样例数,则显然有TP+FP+TN+FN=样例总数。分类结果的“混淆矩阵”(confusion matrix)如下所示:

查准率(Precision),又叫准确率,缩写表示用P。查准率是针对我们预测结果而言的,它表示的是预测为正的样例中有多少是真正的正样例。

查全率(Recall),又叫召回率,缩写表示用R。查全率是针对我们原来的样本而言的,它表示的是样本中的正例有多少被预测正确。

(注:以上公式均截图自《机器学习》周志华)
2. 数据集包含1000个样本,其中500个正例、500个反例,将其划分为包含70%样本的训练集和30%样本的测试集用于留出法评估,试估算共有多少种划分方式?
答:
留出法将数据集划分为两个互斥的集合,为了保持数据的一致性,应该保证两个集合中的类别比例相同。故可以用分层采样的方法。
所以训练集包含350个正例与350个反例,测试集包含150个正例与150个反例。
方式总数: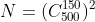
3.已知分类结果混淆矩阵如下,试计算错误率,精度,查准率,查全率,F1。
真实情况 |
预测结果 |
|
正例 |
反例 |
|
正例 |
100 |
300 |
反例 |
200 |
400 |
答:
错误率:E=FN+FPTP+FN+FP+TN=300+200100+300+400+200=0.5
精度:A=TP+TNTP+FN+FP+TN=100+400100+300+400+200=0.5
查准率:P=TPTP+FP=100100+200=0.333
查全率:R=TPTP+FN=100100+300=0.25
F1:A=2*TPTP+FN+FP+TN+TP-TN=2*1002*100+300+200=0.2857
4.如下所示10个测试样本,’Class’一栏表示每个测试样本的真正标签 (P表示正例;N表示反例),’Score’表示在某分类器中每个测试样本被预测为正样本的概率:
序号 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
Class |
P |
N |
N |
P |
P |
N |
N |
P |
P |
N |
Score |
0.93 |
0.85 |
0.80 |
0.7 |
0.55 |
0.50 |
0.40 |
0.3 |
0.2 |
0.1 |
画出ROC 曲线并计算AUC 的值。
答:
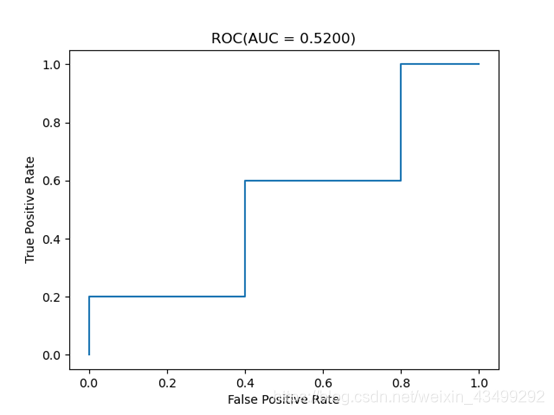
Auc = 0.52


