
链表实现链栈的原理
使用链表实现栈的链式存储数据结构,链表的实现和讲解请参考文章

和栈的顺序存储一样,链栈是特殊的链表,它限制只能在链表的一端进行插入删除操作,允许操作的一端称为栈顶,另一端称为栈底。那么选择链表的哪一端作为栈顶呢,通过下面的示意图进行分析
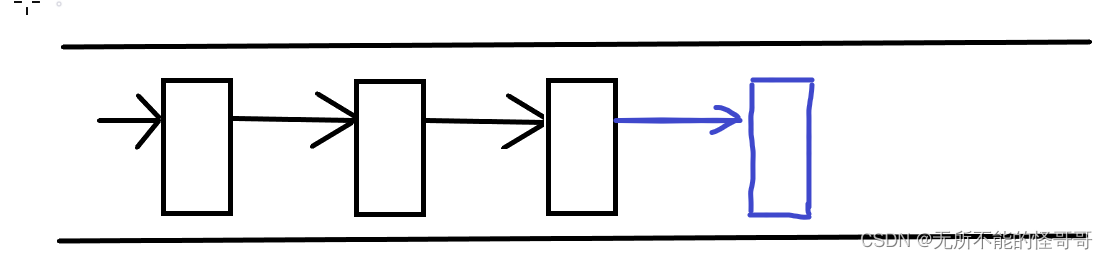
假如像顺序表实现顺序栈那样,用链表尾部作为栈顶的话,因为链表只有指向后继的指针(单向的),每次插入删除都需要对链表进行遍历,来求出尾部位置,若链表太长将耗费很多时间,时间复杂度为O(n)。加入使用链表头作为栈顶的话,每次直接在0号位置插入删除,时间复杂度为O(1),显然更加合理。
链栈的API
1. typedef void LinkStack; 2. 3. LinkStack* LinkStack_Create(); 4. 5. void LinkStack_Destroy(LinkStack* stack); 6. 7. void LinkStack_Clear(LinkStack* stack); 8. 9. int LinkStack_Push(LinkStack* stack, void* item); 10. 11. LinkStack* LinkStack_Pop(LinkStack* stack); 12. 13. LinkStack* LinkStack_Top(LinkStack* stack); 14. 15. int LinkStack_Size(LinkStack* stack);
链栈的API实现
链栈的结点结构体
1. typedef struct LinkStackNode 2. { 3. LinkedListNode node; 4. void* item; 5. }LinkStackNode;
可以把链栈的结点视为一个业务结点,每次插入链栈的操作都相当于把链栈结点插入到链表中,所以只需要将链栈的结点结构体第一个域包含为链表的结点元素即可,链栈的第二个数据域为指向要插入链栈的业务数据。通过向链表中插入链栈结点元素来实现往链栈中插入业务数据这个需求。
创建链栈
1. LinkStack* LinkStack_Create() 2. { 3. return LinkedList_Create(); 4. }
在链栈中插入一个元素
因为我们是先将业务数据放到链栈结点中,然后再把链栈结点插入到链表中,这样来实现把业务数据插入链栈。所以,我们需要手工分配内存malloc一个链栈结点,不然的话,假如使用局部变量这个结点在运行完入栈函数LinkStack_Push后,就被编译器释放掉了。但是要注意,malloc分配的内存要在适当的时机进行free。(我们在链表的实现一文中,测试案例中是主调函数分配内存,把元素插入到链表中,因为我们是在main函数中分配的内存,所以不用担心局部变量被释放的问题)
1. int LinkStack_Push(LinkStack* stack, void* item) 2. { 3. LinkStackNode* pTemp = NULL; 4. if ((stack == NULL) || (item == NULL)) 5. { 6. printf("err: (stack == NULL) || (item == NULL)\n"); 7. return - 3; 8. } 9. pTemp = (LinkStackNode*)malloc(sizeof(LinkStackNode)); 10. if (pTemp == NULL) 11. { 12. printf("(LinkStackNode*)malloc(sizeof(LinkStackNode)) err\n"); 13. return -1; 14. } 15. memset(pTemp, 0, sizeof(LinkStackNode)); 16. pTemp->item = item; 17. if (0 != LinkedList_Insert(stack, (LinkedListNode*)pTemp, 0)) 18. { 19. free(pTemp); 20. printf("LinkedList_Insert() err\n"); 21. return -2; 22. } 23. return 0; 24. }
弹出一个元素
弹出元素的时候,要返回业务数据,并释放链栈结点的内存。
1. LinkStack* LinkStack_Pop(LinkStack* stack) 2. { 3. LinkStackNode* pTemp = NULL; 4. LinkStack* item = NULL; 5. if (stack == NULL) 6. { 7. printf("err: stack == NULL\n"); 8. return NULL; 9. } 10. pTemp = (LinkStackNode*)LinearList_Delete(stack, 0); 11. if (pTemp == NULL) 12. { 13. printf("LinearList_Delete() err\n"); 14. return NULL; 15. } 16. item = pTemp->item; 17. free(pTemp); 18. return item; 19. }
返回栈顶元素
1. LinkStack* LinkStack_Top(LinkStack* stack) 2. { 3. LinkStackNode* pTemp = NULL; 4. if (stack == NULL) 5. { 6. printf("err: stack == NULL\n"); 7. return NULL; 8. } 9. pTemp = (LinkStackNode*)LinearList_Get(stack, 0); 10. return pTemp->item; 11. }
获取链栈元素个数
1. int LinkStack_Size(LinkStack* stack) 2. { 3. if (stack == NULL) 4. { 5. printf("err: stack == NULL\n"); 6. return -1; 7. } 8. return LinkedList_Length(stack); 9. }
清空链栈
在清空链栈的时候,要把所有malloc的内存释放掉。(为啥链表清空的时候没有释放内存呢,而只是把头结点指向NULL就可以?因为链表中插入的都是在主调函数main中分配好内存的变量,在main函数结束后,会被编译器释放,所以就不用我们释放了)
注意:主调函数分配内存,通过传参给被调函数,如果是主调函数中的局部变量(没有malloc),那就不需要手动释放内存;被调函数中malloc的内存,一定要手动free。
1. void LinkStack_Clear(LinkStack* stack) 2. { 3. if (stack == NULL) 4. { 5. printf("err: stack == NULL\n"); 6. return; 7. } 8. //因为栈中的元素都是malloc分配的,所以清空栈需要释放内存 9. while (LinkStack_Size(stack) > 0) 10. { 11. LinkStack_Pop(stack); 12. } 13. }
销毁链栈
1. void LinkStack_Destroy(LinkStack* stack) 2. { 3. if (stack == NULL) 4. { 5. printf("err: stack == NULL\n"); 6. return; 7. } 8. LinkStack_Clear(stack); 9. LinkedList_Destroy(stack); 10. }
代码资源已经上传



