
channel选择器副本机制
我们现在的需求就是实时的监听一个文件的变化,然后将变化的数据上传到HDFS,另外需要在本地文件系统保存副本,所以此次的sink去向有两个,一个是HDFS,另外一个就是本地文件系统。
其实我们可以用一个flume就可以实现将第一个flume的sink分别设置为两个去向,为什么下图要多用两个flume呢?是因为有时HDFSsink端写数据较慢,生产数据较快,那就有可能生产大于消费,刚开始还可以在channel进行缓存,如果channel也满了就会崩掉,多两个flume也是为了增加缓冲。
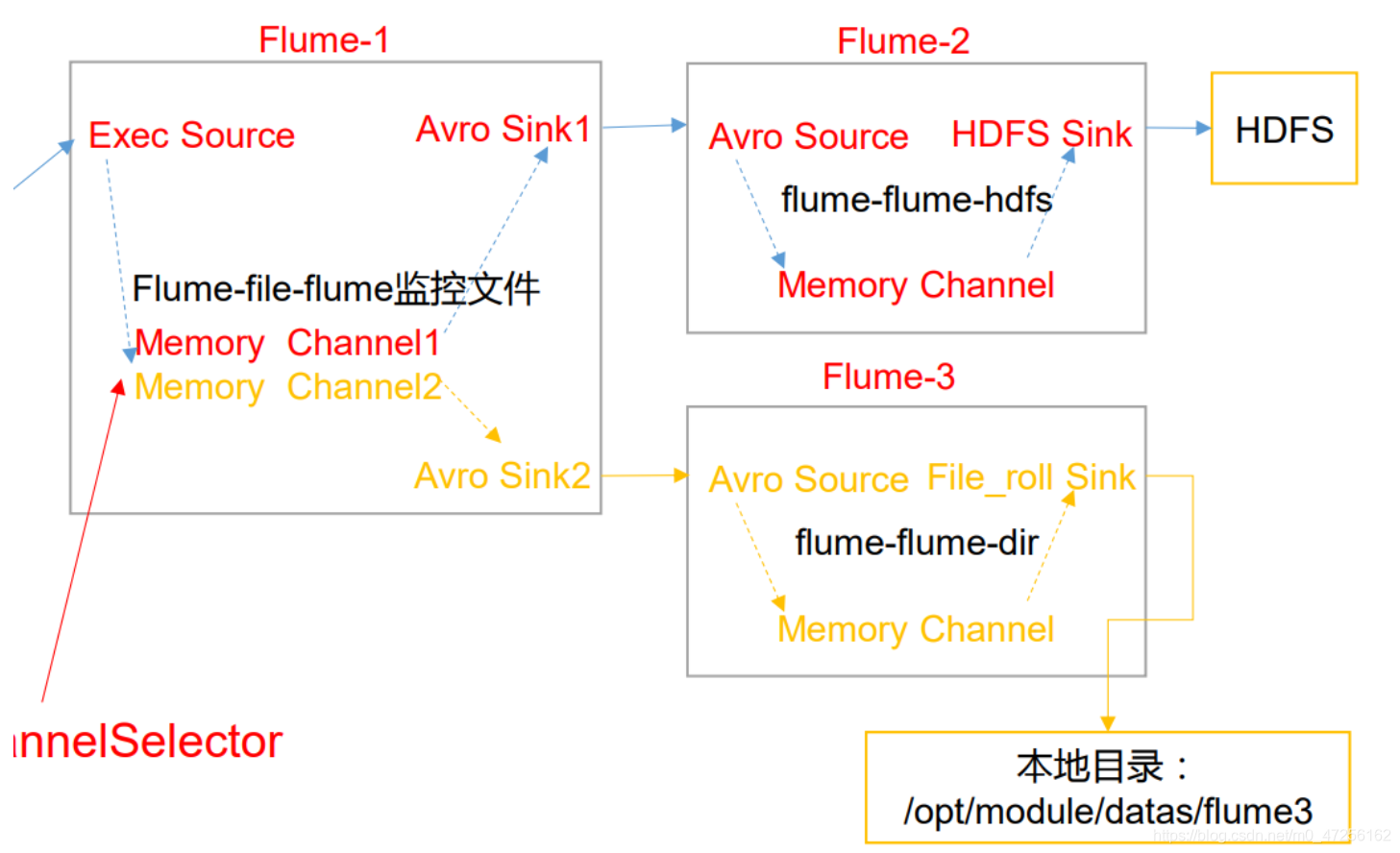
上图我们可以看到第一个flume从source监听数据,然后交给两个channel,这就需要两个channel收到的数据是一致的,所以channel选择器需要配置成副本,然后两个channel分别发往对应的sink,这里sink采用的是avro,它是用于两个flume之间联系的组件,如果两个flume需要联系,上一个flume的sink就要配置avro,下端的flume的source也要配置相应的avro。
avro的sink就是将数据发往指定IP的某个端口,avro的source就是从某个IP地址的指定端口进行获取数据。
Flume2配置的就是avrosource,然后sink端就是HDFS。
Flume3同样配置avro,但是sink端配置的是file_roll,用于传输到本地文件系统
Flume1
a1.sources = r1 a1.sinks = k1 k2 a1.channels = c1 c2 a1.sources.r1.selector.type=replicating a1.sources.r1.type = taildir a1.sources.r1.channels = c1 a1.sources.r1.positionFile = /opt/module/flume/position/position.json a1.sources.r1.filegroups = f1 a1.sources.r1.filegroups.f1 = /home/hadoop/data3/data a1.sinks.k1.type = avro a1.sinks.k1.hostname=hadoop102 a1.sinks.k1.port=4141 a1.sinks.k2.type = avro a1.sinks.k2.hostname=hadoop102 a1.sinks.k2.port=4142 a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.channels.c2.type = memory a1.channels.c2.capacity = 1000 a1.channels.c2.transactionCapacity = 100 a1.sources.r1.channels = c1 c2 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c2
Flume2
a2.sources = r1 a2.sinks = k1 a2.channels = c1 a2.sources.r1.type = avro a2.sources.r1.bind=hadoop102 a2.sources.r1.port=4141 a2.sinks.k1.type = hdfs # 配置hdfs存储的路径,这里我设置的是动态路径,按照时间命名的文件夹 a2.sinks.k1.hdfs.path=hdfs://hadoop102:9000/flume/%Y%m%d/%H # 给存储到HDFS的文件加个前缀标明该数据为日志信息 a2.sinks.k1.hdfs.filePrefix=logs- # 是否按照时间进行滚动文件夹,对应上面配置的动态文件夹 a2.sinks.k1.hdfs.round=true a2.sinks.k1.hdfs.roundValue=1 # 设置时间量级为秒、分钟还是小时 a2.sinks.k1.hdfs.roundUnit=hour # 是否使用本地时间戳,我测试了一下,如果这里设置成false,HDFS目录不会发生变化,可能是hdfs配置的动态时间路径就是按照时间戳配置的 a2.sinks.k1.hdfs.useLocalTimeStamp=true # 积攒多少个Event才会flush到HDFS a2.sinks.k1.hdfs.batchSize=1000 # 文件类型 a2.sinks.k1.hdfs.fileType=DataStream # 多久会生成一个新的文件,如果监听的文件没有变化,尽管到了时间也不会产生新文件,产生新文件需要事件去触发 a2.sinks.k1.hdfs.rollInterval=30 # 每个文件大小达到多少会进行滚动 a2.sinks.k1.hdfs.rollSize=134217700 # 设置文件的滚动与事件无关 a2.sinks.k1.hdfs.rollCount=0 a2.channels.c1.type = memory a2.channels.c1.capacity = 1000 a2.channels.c1.transactionCapacity = 100 a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1
Flume3
a3.sources = r1 a3.sinks = k1 a3.channels = c1 a3.sources.r1.type = avro a3.sources.r1.bind=hadoop102 a3.sources.r1.port=4142 a3.sinks.k1.type = file_roll a3.sinks.k1.sink.directory = /home/hadoop/data4/flume a3.channels.c1.type = memory a3.channels.c1.capacity = 1000 a3.channels.c1.transactionCapacity = 100 a3.sources.r1.channels = c1 a3.sinks.k1.channel = c1
这样当我们向data文件中追加数据,整个flume流程就将我们追加的数据以副本机制分别传输到HDFS和本地文件系统。
