
实时监听文件到HDFS系统
之前测试了监听一个文件的新内容,然后打印到了控制台,现在我们需要将监控到的内容放到HDFS中进行存储,其实和控制台一样,只不过是将sink源改到HDFS,修改一下相关的配置。
a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = exec a1.sources.r1.command=tail -F /home/hadoop/data/file # 指定用什么去解析上面的命令 a1.sources.r1.shell=/bin/bash -c a1.sinks.k1.type = hdfs # 配置hdfs存储的路径,这里我设置的是动态路径,按照时间命名的文件夹 a1.sinks.k1.hdfs.path=hdfs://hadoop102:9000/flume/%Y%m%d/%H # 给存储到HDFS的文件加个前缀标明该数据为日志信息 a1.sinks.k1.hdfs.filePrefix=logs- # 是否按照时间进行滚动文件夹,对应上面配置的动态文件夹 a1.sinks.k1.hdfs.round=true a1.sinks.k1.hdfs.roundValue=1 # 设置时间量级为秒、分钟还是小时 a1.sinks.k1.hdfs.roundUnit=hour # 是否使用本地时间戳,我测试了一下,如果这里设置成false,HDFS目录不会发生变化,可能是hdfs配置的动态时间路径就是按照时间戳配置的 a1.sinks.k1.hdfs.useLocalTimeStamp=true # 积攒多少个Event才会flush到HDFS a1.sinks.k1.hdfs.batchSize=1000 # 文件类型 a1.sinks.k1.hdfs.fileType=DataStream # 多久会生成一个新的文件,如果监听的文件没有变化,尽管到了时间也不会产生新文件,产生新文件需要事件去触发 a1.sinks.k1.hdfs.rollInterval=30 # 每个文件大小达到多少会进行滚动 a1.sinks.k1.hdfs.rollSize=134217700 # 设置文件的滚动与事件无关 a1.sinks.k1.hdfs.rollCount=0 a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
HDFS的目录我们不需要提前建立,flume会自动为我们创建指定目录
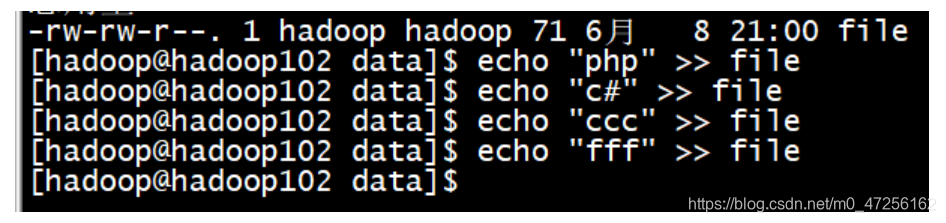
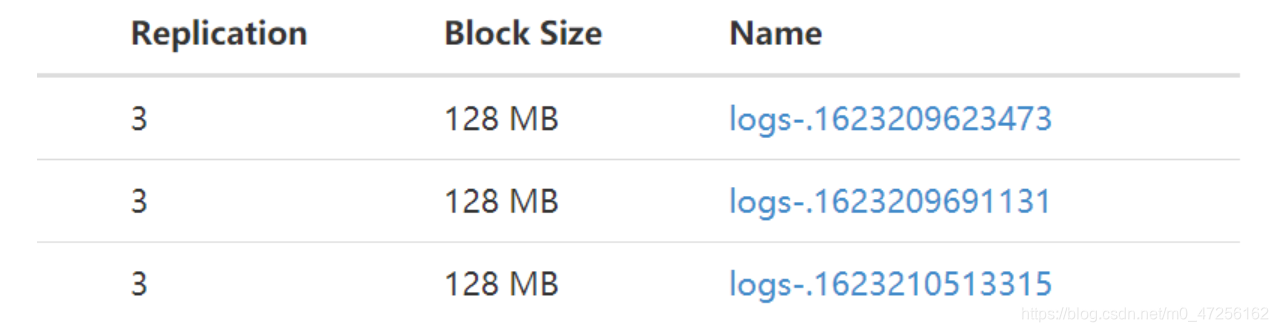
我们可以看到文件的命名就是以我们设置的logs-作为前缀,后面拼接的是时间戳。
