一、新闻聚类分群
1、✌ 导入相关库
from sklearn.feature_extraction.text import CountVectorizer from sklearn.cluster import KMeans from sklearn.cluster import DBSCAN from sklearn.metrics.pairwise import cosine_similarity import numpy as np import pandas as pd import jieba
sklearn.feature_extraction.text import CountVectorizer:文本向量化
from sklearn.cluster import KMeans:KMeans模型
from sklearn.cluster import DBSCAN:DBSCAN模型
from sklearn.metrics.pairwise import cosine_similarity:余弦相似度
2、✌ 读取数据
data=pd.read_excel('news.xls') data.head()

3、✌ 中文分词
words=[] for i,row in data.iterrows(): word=jieba.cut(row['标题']) result=' '.join(word) words.append(result) words

将数据中的标题栏利用jieba库进行分词,为后面搭建词频矩阵使用
4、✌ 文本向量化:建立词频矩阵
from sklearn.feature_extraction.text import CountVectorizer vect=CountVectorizer() x=vect.fit_transform(words) x=x.toarray() x

Python在处理数据需要数值型数据,需要将上文的文本数据转化为词频矩阵,可以利用CountVectorizer函数
他的原理是将words中的每个词去重以及出去无意义的词,进行编号,然后对应每个原文本计数该次出现的次数
5、✌ 构造特征矩阵
words_name=vect.get_feature_names() df=pd.DataFrame(x,columns=words_name) df
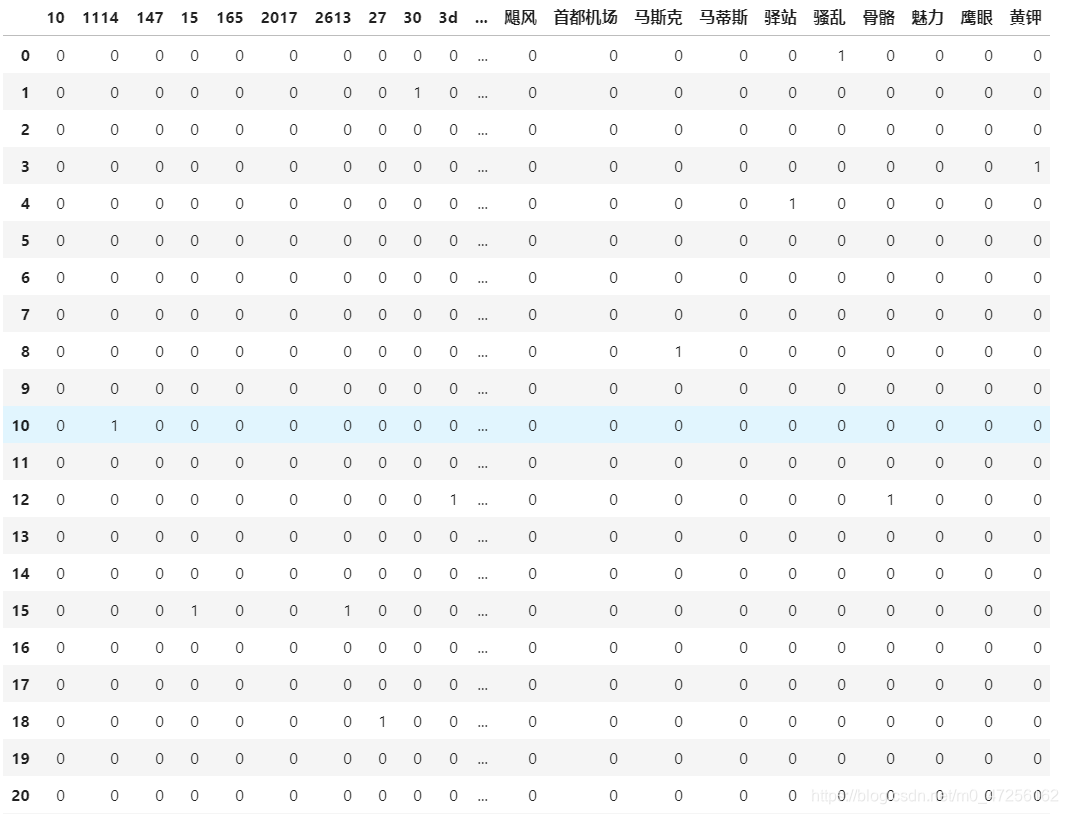
词频矩阵处理好,需要构造特征向量为下面模型使用
6、✌ 模型搭建
(1)、✌ 通过KMeans算法进行聚类分群
from sklearn.cluster import KMeans kms=KMeans(n_clusters=10,random_state=0) label_kms=kms.fit_predict(df) label_kms import numpy as np words_array=np.array(words) words_array[label_kms==2]

(2)、✌ 通过DBSCAN算法进行聚类分群
from sklearn.cluster import DBSCAN dbs=DBSCAN(eps=1,min_samples=3) label_dbs=dbs.fit_predict(df) label_dbs

这里我们发现分类出的标签有问题,全部都是-1,说明,全部都是离散点,因为词频处理后,特征过多,导致样本点之间距离较远,从而产生离群点,因此对于新闻文本而言,KMeans算法的聚类效果很好,而DBSCAN的效果较差
这也说明了对于特征较多的数据,KMeans算法的聚类效果要好于DBSCAN算法的聚类效果。
7、✌ 利用余弦相似度进行模型优化
from sklearn.metrics.pairwise import cosine_similarity df_cs=cosine_similarity(df) kms_cs=KMeans(n_clusters=10,random_state=0) label_kms_cs=kms_cs.fit_predict(df_cs) label_kms_cs

余弦相似性通过测量两个向量的夹角的余弦值来度量它们之间的相似性。0度角的余弦值是1,而其他任何角度的余弦值都不大于1;并且其最小值是-1。从而两个向量之间的角度的余弦值确定两个向量是否大致指向相同的方向。两个向量有相同的指向时,余弦相似度的值为1;两个向量夹角为90°时,余弦相似度的值为0;两个向量指向完全相反的方向时,余弦相似度的值为-1。这结果是与向量的长度无关的,仅仅与向量的指向方向相关。余弦相似度通常用于正空间,因此给出的值为-1到1之间。
当文本出现重复值时,可以将原词频矩阵的数据进行余弦相似度处理,处理后的特征矩阵再带入模型。