

大纲复习
服务治理:
nacos 注册中心(nacos 同时解决配置)=Eureka+配置
为什么要用注册中心
一旦服务提供者地址变化,就需要手工修改代码
一旦是多个服务提供者,无法实现负载均衡功能
一旦服务变得越来越多,人工维护调用关系困难
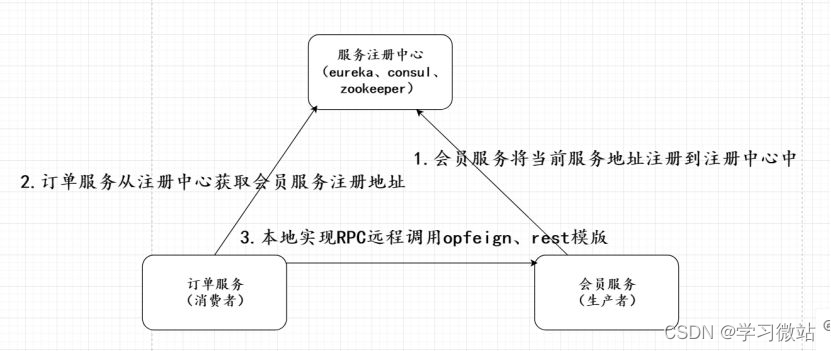
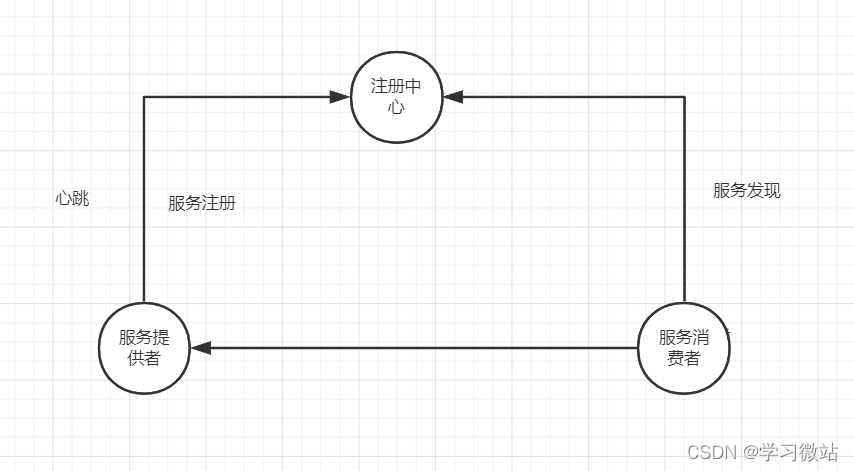
服务治理就是 服务注册 和 服务发现
服务注册中心nacos
原来的
现在

负载均衡:
springcloud 提供 ribbon
服务调用:
fegin---->容错机制 多个路径
容错组件:
Sentinel
阿里巴巴开源的一款
Sentinel +fegin
消息队列:
mq(RocketMQ Kafka、ActiveMQ、RabbitMQ)
数据库:
mysql, NoSQL如redis,ES
docker:
Docker 配置文件目录
深入研究: 高并发(访问量)、服务雪崩
一个完整的项目,微服务架构一般包括下面这些服务:
注册中心
(常用的框架 Nacos、Eureka)随着eureka的停止更新,如果同时实现注册中心和配置中心需要SpringCloud Eureka和SpringCloud Config两个组件;配置修改刷新时需要SpringCloud Bus消息总线发出消息通知(Kafka、RabbitMQ等)到各个服务完成配置动态更新,否者只有重启各个微服务实例,但是nacos可以同时实现注册和配置中心,以及配置的动态更新。
统一网关(常用的框架 Gateway、Zuul)
认证中心(常用技术实现方案 Jwt、OAuth)
分布式事务(常用的框架 Txlcn、Seata)
文件服务
业务服务
高并发:在微服务架构中,由于网络原因或者自身原因,服务并不能保证服务100%可用,如果单个服务出现问题,调用这个服务就会出现网络延迟,此时若有大量网络访问,会形成任务堆积,卡Duang,甚至导致服务挂掉
雪崩效应:由于服务服务两两依赖性,会对整个微服务系统造成灾难性的严重后果,这就是服务故障的“雪崩效应”
a挂了----》b请求a也跟着挂了----》c请求b也跟着挂了
原因 1 不合理容量设计 2 高并发响应变慢 3 资源耗尽
所以只有做好容错工作,不会影响其他服务正常运行
常见容错方案
隔离 超时 限流 熔断 降级
熔断
当下游服务因访问压力过大而响应变慢或失败,上游服务为了保护系统整体的可用性,可以暂时切断对下游服务地调用,这种牺牲局部,保护整体就就做熔断。----暂时切断–正常再恢复
熔断关闭状态
a->>b正常访问
熔断开启状态
a—>非正常访问,直接执行本地的fallback方法
半熔断状态
过一下子去试一下可以访问了嘛,行就关闭熔断,不行接着熔断。每隔一段时间去试试。
降级 fegin 备用方法 ----》系统繁忙,请稍后再试
容错组件:Sentinel 阿里巴巴开源的一款
Sentinel +fegin
Sentinel体现:流量控制、熔断降级
Sentinel与Hystrix区别:效果目的一样,Hystrix采用线程池隔离
其它:OpenSergo(专注微服务治理)+Sentinel
Sentinel还提供系统负载报错。在集群环境下,会把本应该这个机器流量转发到其他机器上(叫兄弟来帮忙),如果其他机器也在边缘了,这时Sentinel提供对应保护机制,让系统的入口流量和系统负载达到一个平衡,保证系统最大能力处理最多请求
sentinel localhost:阈值类型:QPS 线程数
单机阈值:30。。。
流控效果:快速失败 Warm Up 排队等待
Apache Jmeter测压工具


