
2-网站日志分析案例-日志采集:Flume-Kafka-Flume-HDFS
hadoop2.7.3+ kafka_2.11-2.1.0
环境安装
虚拟机安装
安装hadoop
参考:https://blog.csdn.net/m0_38139250/article/details/121155903
安装zookeeper
参考:https://blog.csdn.net/m0_38139250/article/details/121284886
安装过程
1.下载:
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.5.7/apache-zookeeper-3.5.7-bin.tar.gz
2.解压
tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt/apps
3.创建软连接
ln -s apache-zookeeper-3.5.7-bin zookeeper
4.修改文件夹权限
chown -R root:root /opt/apps/apache-zookeeper-3.5.7-bin chmod -R 700 /opt/apps/apache-zookeeper-3.5.7-bin
5.配置环境变量
vi /etc/profile #添加zookeeper环境变量 export ZOOKEEPER_HOME=/opt/apps/zookeeper export PATH=$ZOOKEEPER_HOME/bin:$ZOOKEEPER_HOME/sbin:$PATH # 生效配置文件 source /etc/profile
6.创建zk的data0目录,并修改zk的zoo.cfg配置文件
cd /opt/apps/zookeeper/ mkdir data touch data/myid echo 1 > data/myid cd conf/ cp zoo_sample.cfg zoo.cfg vi zoo.cfg # 修改配置文件如下: # dataDir=/tmp/zookeeper 注释掉这句默认配置,然后添加下面的配置 dataDir=/home/hadoop/opt/app/zookeeper/data
基本命令
7.启动命令:
zkServer.sh start /opt/apps/zookeeper/conf/zoo.cfg #启动zk启动状态 zkServer.sh status /opt/apps/zookeeper/conf/zoo.cfg #查看zk启动状态 zkCli.sh -server localhost:2181 # 通过客户端访问zkServer
安装flume
参考:https://blog.csdn.net/m0_38139250/article/details/121392150
安装过程
1.下载flume
wget http://archive.apache.org/dist/flume/1.7.0/apache-flume-1.7.0-bin.tar.gz
2.解压
tar -zxf apache-flume-1.7.0-bin.tar.gz -C /opt/apps
3.添加配置文件
cd /opt/apps/apache-flume-1.7.0-bin/conf vi netcat2logger.conf
内容如下
# example.conf: A single-node Flume configuration # Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 6666 # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
上面的配置文件定义了一个agent的name为a1,a1的source监听6666端口,并且读取6666端口传过来的数据, a1的channel 采用内存作为缓存,a1的sink 类型为logs,具体含义可以参考官网,或是留言。
基本命令
在flume的安装目录下执行如下命令,即可使用flume采集数据:
$ bin/flume-ng agent -n a1 -c conf -f conf/netcat2logger.conf -Dflume.root.logger=INFO,console
flume-ng agent :表示flume的启动一个agent,ng是表示这是new的版本命令
-n a1:-n 表示name ,a1表示agent的名字为a1 对应配置文件中的a1
-c conf :表示flume的配置文件目录所在位置
-f conf/netcat2logger.conf: 表示自定义的数据采集配置文件位置。
-Dflume.root.logger=INFO,console:表示我们制定flume的日志格式,并且输出到控制台。
我们再开启一个新的终端,通过telnet 或 nc命令发送socket数据。
telnet 127.0.0.1 6666 或 nc 127.0.0.1 6666
,然后输入hello world,会看到反馈的信息ok。
安装kafka
安装过程
1.下载kafka安装包
wget https://archive.apache.org/dist/kafka/2.0.0/kafka_2.11-2.0.0.tgz
2.解压kafka
tar -zxvf kafka_2.11-2.0.0.tgz mv kafka_2.11-2.0.0 /opt/apps cd /opt/apps
3.配置软连接
cd /opt/apps ln -s kafka_2.11-2.0.0 kafka
4.配置环境变量
vi /etc/profile #添加zookeeper环境变量 export KAFKA_HOME=/opt/apps/kafka export PATH=$PATH:$KAFKA_HOME/bin # 生效配置文件 source /etc/profile
5.修改配置文件
cd kafka/config vi server.properties
修改内容如下:
# borker的编号,如果集群中有多个,则每个borker需设置不同的编号 broker.id=0 #broker对外提供服务入口的端口(默认9092) listeners=PLAINTEXT://localhost:9092 #存放消息日志文件地址 log.dirs=/opt/apps/kafka/kafkaData/kafka-logs # kafka所需zookeeper集群地址 zookeeper.connect=localhost:2181 # 添加 delete.topic.enable=true
常用命令
6.在kafka安装目录下执行启动命令
6.1启动关闭
# 启动kafka bin/kafka-server-start.sh config/server.properties # 后台启动 JMX_PORT=9991 kafka-server-start.sh -daemon /opt/apps/kafka/config/server.properties # 关闭kafka kafka-server-stop.sh
6.2topic相关
# 查看Kafka Topic列表 bin/kafka-topics.sh --zookeeper localhost:2181 --list # 创建Kafka Topic列表 bin/kafka-topics.sh --zookeeper localhost:2181 --create --replication-factor 1 --partitions 1 --topic test # 描述topic bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test # 查看Kafka Topic列表 bin/kafka-topics.sh --zookeeper localhost:2181 --list # 增加分区数 bin/kafka-topics.sh --zookeeper localhost:2181 --alter --topic test --partitions 5 # 删除Kafka Topic bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic test # 查看 topic 指定分区 offset 的最大值或最小值 time 为 -1 时表示最大值,为 -2 时表示最小值: bin/kafka-run-class.sh kafka.tools.GetOffsetShell --topic test --time -1 --broker-list 127.0.0.1:9092 --partitions 0
6.3生成消息
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test • 1
6.4消费消息
# 从头开始消费 bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning # 从尾部开始取数据,必需要指定分区 bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --offset latest --partition 0 # 指定分区 bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --offset latest --partition 0 # 取指定个数 bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --offset latest --partition 0 --max-messages 1
6.5 消费者 Group
#指定 Group bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test -group test_group --from-beginning # 消费者 Group 列表 bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list # 查看 Group 详情 bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group test_group --describe # 删除 Group 中 Topic bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group test_group --topic test --delete # 删除 Group bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group test_group --delete
6.6 平衡 leader
bin/kafka-preferred-replica-election.sh --bootstrap-server localhost:9092
6.7自带压测工具
bin/kafka-producer-perf-test.sh --topic test --num-records 100 --record-size 1 --throughput 100 --produce
案例过程
总体架构、
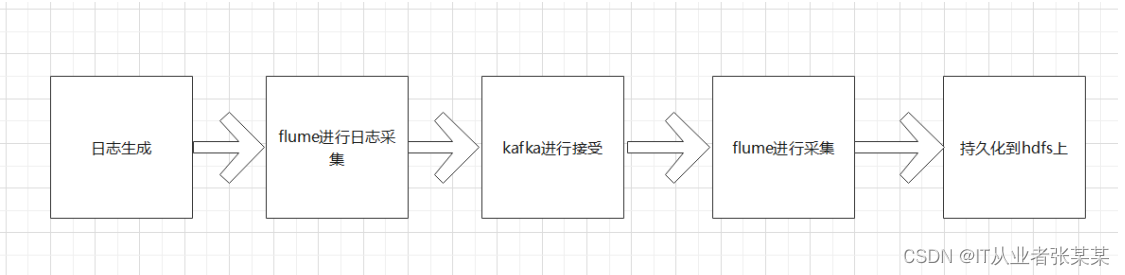
flume配置
把日志放在指定位置
在/tmp/logs下生成文件
/tmp/logs/app-2022-01-02.log
追加数据到该文件中:
for ((i=0; i<=1000; i++)) do echo "toms" >> /tmp/logs/app-2022-01-02.log sleep 2 done
第1个flume-把数据从linux采集到kafka中
文件名 file-flume-kafka.conf
cd /opt/apps/apache-flume-1.7.0-bin/conf vi file-flume-kafka.conf
编辑内容如下:
#describe component a1.sources=r1 a1.channels=c1 a1.sinks=k1 #config component source,we choose the taildir source,because it can breakpoint continuation a1.sources.r1.type = exec #监控文件夹下的test.log文件 a1.sources.r1.command = tail -F /tmp/logs/app-2022-01-02.log #component bind a1.sources.r1.channels = c1 #对于sink的配置描述 使用kafka做数据的消费 a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink a1.sinks.k1.topic = flume_kafka a1.sinks.k1.brokerList = localhost:9092 a1.sinks.k1.requiredAcks = 1 a1.sinks.k1.batchSize = 20 a1.sinks.k1.channel = c1 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100
启动:
bin/flume-ng agent --name a1 --conf-file conf/file-flume-kafka.conf • 1
kafka消费者观看数据
到kafka目录下
kafka-topics.sh --zookeeper localhost:2181 --list kafka-console-cosumer --bootstrap-server localhost:9092 --topic flume_kafka --from-beginning
第2个flume-把数据从kafka采集到hdfs中
采集event日志:文件名 kafka-flume-hdfs.conf
a1.sources=r1 a1.channels=c1 a1.sinks=k1 #config source a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource a1.sources.r1.batchSize = 5000 a1.sources.r1.batchDurationMillis = 2000 a1.sources.r1.kafka.bootstrap.servers =localhost:9092 a1.sources.r1.kafka.topics=flume_kafka #config channel a1.channels.c1.type = memory #config sink a1.sinks.k1.type = hdfs a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_event/%Y-%m-%d a1.sinks.k1.hdfs.filePrefix = logeventa1.sinks.k1.hdfs.rollInterval = 10 a1.sinks.k1.hdfs.rollSize = 134217728 a1.sinks.k1.hdfs.rollCount = 0 #bind component a1.sources.r1.channels = c1 a1.sinks.k1.channel= c1
启动命令
bin/flume-ng agent --name a1 --conf-file conf/kafka-flume-hdfs.conf

