AMASS: Archive of Motion Capture as Surface Shapes
马普所工作回顾

2005年,斯坦福大学的研究者们提出了SCAPE模型,2014年基于SCAPE模型马普所的研究者们提出了MoSh模型旨在更精细地利用光学动捕数据生成人体三维模型,2015年马普所的研究者们提出了新的SMPL人体三维模型,此后SMPL模型成为了更为主流的人体三维模型。2019年,为了整合现有光学动捕数据集光学标志点数量和位置不统一的情况,马普所提出了MoSh++方法,整合现有15个数据集,生成大规模人体动作捕捉数据集AMASS。
概要
由于现阶段庞大的深度学习网络需求大规模数据集,而基于光学标志点的数据规模往往较小,所以本文使用MoSh++方法,将15个有光学标记的人体动作捕捉(Mocap)数据集生成统一的SMPL模型,生成的数据集比以前的人体动作捕捉数据集要丰富得多,拥有超过 40 小时的运动数据,超过 11000 个动作,可在 https://amass.is.tue.mpg.de/ 上下载了解。
本文主要解决了两个任务:
- 开发了一种可以从普通运动捕捉标记数据集中准确恢复出人体运动的形态的方法MoSh++。
- 创建目前最大的公开人体动作捕捉数据集。

人体模型回顾
SCAPE:人体模型
SMPL:人体模型
SMPL-H:人体模型+手部模型
SMPL-X:人体模型+手部模型+人脸模型
STAR:SMPL的改进版
SCAPE:基于三角面片deformable的人体模型。
SMPL:基于点云deformable的人体模型。
人体模型主要思想是将pose, shape解耦,用参数化的方式描述人体表面的信息。SMPL将人体模型转化为pose, shape等参数的矩阵线性运算。在动态人体建模上,SMPL也扩展了DMPL,增加了速度、加速度、角速度等参数。

MoSh
由于传统的方法,使用外标记进行动作捕捉,提取出运动的骨骼点,得到运动的骨架,然后再利用骨架生成对应的人体运动模型。但是这样的效果往往是很僵硬的,并且不自然的,原因是人身体上的非刚体运动并没有被骨架信息采集到,例如身体上的软组织运动导致的标记点偏移信息没有被采集到,所以想提出一种,从标记点信息出发直接生成人体三维运动模型的方法,不经过中间对骨骼点的换算过程。
首先建立我们设定的标记点位模型,然后根据实际点位与估计点位的差值,拟合出相应的超参数,根据对应的数据集,真实的数据和估计的数据的误差,使用非线性优化的方法,拟合出相应的对应模型的参数,得到相应的统一化模型。
MoSh++
在马普所的之前研究中,提出了一种可以从光学动捕设备Vicon得到数据,生成对应有着软组织运动的SCAPE模型。但随着时间的推移和发展,SMPL模型逐渐取代了SCAPE模型。并且MoSh++在MoSh的基础上增加了软组织的精确建模以及对手部姿势的精确识别。
通俗理解
MoSh++是从稀疏的光学动捕标记点数据入手,相当于基于SMPL模型对光学动捕标记点数据进行扩展,进而生成具有全身精细动捕数据信息的SMPL模型,生成的SMPL模型又可以随意选取点位得到新的数据集。
改进思路
- we replace BlendSCAPE by SMPL to democratize its use
- we capture hands and soft-tissue motions
- we fine-tune the weights of the objective function using cross-validation on a novel dataset, SSM
使用非线性优化方法,拟合出基于SMPL模型的统一数据(SMPL模型参数),相当于不同的数据集是在SMPL模型上任意取出对应的位置点而得到的,MoSh++就是上述过程的逆过程。同时采集了SSM数据集用以验证超参数。
相当于利用凸优化方法,在给定近似Tpose参数的情况下,拟合对应动作的参数差值,实现最小化,得到对应的超参数,从而得到相应的Mosh++模型,应用到更多数据集上,得到更为准确的拟合效果。(仅改变Template上面标志点的位置模型即可)
具体公式


齐次坐标变换
马氏距离(Mahalanobis Distance)
DoglegMethod
Gauss–Newton
PASS
MoSh++优点
文章直接使用动捕标记数据而不是骨骼点信息,更加准确地恢复身体的完整 3D 表面。这种方法不会失去一般性,因为它可以从 3D 身体模型中导出任何所需的骨架表示或生成任何所需的标记集。
此外,拥有身体模型可以在不同场景中对虚拟身体进行纹理化和渲染。这对许多任务都很有用,包括为计算机视觉任务生成合成训练。

SSM(Synchronized Scans and Markers)
同时为了更好地调整参数且评估方法,本文同时提出了SSM(Synchronized Scans and Markers)数据集,它是由传统基于标记的动捕结合4D扫描仪生成的数据集。SSM分为训练集和测试集,用训练集训练MoSh++的超参数,接着在测试集上评估MoSh++的性能。
AMASS(Archive of Mocap as Surface Shapes)
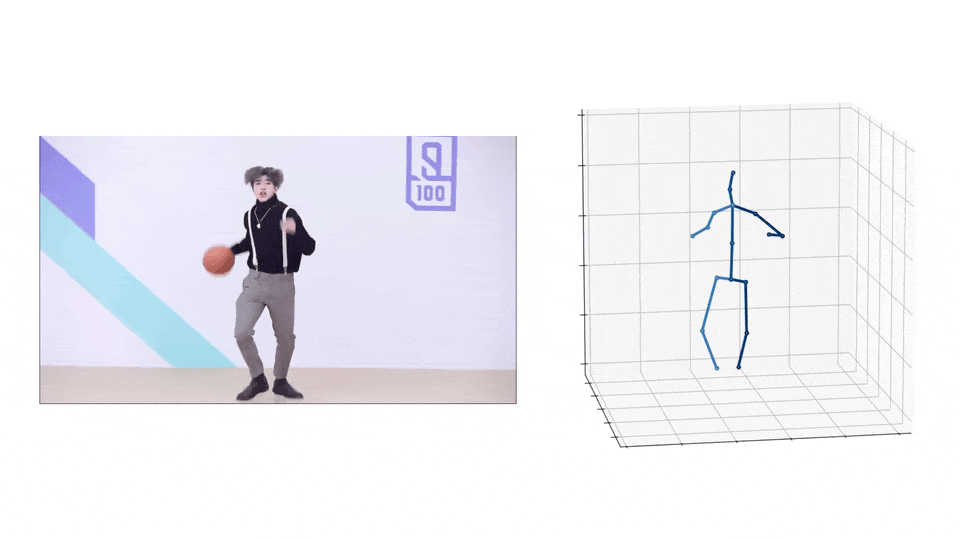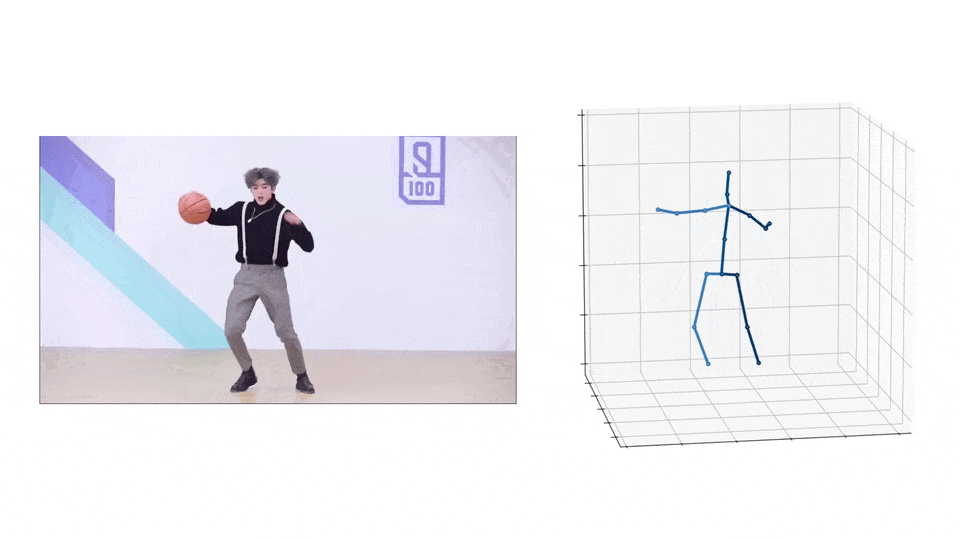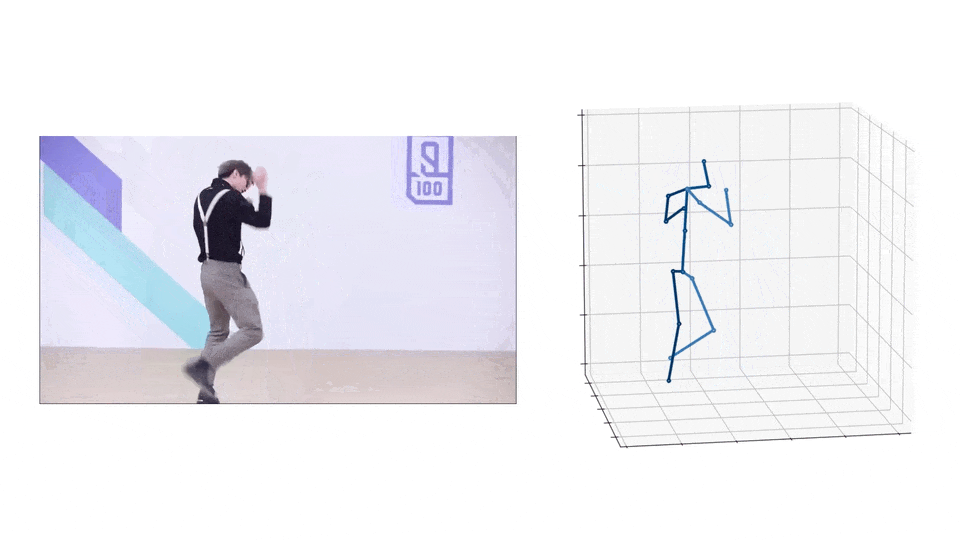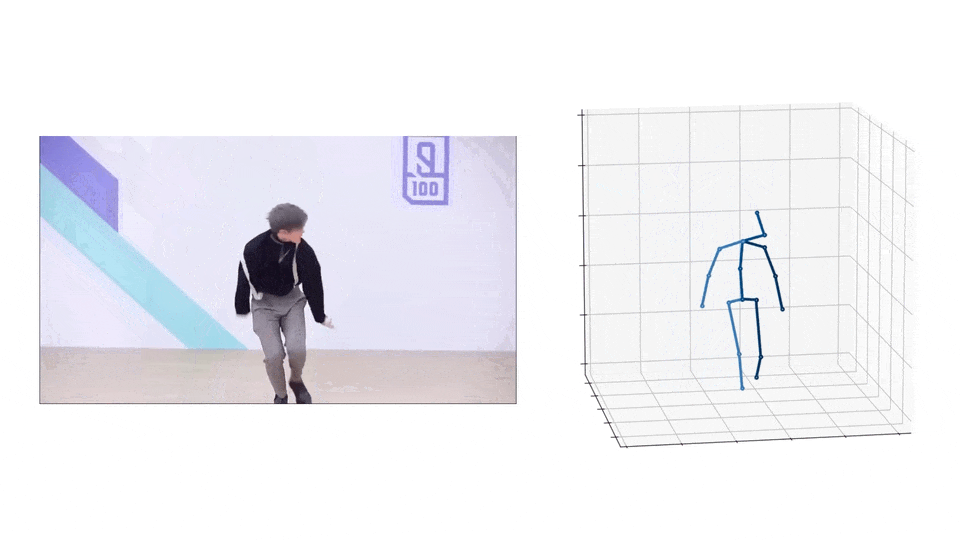
AMASS 有 40 小时的动作捕捉、344 个主题和 11265 个动作。构成AMASS数据集的原始数据集,有着37到91个分布不等的动捕标记。AMASS 中的每一帧都包括 SMPL 3D 形状参数(16 维)、DMPL 软组织系数(8 维)和完整的 SMPL 姿势参数(159 维),包括手部关节和身体全局平移。

MoSh++ 通过将 SMPL/DMPL 身体模型的表面拟合到观察到的动作捕捉标记(绿色)来捕捉身体形状、姿势和软组织动力学,同时还提供可用于标准动画程序的装配骨架(紫色)。传统的动作捕捉方法仅估计骨骼,将表面运动作为噪声过滤掉并丢失身体形状信息。