
- 目的
- 进一步掌握最优二叉树的含义。
- 掌握最优二叉树的结构特征,以及各种存储结构的特点及使用范围。
- 熟练掌握哈夫曼树的建立和哈夫曼编码方法。
- 掌握用指针类型描述、访问和处理运算
- 根据实际问题,结合课程中所学理论,设计适合的解决方案
- 对解决方案进行优化
- 要求
本课程是计算机科学技术中处于核心地位的一门专业基础课,它的主要研究内容是在程序开发中合理组织数据。通过对计算机数据机构的学习与研究,掌握设计的主要方法。为今后从事软件开发和软件理论研究打下良好的实验基础 。
在《数据结构》的课程实验过程中,要求学生做到:
- 预习实验指导书有关部分,认真做好实验内容的准备,就实验可能出现的情况提前作出思考和分析。
- 仔细观察上机操作调试时出现的各种现象,记录主要情况,作出必要说明和分析。
- 认真书写实验报告。实验报告包括实验目的和要求,实验情况及其分析。对所完成实验程序,写出程序设计说明,给出源程序框图和清单。
- 遵守机房纪律,服从辅导教师指挥,爱护实验设备。
- 实验课程不迟到。如有事不能出席,所缺实验一般不补。
实验的验收将分为两个部分。第一部分是上机操作,包括检查程序运行和即时提问。第二部分是提交书面的实验报告。此外,针对以前教学中出现的问题,实验将采用阶段检查方式,每个实验都将应当在规定的时间内完成并检查通过,过期视为未完成该实验,不计成绩。以避免期末集中检查方式产生的诸多不良问题,希望同学们抓紧时间,合理安排,认真完成。
- 内容
编写一个基于哈夫曼编码文件压缩/解压系统,一个完整的系统应具有以下基本功能:
- 初始化。给出需要压缩的文件sourcefile.txt, ,建立哈夫曼树,并将哈夫曼树或者字符的编码映射存到文件中,文件名自己定。
- 压缩编码。利用已建好的哈夫曼树,对文件sourcefile.txt的正文进行编码,然后将结果存入文件compressed。可以是01字符序列或者8个01为一个字节的二进制文件,见进阶功能(4)的说明。
- 解压缩。读入compressed文件,利用已建好的哈夫曼树(在内存中)或者读入第一步存储的哈夫曼树文件或者编码映射文件,将compressed解码问中的代码进行译码,结果存入文件uncompressed.txt中。
以下进阶功能(不一定全做):
- 将(2)压缩编码文件采用8个01为一个字节的二进制文件进行存储。
- 采用GUI界面
- 参考该文件后面的参考资料,对解码过程进行优化
- 步骤
- 定义结点结构,定义哈夫曼树结构;
- 初始化哈夫曼树,存储哈夫曼树信息;
- 定义求哈夫曼编码的函数;
- 定义译哈夫曼编码的函数;
- 写出主函数。
- 测试系统。
- 实现参考代码(仅供参考,里面有错误,自己修改)
typedef struct
{
char info; //关联字符信息
unsigned int weight; //每个节点的权值
unsigned int parent, lchild, rchild;
}HTNode,*HuffmanTree;
typedef char **HuffmanCode;
int n,*w;
char *info;
HuffmanTree HT; //存储哈弗曼树
HuffmanCode HC; //存储哈弗曼编码
void Select(HuffmanTree HT, int j,int &s1,int &s2)
{//选择双亲节点为0,并且最小的两个子叶节点
………..
}
void HuffmanCoding(HuffmanTree &HT, HuffmanCode &HC, int *w, int n,char *info) {
// 算法6.12
// w存放n个字符的权值(均>0),构造哈夫曼树HT,
// 并求出n个字符的哈夫曼编码HC
int i, j, m, s1, s2, start;
char *cd;
unsigned int c, f;
if (n<=1) return;
m = 2 * n - 1;
HT = (HuffmanTree)malloc((m+1) * sizeof(HTNode)); // 0号单元未用
for (i=1; i<=n; i++) { //初始化
HT[i].weight=w[i-1];
HT[i].info=info[i-1];
HT[i].parent=0;
HT[i].lchild=0;
HT[i].rchild=0;
}
for (i=n+1; i<=m; i++) { //初始化
HT[i].weight=0;
HT[i].parent=0;
HT[i].lchild=0;
HT[i].rchild=0;
}
printf("\n哈夫曼树的构造过程如下所示:\n");
printf("HT初态:\n 结点 weight parent lchild rchild");
for (i=1; i<=m; i++)
printf("\n%4d%8d%8d%8d%8d",i,HT[i].weight,
HT[i].parent,HT[i].lchild, HT[i].rchild);
printf(" 按任意键,继续 ...");
getch();
for (i=n+1; i<=m; i++) { // 建哈夫曼树
// 在HT[1..i-1]中选择parent为0且weight最小的两个结点,
// 其序号分别为s1和s2。
Select(HT, i-1, s1, s2);
HT[s1].parent = i; HT[s2].parent = i;
HT[i].lchild = s1; HT[i].rchild = s2;
HT[i].weight = HT[s1].weight + HT[s2].weight;
printf("\nselect: s1=%d s2=%d\n", s1, s2);
printf(" 结点 weight parent lchild rchild");
for (j=1; j<=i; j++)
printf("\n%4d%8d%8d%8d%8d",j,HT[j].weight,
HT[j].parent,HT[j].lchild, HT[j].rchild);
printf(" 按任意键,继续 ...");
getch();
}
//--- 从叶子到根逆向求每个字符的哈夫曼编码 ---
HC=(HuffmanCode)malloc((n+1)*sizeof(char *));
cd = (char *)malloc(n*sizeof(char)); // 分配求编码的工作空间
cd[n-1] = '\0'; // 编码结束符。
for (i=1; i<=n; ++i) { // 逐个字符求哈夫曼编码
start = n-1; // 编码结束符位置
for (c=i, f=HT[i].parent; f!=0; c=f, f=HT[f].parent)
// 从叶子到根逆向求编码
if (HT[f].lchild==c) cd[--start] = '0';
else cd[--start] = '1';
HC[i] = (char *)malloc((n-start)*sizeof(char));
// 为第i个字符编码分配空间
strcpy(HC[i], &cd[start]); // 从cd复制编码(串)到HC
}
free(cd); // 释放工作空间
} // HuffmanCoding
void CheckCoding()
{ // 将ToBeTra中的正文进行译码并存入CodeFile
……..
}
void HuffmanTranslate()
{ //将CodeFile中的代码进行译码并存入Textfile
…….
}
main()
{ printf("---------------------------------------------\n");
printf(" 赫夫曼编码和译码 \n");
printf(" 1.初始化 \n");
printf(" 2.输入对应的正文内容 \n") ;
printf(" 3.进行赫夫曼编码 \n");
printf(" 4.进行赫夫曼编码 \n") ;
printf(" 5.退出赫夫曼操作 \n");
printf(" 请输入1.2.3.4.5 \n");
printf(" ---------------------------------------------\n");
………
}
- 思考与提高
- 上述CodeFile的基类型实际上可能占用了存放一个整数的空间,只起到示意或模拟的作用。现使CodeFile的基类型package=integer,把哈夫曼码紧缩到一个整形变量中去,最大限度地利用码点存储能力,试改写你的系统。
- 修改你的系统,实现对你的系统的原程序的编码和译码。
- 实现各个转换操作的源/目文件,均由用户在选择此操作时指定。
参考资料
- 范式哈夫曼编码的快速解码技术,范式哈夫曼编码的快速解码技术_Goncely的专栏-CSDN博客_范式哈夫曼编码
- 成绩考核标准
本课程设计的评价由两部分组成,包括答辩(50%)(包括程序演示(30%),回答教师提问(20%))和 课程设计报告(50%)。指导教师根据每个学生必做实验和选做完成情况、实验结果的正确性、选做实验的数量和完成情况进行评分。良好以上要求是独立完成,熟悉源代码,能快速回答老师提问,报告内容详实规范。
- 程序演示:
- 优 功能完善,全部测试正确,并且能够对局部进行完善,能够对不同测试数据进行正确分析。
- 良 功能完善,但测试欠缺。
- 中 功能基本完善,但程序尚有部分错误。
- 及格 完成一定功能。
- 不及格 功能不完善,且程序错误较多,无法运行。
- 课程设计报告:
- 优 包括设计内容,设计思想,已经完成的任务及达到的目标,
设计思路清晰、书写条理清楚,源程序结构合理、清晰,注
释说明完整,有对本次课程设计的心得体会。
- 良 包括设计内容,设计思想,已经完成的任务及达到的目标,
设计思路基本清晰、书写条理基本清楚,源程序结构合理、
清晰,注释说明基本完整,有对本次课程设计的心得体会。
- 中 课程设计报告内容基本完整,思路较清晰,书写基本清楚,
源程序结构尚可,有注释说明但不完整。
- 及格 课程设计报告内容基本完整,思路较差,书写尚清楚。
- 不及格 课程设计报告内容不完整,书写没有条理。
- 回答教师提问:
- 优 能回答教师提出的所有问题,并完全正确,思路清晰。
- 良 基本能回答教师提出的所有问题,有些小错误。
- 中 基本能回答教师提出的问题,少数问题回答错误或不清楚。
- 及格 能回答教师提出的问题,但较多问题回答错误或不能回答。
- 不及格 基本不能回答教师提出的问题。
数据结构与算法课程设计
目 录
- 题目
编写一个基于哈夫曼编码文件压缩/解压系统,一个完整的系统应具有以下基本功能:
- 初始化。给出需要压缩的文件sourcefile.txt,统计不同字符个数及出现次数,建立哈夫曼树,并将哈夫曼树或者字符的编码映射存到文件中,文件名自己定。
- 压缩编码。利用已建好的哈夫曼树,对文件sourcefile.txt的正文进行编码,然后将结果存入文件compressed。可以是01字符序列或者8个01为一个字节的二进制文件,见进阶功能(4)的说明。
- 解压缩。读入compressed文件,利用已建好的哈夫曼树(在内存中)或者读入第一步存储的哈夫曼树文件或者编码映射文件,将compressed解码问中的代码进行译码,结果存入文件uncompressed.txt中。
- 需求分析
在目前计算机储存中,文件过大是非常浪费资源的,同时在给别人传输文件中,文件过大会使文件传输时间过长,此时哈夫曼编码使用变长编码表对源符号(如文件中的一个字母)进行编码,其中变长编码表是通过一种评估来源符号出现机率的方法得到的,出现机率高的字母使用较短的编码,反之出现机率低的则使用较长的编码,这便使编码之后的字符串的平均长度、期望值降低,从而达到无损压缩数据的目的。然后就可以生成一种带有哈夫曼编码的文件,同时又可以使得文件占用的储存减少,
- 基本设计
- 系统结构图
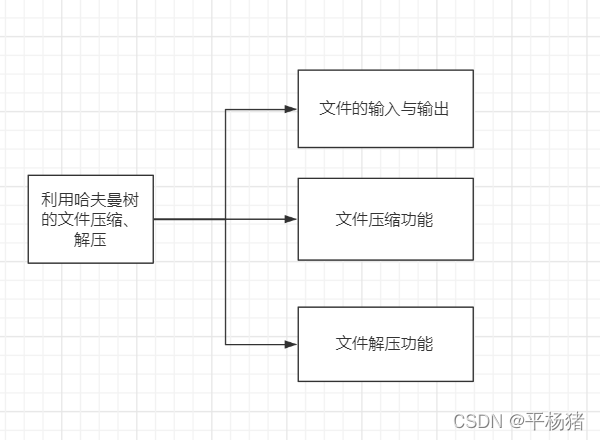
 编辑
编辑
业务流程图
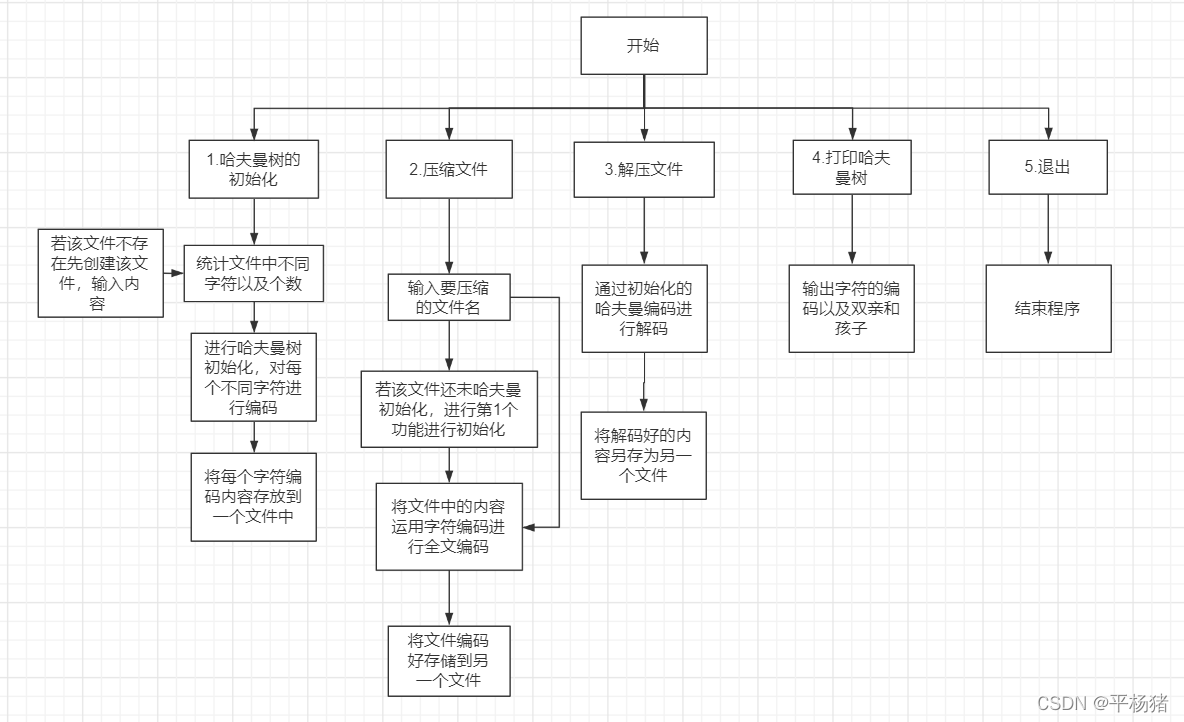
 编辑
编辑
数据结构的设计
ADT HuffmanCoding{
数据对象T:具有相同特性的数据元素的集合
数据关系R:满足最优二叉树的关系
基本操作1:
操作结果:构造一个空哈夫曼树。
基本操作2:
操作结果:利用哈夫曼树进行编码
基本操作3:
操作结果:利用哈夫曼树进行译码
基本操作4:
操作结果:打印哈夫曼树
}
- 程序代码与说明
//file.h #pragma once #include<iostream> #include<stdio.h> #include<stdlib.h> #include<string> #include<cstring> #include<fstream> using namespace std; //统计文件中不同字符个数及出现次数 class File { public: int ch_num = 0;//文件中不同字符的个数 int num[100];//记录26个字母在文件中出现的次数 char ch[255];//文件中各个字符 char file_ch[255];//将文件中不同字符统计到数组中 int file_ch_num[255];//将文件中不同字符出现的次数统计起来(权值) File(); void getifstream(); };

//manage.h #pragma once #include<iostream> #include<stdio.h> #include<stdlib.h> #include<string> #include<cstring> #include<fstream> using namespace std; typedef struct { //创建一个二叉树结构体 char ch; unsigned int weight; //结点权重 unsigned int parent, lchild, rchild; }HTNode, * HuffmanTree; typedef char** HuffmanCode; //字符串数组 class Manage { public: Manage(); int homepage();//进入系统 };

//file.cpp #include"file.h" #include"manage.h" File::File() = default; void creattxt() { cout << "该文件不存在,正在创建该文件" << endl; ofstream out; out.open("sourcefile.txt"); cout << "请输入将要放进文件中的内容:" << endl; char s[1000]; getchar(); gets_s(s); //cout << s << endl; out << s; out.close(); string name="sourcefile.txt"; cout << "该文件创建成功,内容已存入文件中" << endl << endl; } void File::getifstream() { char ch_[100]; string name; cout << "请输入将要压缩的文件名:(给出文件为sourcefile.txt)" << endl; cin >> name; ifstream in(name.c_str()); if (!in) { creattxt(); getifstream(); } string a; getline(in, a); in >> a; //cout << a; for (int i = 0; i <= 100; i++) num[i] = 0; int i; for (i = 0; i <= a.length(); i++) ch[i] = a[i]; ch[i] = '\0'; //cout << endl << ch[5] << endl; for (int i = 0; i < 26; i++) { ch_[i] = 'a' + i; //cout << ch_[i]; } int j = 0; for (int i = 26; i < 52; i++, j++) { ch_[i] = 'A' + j; //cout << ch_[i]; } ch_[52] = ' '; ch_[53] = '.'; //cout << ch_[52] << "1111" << endl; for (int i = 0; i <= a.length(); i++) { //if (ch[i] == ch_[i])num[i]++; if (ch[i] == 'a')num[0]++; if (ch[i] == 'b')num[1]++; if (ch[i] == 'c')num[2]++; if (ch[i] == 'd')num[3]++; if (ch[i] == 'e')num[4]++; if (ch[i] == 'f')num[5]++; if (ch[i] == 'g')num[6]++; if (ch[i] == 'h')num[7]++; if (ch[i] == 'i')num[8]++; if (ch[i] == 'j')num[9]++; if (ch[i] == 'k')num[10]++; if (ch[i] == 'l')num[11]++; if (ch[i] == 'm')num[12]++; if (ch[i] == 'n')num[13]++; if (ch[i] == 'o')num[14]++; if (ch[i] == 'p')num[15]++; if (ch[i] == 'q')num[16]++; if (ch[i] == 'r')num[17]++; if (ch[i] == 's')num[18]++; if (ch[i] == 't')num[19]++; if (ch[i] == 'u')num[20]++; if (ch[i] == 'v')num[21]++; if (ch[i] == 'w')num[22]++; if (ch[i] == 'x')num[23]++; if (ch[i] == 'y')num[24]++; if (ch[i] == 'z')num[25]++; if (ch[i] == 'A')num[26]++; if (ch[i] == 'B')num[27]++; if (ch[i] == 'C')num[28]++; if (ch[i] == 'D')num[29]++; if (ch[i] == 'E')num[30]++; if (ch[i] == 'F')num[31]++; if (ch[i] == 'G')num[32]++; if (ch[i] == 'H')num[33]++; if (ch[i] == 'I')num[34]++; if (ch[i] == 'J')num[35]++; if (ch[i] == 'K')num[36]++; if (ch[i] == 'L')num[37]++; if (ch[i] == 'M')num[38]++; if (ch[i] == 'N')num[39]++; if (ch[i] == 'O')num[40]++; if (ch[i] == 'P')num[41]++; if (ch[i] == 'Q')num[42]++; if (ch[i] == 'R')num[43]++; if (ch[i] == 'S')num[44]++; if (ch[i] == 'T')num[45]++; if (ch[i] == 'U')num[46]++; if (ch[i] == 'V')num[47]++; if (ch[i] == 'W')num[48]++; if (ch[i] == 'X')num[49]++; if (ch[i] == 'Y')num[50]++; if (ch[i] == 'Z')num[51]++; if (ch[i] == ' ')num[52]++; if (ch[i] == '.')num[53]++; } int k = 1; for (int i = 0; i <= 53; i++) { if (num[i] != 0) { ch_num++; file_ch[k] = ch_[i]; file_ch_num[k] = num[i]; k++; } } /*for (int i = 1; i < k; i++) { cout << file_ch[i] << " "; cout << file_ch_num[i] << " "; }*/ //cout << num[0] << endl << ch_num << endl; in.close(); }

//manage.cpp #include"manage.h" #include"file.h" File file; //找到权值最小的两个结点 void Select(HuffmanTree& HT, int end, int* s1, int* s2) { int i, j, min1, min2; //找到第一个权值最小的数 for (j = 1; j <= end; j++) { if (HT[j].parent == 0) { min1 = j; break; } } for (i = j + 1; i <= end; i++) { if (HT[i].weight < HT[min1].weight && HT[i].parent == 0) { min1 = i; } } //找到第二个权值最小的数 for (j = 1; j <= end; j++) { if (HT[j].parent == 0 && j != min1) { min2 = j; break; } } for (i = j + 1; i <= end; i++) { if (HT[i].weight < HT[min2].weight && HT[i].parent == 0 && min1 != i) { min2 = i; } } //更小的数是左结点 if (min1 > min2) { *s1 = min2; *s2 = min1; } if (min1 < min2) { *s1 = min1; *s2 = min2; } } //哈夫曼树初始化与哈夫曼编码 void HuffmanCoding(HuffmanTree& HT, HuffmanCode& HC, int n) { int m, i,s1,s2, start, f, c;//m为总结点个数,s1、s2分别为权值最小的两个结点 char* cd, z; if (n <= 1) return; m = 2 * n - 1; //总共的结点数 HT = (HuffmanTree)malloc((m + 1) * sizeof(HTNode));// 0号单元未用 for (i = 1; i <= m; i++) //初始化 { HT[i].ch = '0'; HT[i].weight = 0; HT[i].parent = 0; HT[i].lchild = 0; HT[i].rchild = 0; } for (i = 1; i <= n; i++) { HT[i].ch = file.file_ch[i]; HT[i].weight = file.file_ch_num[i]; HT[i].parent = 0; HT[i].lchild = 0; HT[i].rchild = 0; } //建哈夫曼树 for (i = n + 1; i <= m; ++i) { Select(HT, i - 1, &s1, &s2); HT[s1].parent = i; HT[s2].parent = i; HT[i].lchild = s1; HT[i].rchild = s2; HT[i].weight = HT[s1].weight + HT[s2].weight; } //--- 从叶子到根逆向求每个字符的哈夫曼编码 --- HC = (HuffmanCode)malloc((n + 1) * sizeof(char*)); cd = (char*)malloc(n * sizeof(char));// 分配求编码的工作空间 cd[n - 1] = '\0'; // 编码结束符 for (i = 1; i <= n; ++i) { // 逐个字符求哈夫曼编码 start = n - 1; // 编码结束符位置 for (c = i, f = HT[i].parent; f != 0; c = f, f = HT[f].parent) //一次循环结束后,再向上一轮 { if (HT[f].lchild == c) cd[--start] = '0'; //如果是其左结点,就存0;右节点寸1 else cd[--start] = '1'; } HC[i] = (char*)malloc((n - start) * sizeof(char));// 为第i个字符编码分配空间 strcpy(HC[i], &cd[start]);// 从cd复制编码(串)到HC } free(cd); } Manage::Manage() =default; int Manage::homepage() { int j, i, m, choice_ = 0;//choice_判断是否选择1选项初始化 char str[1000]; int choice = 0; ifstream input; ofstream output; HuffmanTree HT; HuffmanCode HC; while (true) { cout << "********************************************" << endl; cout << "* *" << endl; cout << "* 基于哈夫曼编码的文件压缩与解压 *" << endl; cout << "* 请输入您的功能选择 *" << endl; cout << "* *" << endl; cout << "* 1.哈夫曼树初始化 *" << endl; cout << "* 2.文件编码(压缩) *" << endl; cout << "* 3.文件译码(解压) *" << endl; cout << "* 4.打印哈夫曼树的内容 *" << endl; cout << "* 5.退出 *" << endl; cout << "* *" << endl; cout << "********************************************" << endl; cin >> choice; if (choice == 1) { if (choice_ == 2 || choice_ == 1) cout << "您已经初始化过哈夫曼树" << endl; else file.getifstream(); HuffmanCoding(HT, HC, file.ch_num); //初始化哈夫曼树 cout << endl << "字母的编码为:" << endl; for (i = 1; i <= file.ch_num; i++) { cout << "(" << HT[i].ch << ")" << ":" << HC[i] << "||"; //输出换算过的编码 } output.open("hfmTree.txt"); for (i = 1; i <= file.ch_num; i++) { output << "(" << HT[i].ch << ")" << ":" << HC[i] << endl; } output.close(); cout << endl << endl << "哈夫曼树初始化成功,已放入hfmtree.txt文件中" << endl << endl; choice_ = 1; } if (choice == 2) { if(choice_==0) { file.getifstream(); choice_ = 2; } HuffmanCoding(HT, HC, file.ch_num); cout << "将sourcefile.txt文件进行编码" << endl; string name = "sourcefile.txt"; ifstream in(name.c_str()); string str; getline(in, str); in >> str; output.open("compressed.txt"); //再新建编码后的文件 for (i = 0; i < str.length(); i++) { for (j = 0; j <= file.ch_num; j++) //与文件中的字符比较 { if (HT[j].ch == str[i]) { output << HC[j]; break; } } } output.close(); cout << endl << "编码已完成,并且已存入compressed.txt文件中" << endl << endl; input.open("compressed.txt"); if (!input) { cout << "无法打开compressed" << endl; return 1; } input >> str; cout << "编码值为:" << str << endl << endl; input.close(); } if (choice == 3) { HuffmanCoding(HT, HC, file.ch_num); input.open("compressed.txt"); input >> str; input.close(); output.open("uncompressed.txt"); //新建存放译码后的文件 m = 2 * file.ch_num - 1; //到根结点数组坐标(总结点个数) for (i = 0; str[i] != '\0'; i++) { if (str[i] == '0') { m = HT[m].lchild;//返回左孩子的数组坐标 } else if (str[i] == '1') { m = HT[m].rchild; } if (HT[m].lchild == 0 && HT[m].rchild == 0) { output << HT[m].ch; m = 2 * file.ch_num - 1;//从根结点继续译码 } } output.close(); string name = "uncompressed.txt"; ifstream in(name.c_str()); string str; getline(in, str); in >> str; cout << "解压后的内容为:" << endl; cout << str << endl; input.close(); cout << "译码已完成,并且已存入uncompressed.txt文件中" << endl << endl; } if (choice == 4) { HuffmanCoding(HT, HC, file.ch_num); cout << endl; for (int i = 1; i <=file.ch_num; i++) { cout << "number char weight code parent lchild rchild " << endl; cout << i << " " << HT[i].ch << " " << HT[i].weight << " " << HC[i] << " " << HT[i].parent << " " << HT[i].lchild << " " << HT[i].rchild << endl; } for (int i = file.ch_num + 1; i <=2 * file.ch_num - 1; i++) { cout << "number weight parent lchild rchild" << endl; cout << i << " " << HT[i].weight<<" "<<HT[i].parent << " " << HT[i].lchild << " " << HT[i].rchild << " " << endl; } cout << endl; } if (choice == 5) break; if (choice != 1 && choice != 2 && choice != 3 && choice != 4 && choice != 5) cout << "您的输入有误,请重新输入!" << endl<<endl; } }

//main.cpp #include"manage.h" int main() //主函数 { Manage manage; manage.homepage(); return 0; }

- 运行结果与分析
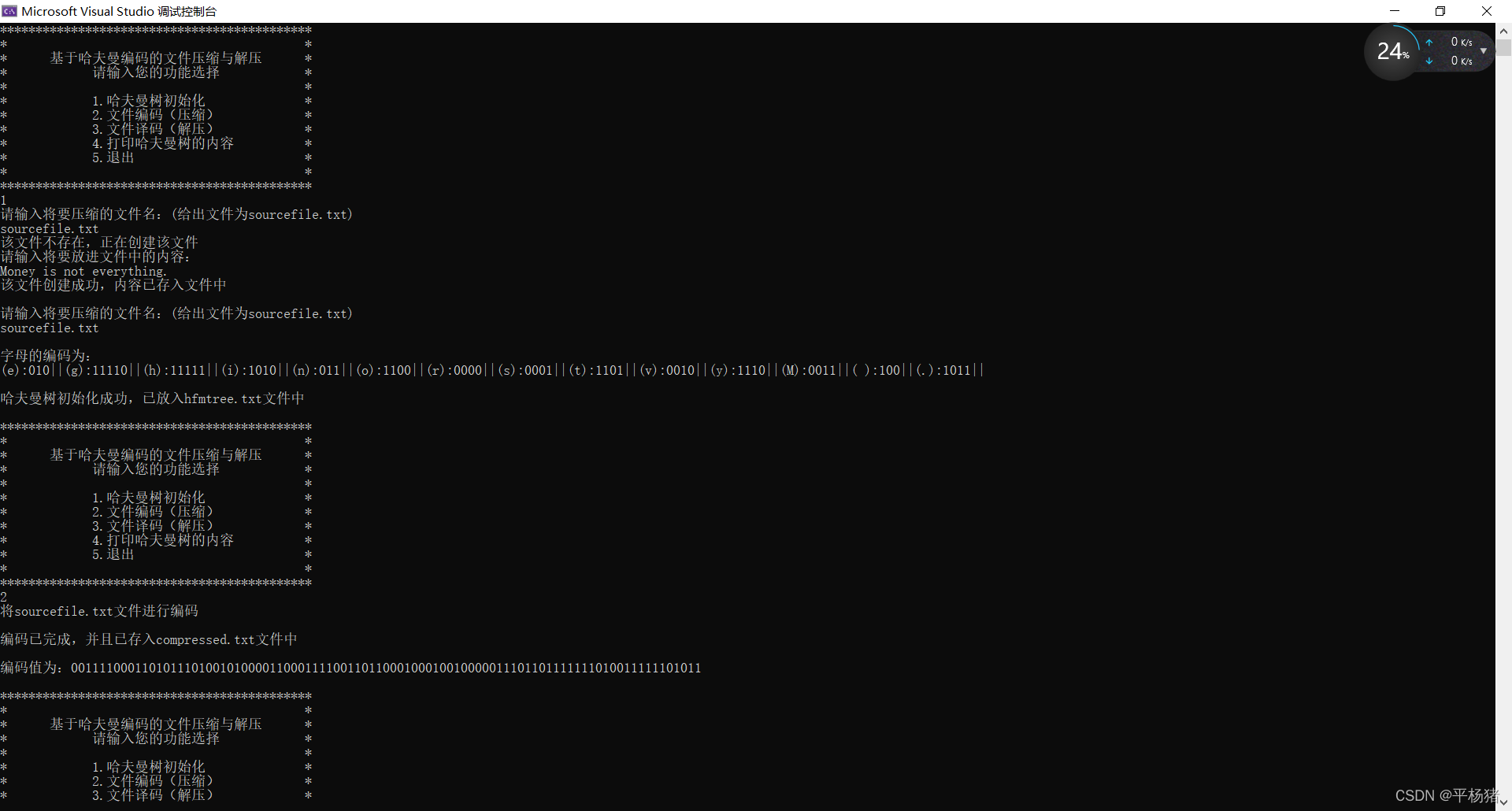
 编辑
编辑
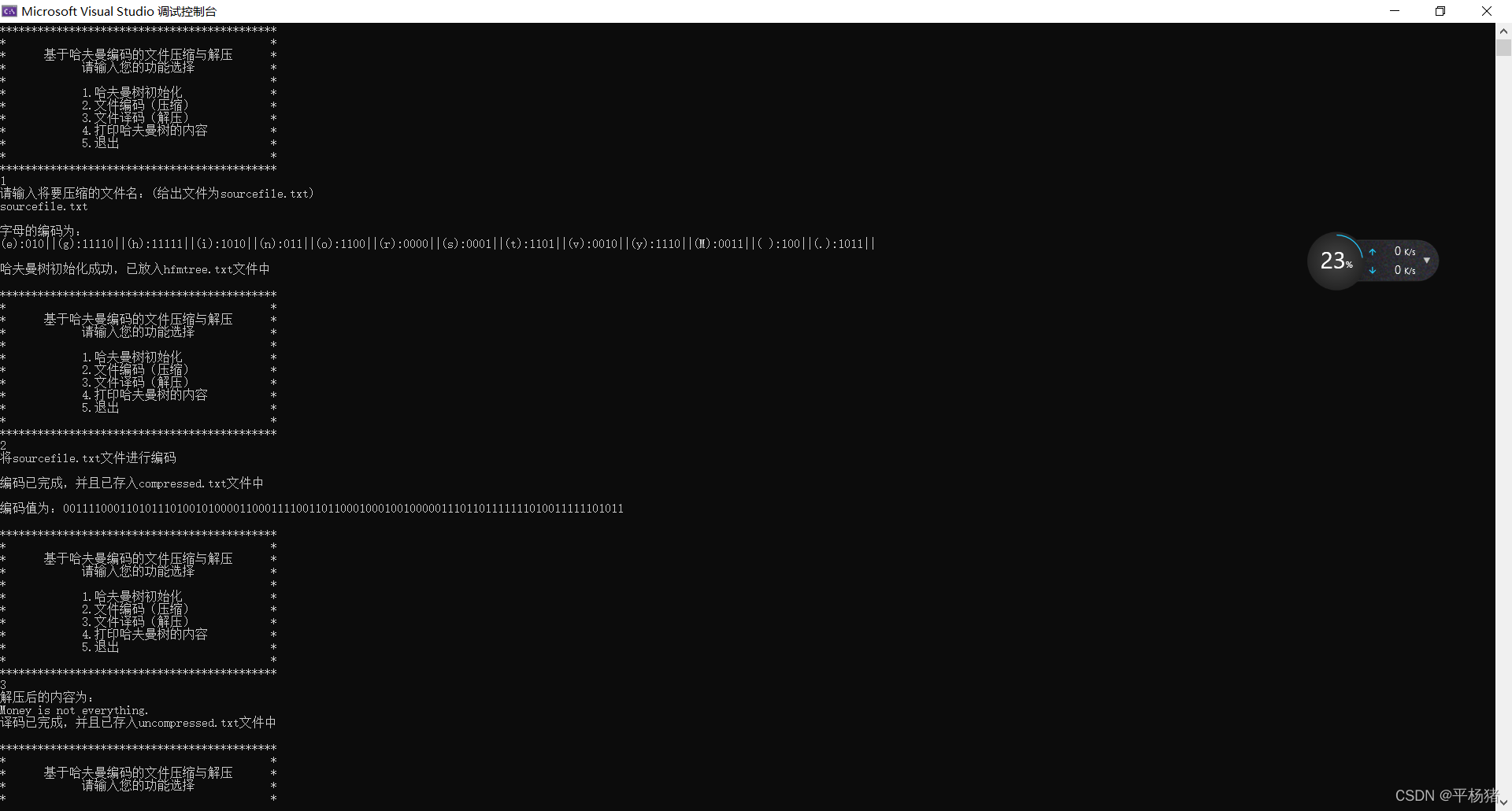
1.(1)此时在代码的当前路径下没有sourcefile.txt文件,系统会自动生成sourcefile.txt文件,输入你将要放入文件中的内容并存入sourcefile.txt文件中。然后开始统计文件中不同字符个数及出现次数(权值),最后开始初始化哈夫曼树。字符的编码映射存到文件hfmTree.txt中。
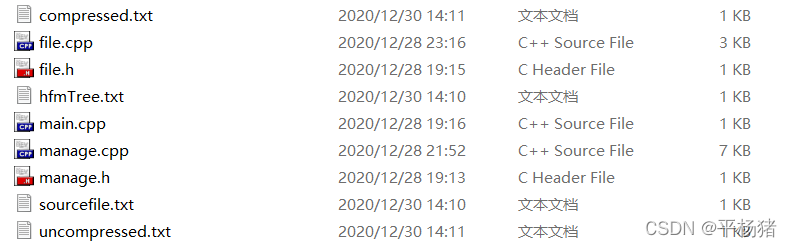
 编辑对没有的文件都是系统自动生成
编辑对没有的文件都是系统自动生成
 编辑
编辑
(2)与上面截图情况不同的是,在当前路径下有该文件,并且该文件中有内容,此时开始统计文件中不同字符个数及出现次数,然后初始化哈夫曼树。字符的编码映射存到文件hfmTree.txt中。
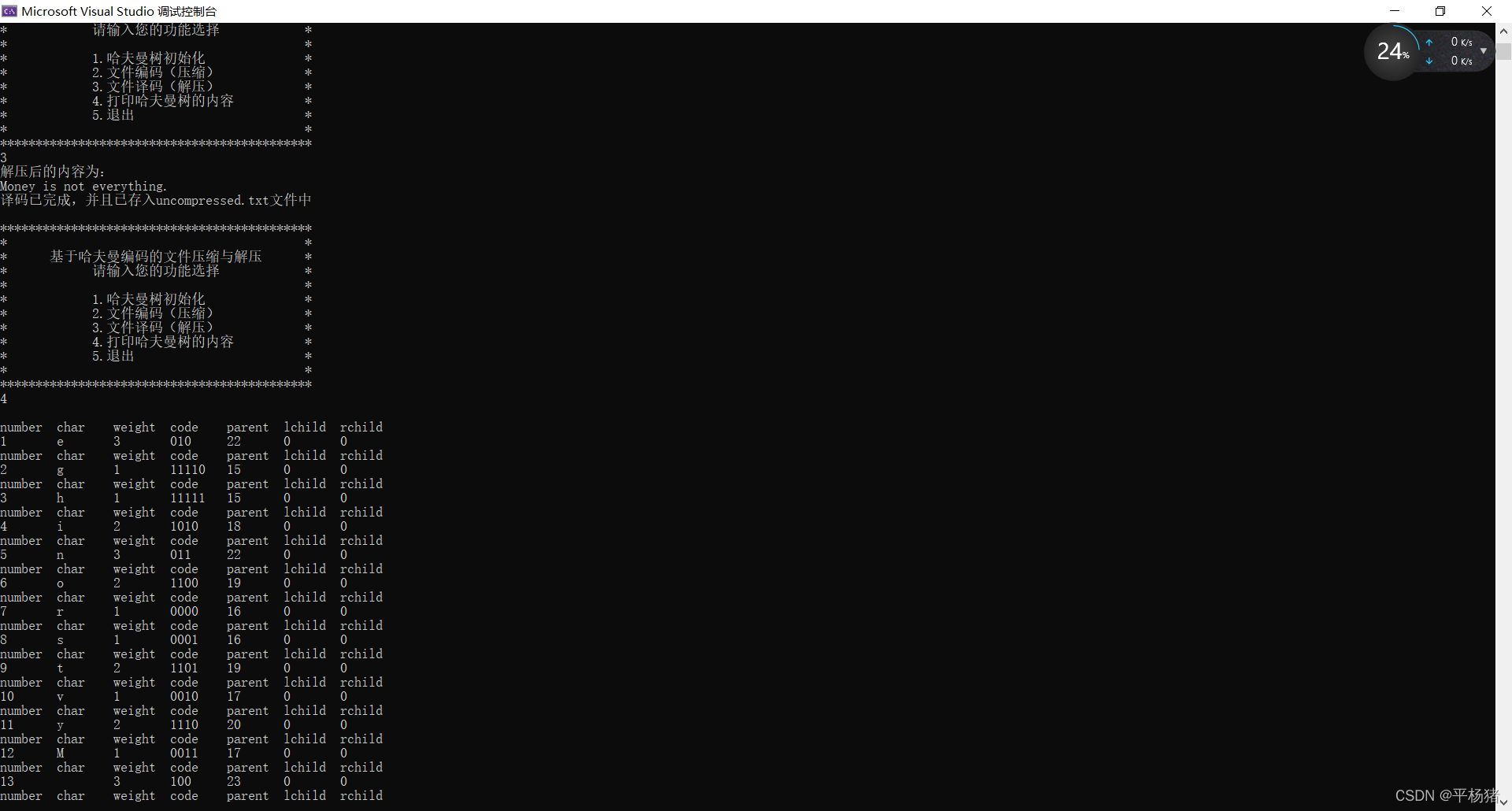
2.对文件sourcefile.txt的正文进行编码,然后将结果存入文件compressed.txt中
 编辑
编辑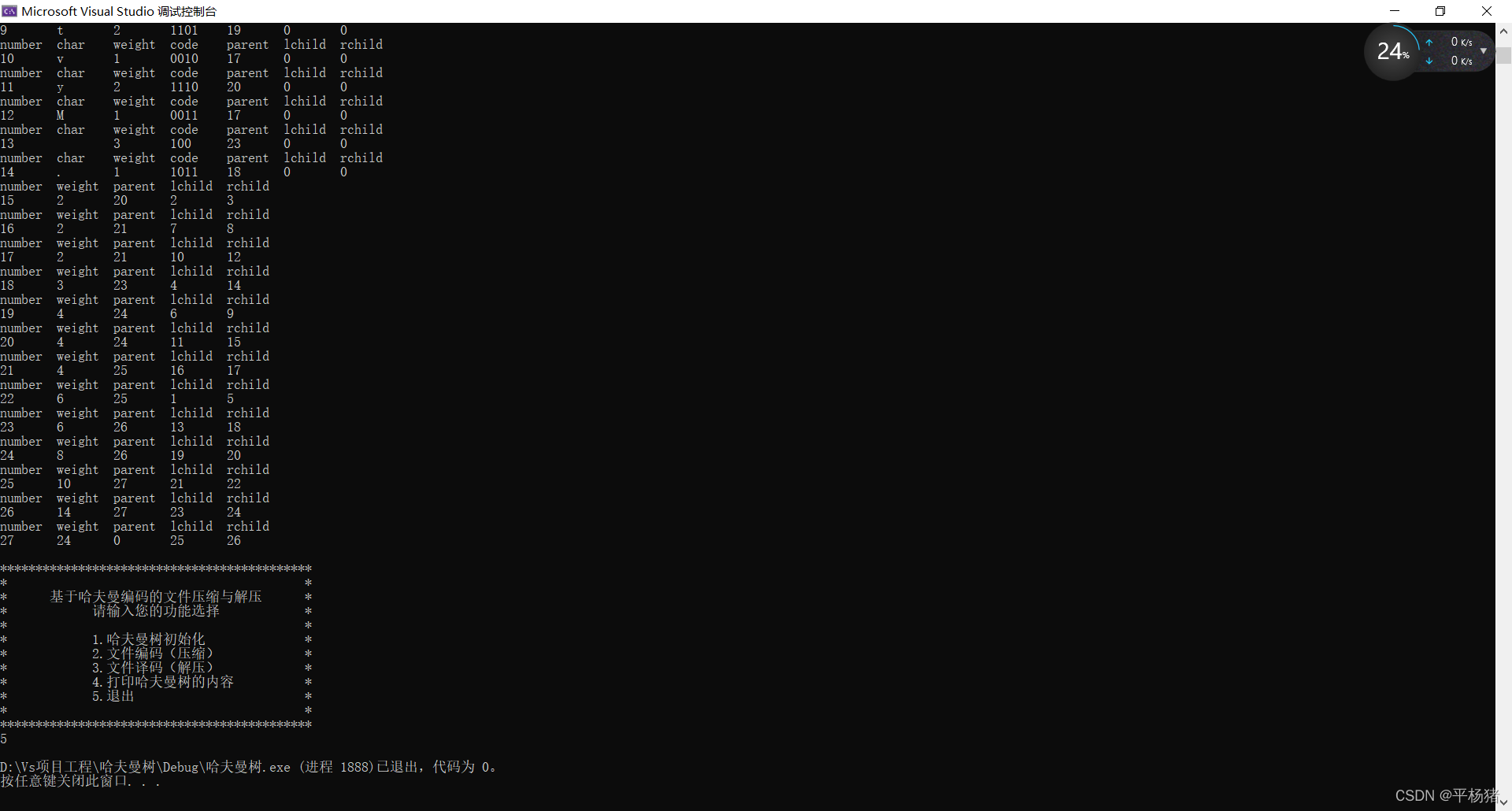
 编辑
编辑
3.不管是1的(1)或(2)的情况,以上二个截图实现效果都一样,从文件compressed.txt中读取01序列,然后通过第一个字符到往后从根结点到叶子结点寻找哈夫曼树中对应的字符,以此类推。(译码过程)将译码内容存放到uncompressed.txt文件中。然后读取文件,将文件内容(译码内容)输出到窗口中。
4.输出哈夫曼树各个结点的权值以及编码、双亲和孩子的值。
 编辑
编辑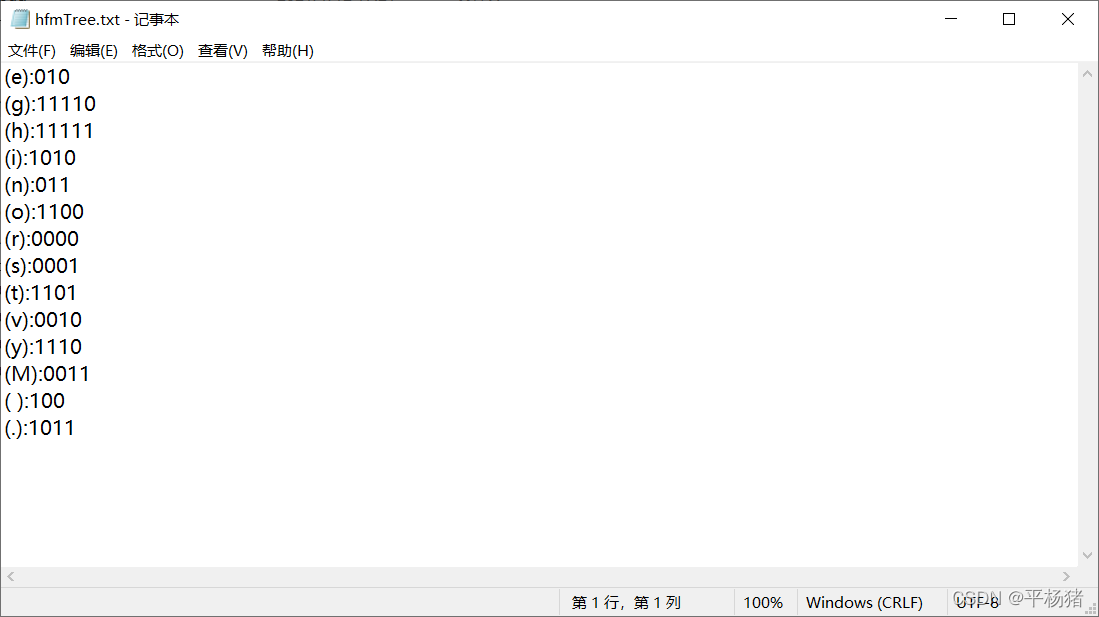
 编辑
编辑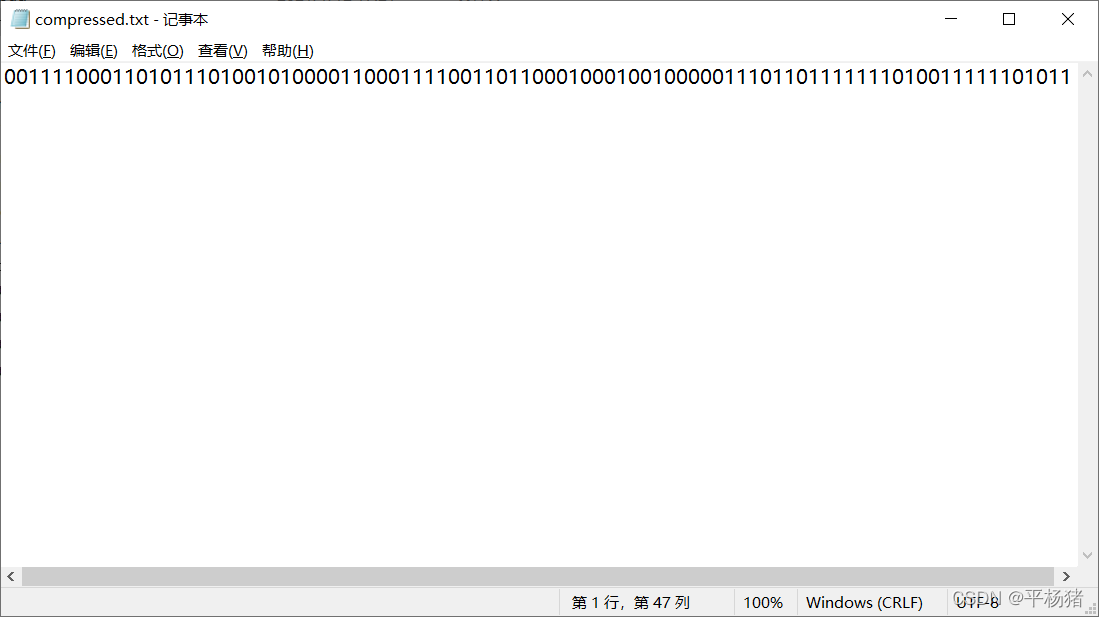
 编辑
编辑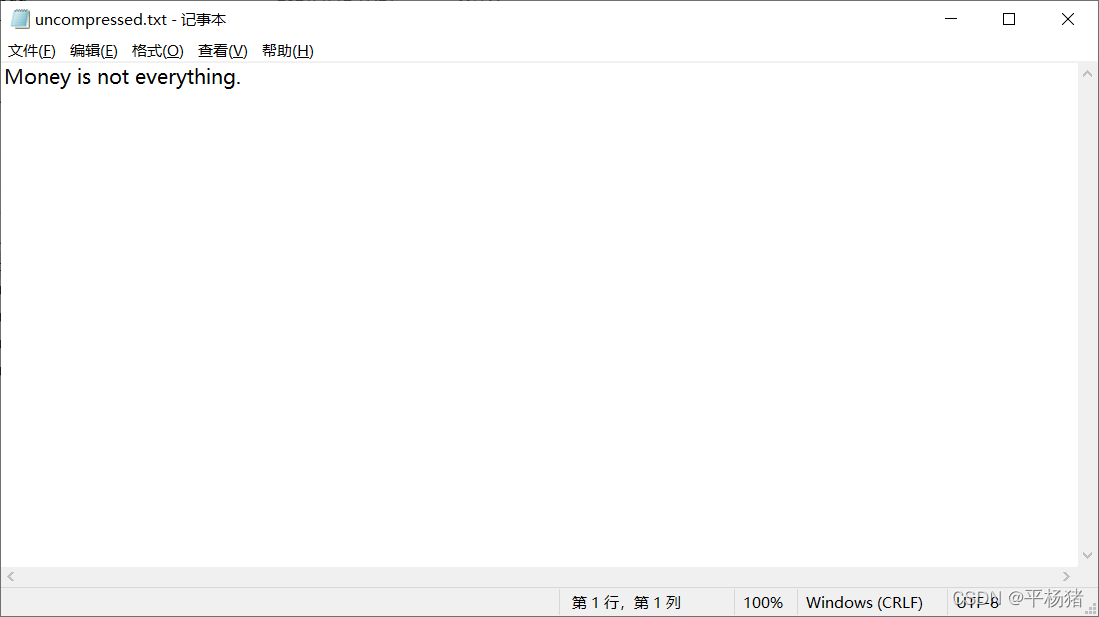
 编辑
编辑
以上txt文件就是代码运行后的输出情况
- 心得与体会
本次实验的内容为哈夫曼树的数据结构,从中学习到数据结构中哈夫曼树的初始化,哈夫曼树是最优的二叉树。通过哈夫曼树可以对文件中的内容进行编码,从而达到最小内存的使用。通过本次的实验,也是运用哈夫曼树将文件中的字符统计起来,从而初始化最优二叉树,达到对字符的编码,可以对文件的内容进行保护并且内存得以优化。对于此实验收获颇多,深刻认识到了什么是数据结构,对数据结构也有了进一步的学习和深入,对今后的其他课的学习有了初步的基础。

