1. JDK Hadoop Spark安装与配置
1.1 解压包
官网下载jdk、hadoop、sprak对应的包,注意版本
tar -zxvf jdk-8u241-linux-x64.tar.gz tar -zxvf hadoop-3.2.2.tar.gz tar -zxvf spark-3.2.0-bin-hadoop3.2.taz

1.2 配置环境变量
添加配置,注意文件路径以及文件名
vim /root/.bashrc
export JAVA_HOME=/root/ClassWork/jdk1.8.0_241 export CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar export PATH=$PATH:${JAVA_HOME}/bin export HADOOP_HOME=/root/ClassWork/hadoop-3.2.2 export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib" export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath --glob):$CLASSPATH export SPARK_HOME="/root/ClassWork/spark-3.2.0-bin-hadoop3.2" export PATH=$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH
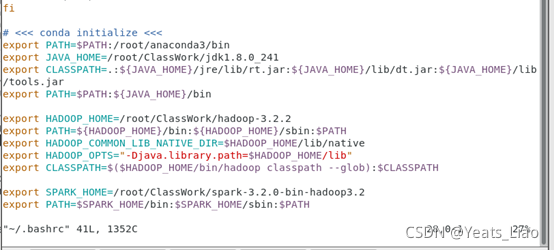
使配置生效
source /root/.bashrc
2. Scala安装与配置
2.1 Scala安装
wget http://www.scala-lang.org/files/archive/scala-2.11.8.tgz
tar -zxf scala-2.11.8.tgz
2.2 配置环境变量
添加配置
vim /root/.bashrc
export SCALA_HOME=/root/ClassWork/scala-2.11.8 export PATH=$PATH:$SCALA_HOME/bin source /root/.bashrc
使配置生效
source /root/.bashrc
3. 配置集群
3.1 配置sprak
进入sprak的conf文件夹
把spark-env.sh.template复制一份spark-env.sh
cp spark-env.sh.template spark-env.sh
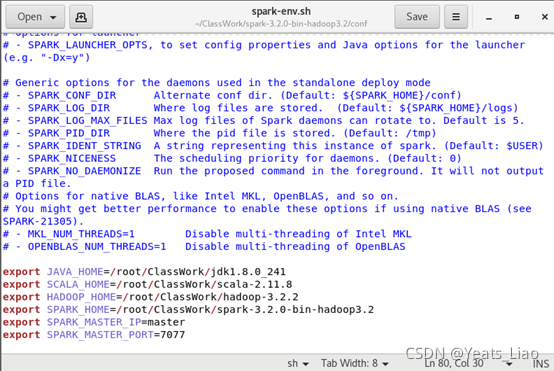
vim spark-env.sh
加入以下配置,注意目录以及版本号,对应上面第1步下载的版本
export JAVA_HOME=/home/hadoop/jdk1.8.0_241 export SCALA_HOME=/home/hadoop/scala-2.11.8 export HADOOP_HOME=/home/hadoop/hadoop-3.2.2 export SPARK_HOME=/home/hadoop/spark-3.2.0-bin-hadoop3.2 export SPARK_MASTER_IP=master export SPARK_MASTER_PORT=7077
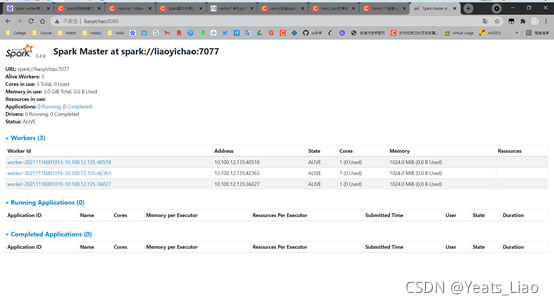
3.2 启动spark
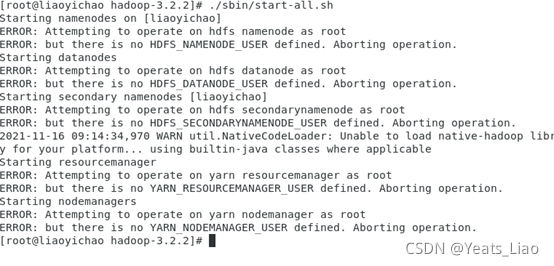
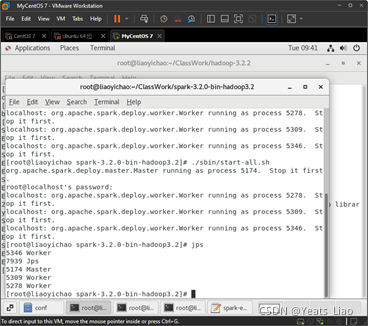
进入hadoop安装目录,启动hadoop
/sbin/start-all.sh
在进入spark安装目录,启动spark
/sbin/start-all.sh

然后输入jps,看到了进程,说明已经启动了spark
4. 问题:虚拟机能运行,本机却不行?
原因:Centos防火墙拦截了端口
解决方法2选1
4.1 关闭Centos防火墙
查看防火墙状态
systemctl status firewalld.service
看到绿色字样标注的“active(running)”,说明防火墙是开启状态

停止防火墙
systemctl stop firewalld
4.2 如果不关闭防火墙,则开放端口
查看已开放的端口
firewall-cmd --list-ports
开放端口(上面配置的端口)
firewall-cmd --zone=public --add-port=8080/tcp --permanent
重启防火墙
firewall-cmd --reload
解决