
@[TOC](StackGAN++: Realistic Image Synthesis with Stacked GAN(具有堆叠式生成对抗网络的逼真的图像合成))
这篇文章主要工作是:将原先的Stack GAN的两阶段的堆叠结构改为了树状结构。包含有多个生成器和判别器,它们的分布像一棵树的结构一样,并且每个生成器产生的样本分辨率不一样。另外对网络结构也进行了改进。
文章被2017年ICCV(International Conference on Computer Vision)会议录取。
论文地址: https://arxiv.org/pdf/1710.10916v3.pdf
代码地址: https://github.com/hanzhanggit/StackGAN-v2
本博客是精读这篇论文的报告,包含一些个人理解、知识拓展和总结。这篇文章介绍了StackGAN-v1,其在上篇博客Text to image论文精读:StackGAN中已经进行讲解,本篇博客只对StackGAN-v2的内容进行总结。
一、摘要
尽管生成性对抗网络(GAN)在各种任务中取得了显著的成功,但它们在生成高质量图像方面仍然面临挑战。在本文中,我们提出了堆叠生成对抗网络(StackGANs),旨在生成高分辨率照片真实感图像。首先,我们提出了一种用于文本图像合成的两阶段生成对抗性网络体系结构StackGAN-v1。Stage-I GAN根据给定的文本描述绘制场景的原始形状和颜色,生成低分辨率图像。阶段II GAN将阶段I结果和文本描述作为输入,并生成具有照片真实细节的高分辨率图像。其次,针对条件生成任务和无条件生成任务,提出了一种先进的多级生成对抗网络体系结构StackGAN-v2。我们的StackGAN-v2由多个发生器和多个鉴别器组成,以树状结构排列;从树的不同分支生成对应于同一场景的多个比例的图像。通过联合逼近多个分布,StackGAN-v2显示出比StackGAN-v1更稳定的训练行为。大量实验表明,所提出的堆叠生成对抗网络在生成照片真实感图像方面明显优于其他最先进的方法。
二、关键词
Text to Image, Generative Adversarial Network, Image Synthesis, Computer Vision
三、为什么要提出StackGAN-v2?
通过在多个尺度上建模数据分布,如果这些模型分布中的任何一个与该尺度上的真实数据分布共享支持,则堆叠结构可以提供良好的梯度信号,以加速或稳定整个网络在多个尺度上的训练。例如,在第一层近似低分辨率图像分布会产生具有基本颜色和结构的图像。然后,后续分支的生成器可以专注于完成细节,以生成更高分辨率的图像。
简单的来说就是:如果任何一个尺度的生成图片与该尺度的真实图片的分布尽可能的近似,那么就能够提供很好的梯度信号去稳定或促进真个网络的训练。
实验证明:StackGAN-v2显示出更稳定的训练行为,并在大多数数据集上获得更好的FID和初始分数,且相比v1来说,其不会出现模式崩溃的问题。
四、主要内容
4.1 StackGAN-v1与StackGAN-v2
StackGAN-v1有两个独立的网络,第一阶段GAN和第二阶段GAN,用于对低分辨率到高分辨率的图像分布进行建模。
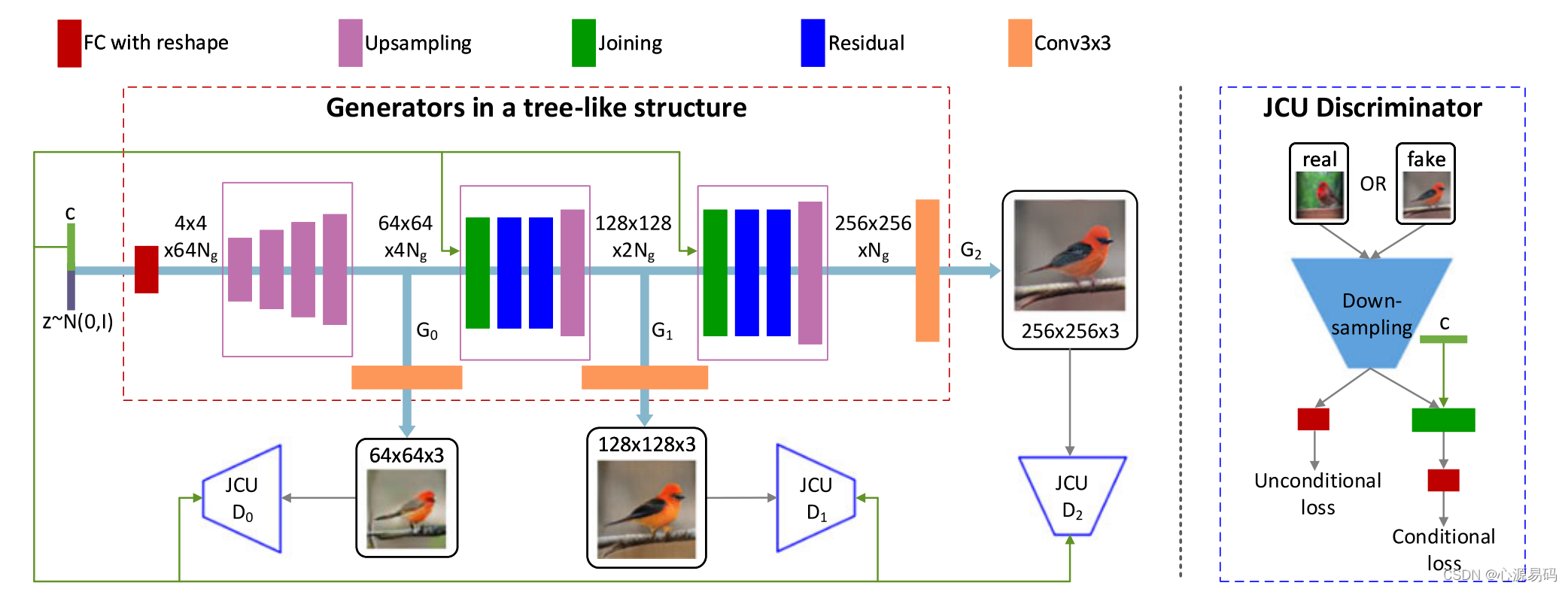
为了使框架更具通用性,本文提出了一种新的端到端网络StackGAN-v2,用于模拟一系列多尺度图像分布。而StackGAN-v2由树状结构的多个生成器(G)和多个鉴别器(D)组成。从低分辨率到高分辨率的图像是从树的不同分支生成的。在每个分支上,生成器捕获该尺度的图像分布,鉴别器分辨来自该尺度样本的真假。对生成器进行联合训练以逼近多个分布,并且以交替方式对生成器和鉴别器进行训练。
4.2 多尺度图像分布
每个生成器都有其隐藏特征,第一个生成器的隐藏特征为h0=F0 (z),其中z为噪声,通常采用标准正态分布,第i个生成器的隐藏特征为hi=Fi (h(i-1),z),即噪声与隐层特征h(i-1)共同作为计算hi的输入,如此生成器产生小尺度到大尺度的样本。
 在这里插入图片描述
在这里插入图片描述
4.3 联合条件和无条件分布
无条件图像生成:鉴别器从生成的图像中鉴别出真实图像。
条件图像生成:将图像及其相应的条件变量(如text embedding)输入到鉴别器中以确定图像和条件变量是否匹配,这引导生成器近似条件图像分布。即:在h_0 中h_0=F_0 (c,z),z表示随机噪声,但是在后面层次h_i 中h_i=F_i (h_(i-1),c),c表示条件向量。训练条件StackGAN-v2鉴别器D的目标函数现在由两项组成:无条件损失和条件损失,如下图:
 在这里插入图片描述
在这里插入图片描述
 在这里插入图片描述
在这里插入图片描述
4.4 颜色一致性正则化
当我们在不同的生成器上提高图像分辨率时,不同尺度下生成的图像应该具有相似的基本结构和颜色。因此引入颜色一致性正则化项,以保持不同生成器上相同输入生成的样本在颜色上更加一致,从而提高生成图像的质量。颜色一致性正则化项旨在最小化不同尺度之间的纹理差异。
令Xk=(R,G,B)^T用来表示生成的图片中的一个像素,然后计算
 在这里插入图片描述
在这里插入图片描述
计算均值和方差,N表示像素总数 。
颜色一致性正则化项旨在最小化下面的公式,进而能够最小化每个尺度间的均值和方差的差异。
 在这里插入图片描述
在这里插入图片描述
4.5 实施细节
 在这里插入图片描述
在这里插入图片描述
模型被设计最终生成256256图像,输入向量(噪声z和text embedding)首先被设置为4464N_g,其中N_g是通道数,通过生成器分别被转化为64644N_g、1281282N_g、2562561N_g,条件变量或无条件变量也直接输入网络的中间层,以确保编码信息不被忽略。而所有鉴别器都有下采样块和33的卷积核,鉴别器将图像转为448N_g,最后通过sigmoid函数输出判断概率。
五、实验
5.1 度量标准
Inception Score(IS):IS=exp(EX Dkl (p(y|x)||p(y))),边际分布p(y)和条件分布p(y|x)的KL散度,IS越大越好。
Frechet inception distance(FID):FID测量合成的数据分布和真实数据分布的距离,
 在这里插入图片描述
在这里插入图片描述
其中m和C表示从生成数据中得出的均值和方差,mr和Cr表示从真实数据中得出的均值和方差。FID越小越好。
5.2 实验结果
 在这里插入图片描述
在这里插入图片描述
 在这里插入图片描述
在这里插入图片描述
 在这里插入图片描述
在这里插入图片描述
5.3 StackGAN-v1和StackGAN-v2的比较
 在这里插入图片描述
在这里插入图片描述
端到端训练方案以及颜色一致性正则化使StackGAN-v2能够为每个分支生成更多反馈和正则化,从而在多步骤生成过程中更好地保持一致性。通过联合优化多个分布,StackGAN-v2显示出更稳定的训练行为,并在大多数数据集上获得更好的FID和初始分数,但训练时收敛速度慢于v1且需要更多GPU资源。
t-SNE是检验综合分布和评估其多样性的良好工具,利用 t-SNE去对由StackGAN-v1和StackGAN-v2在CUB测试集上生成的图片做模型的坍塌实验。结果显示StackGAN-v1会有两个部分的模式坍塌,而StackGAN-v2没有:
 在这里插入图片描述
在这里插入图片描述
5.4 一些失败案例
 在这里插入图片描述
在这里插入图片描述
将失败分为轻度、中度和重度。轻度指生成的图像具有平滑、连贯的外观,但缺少生动的对象;中度指生成的图像具有明显的伪影,通常是模式崩溃的迹象;重度指表示生成的图像处于模式崩溃。通过实验发现StackGAN-v2能有效避免模式崩溃的重度失败。
5.5 消融实验
 在这里插入图片描述
在这里插入图片描述
StackGAN-v2-no-JCU表示去掉共同近似条件分布和无条件分布模块;StackGAN-v2-G2表示只用G2而并不用G0和G1先生成模糊图像;StackGAN-v2-3G2表示用3个G2但噪声不同来生成图像;StackGAN-v2-allG2表示用3个G2组成堆叠结构来生成图像。实验证明StackGAN-v2结构的有效性。
 在这里插入图片描述
在这里插入图片描述
颜色一致性正则化的消融实验(第一行是没有,第二行有)。结果表明,颜色一致性正则化提供的附加约束能够促进多分布近似,并帮助不同分支的生成器生成更多的相干样本。
六、心得与体会
本篇文章的创新点有三:
(1) 将原先的Stack GAN的两阶段的堆叠结构改为了树状结构。包含有多个生成器和判别器,它们的分布像一棵树的结构一样,并且每个生成器产生的样本分辨率不一样,这样的多尺度的图片分布的好处在于:如果任何一个尺度的生成图片与该尺度的真实图片的分布尽可能的近似,那么就能够提供很好的梯度信号去稳定或促进整个网络的训练。
(2) 在判别器的模型中加入了有条件和无条件的损失函数
(3) 加入颜色一致性正则化,这能够保证来自同一输入的向量在不投的生成器端在色彩上尽量保持一致,从而能够保证最终生成的256 x 256的图片的质量。
相关阅读
Text to image(T2I)论文整理 阅读路线和阅读指南
下一篇:AttnGAN: Fine-Grained TexttoImage Generation with Attention(带有注意的生成对抗网络细化文本到图像生成)

