
微信公众号:@蚝油菜花|如果你也关注大模型发展现状,或对大模型应用开发非常感兴趣,很期待你的关注和私信,我会不定期分享自己的想法和开源实例。

能力说明:
通过课程学习与实战项目,熟练掌握Python的语法知识与编程技能,具备Python语言的函数、面向对象、异常处理等能力,常用开发框架的实际应用和开发能力,具备使用,掌握Python数据分析三剑客Matplotlib、Numpy、Pandas的概念与应用场景,掌握利用Python语言从数据采集到分析的全流程相关知识。
暂时未有相关云产品技术能力~
阿里云技能认证
详细说明2025年04月
 发表了文章
2025-04-06 00:31:53
发表了文章
2025-04-06 00:31:53
 发表了文章
2025-04-04 11:06:44
发表了文章
2025-04-04 11:06:44
 发表了文章
2025-04-04 11:06:08
发表了文章
2025-04-04 11:06:08
 发表了文章
2025-04-04 11:05:26
发表了文章
2025-04-04 11:05:26
 发表了文章
2025-04-04 11:05:09
发表了文章
2025-04-04 11:05:09
 发表了文章
2025-04-04 11:04:44
发表了文章
2025-04-04 11:04:44
 发表了文章
2025-04-04 11:04:17
发表了文章
2025-04-04 11:04:17
 发表了文章
2025-04-04 11:03:06
发表了文章
2025-04-04 11:03:06
 发表了文章
2025-04-02 22:48:11
发表了文章
2025-04-02 22:48:11
 发表了文章
2025-04-02 22:47:51
发表了文章
2025-04-02 22:47:51
 发表了文章
2025-04-02 22:47:26
发表了文章
2025-04-02 22:47:26
 发表了文章
2025-04-01 21:47:48
发表了文章
2025-04-01 21:47:48
 发表了文章
2025-04-01 21:47:27
发表了文章
2025-04-01 21:47:27
 发表了文章
2025-04-01 21:46:20
发表了文章
2025-04-01 21:46:20
 发表了文章
2025-04-01 21:45:33
发表了文章
2025-04-01 21:45:33
 发表了文章
2025-04-01 21:45:05
发表了文章
2025-04-01 21:45:05
 发表了文章
2025-04-01 21:44:39
发表了文章
2025-04-01 21:44:39
 发表了文章
2025-04-01 21:43:21
发表了文章
2025-04-01 21:43:21
 发表了文章
2025-04-01 21:42:57
发表了文章
2025-04-01 21:42:57
 发表了文章
2025-04-01 21:42:40
发表了文章
2025-04-01 21:42:40
 发表了文章
2025-04-01 18:32:17
发表了文章
2025-04-01 18:32:17
 发表了文章
2025-04-01 17:51:39
发表了文章
2025-04-01 17:51:39

2025年03月
发表了文章
2025-03-31 20:40:05
 发表了文章
2025-03-31 20:39:47
发表了文章
2025-03-31 20:39:47
 发表了文章
2025-03-31 20:39:22
发表了文章
2025-03-31 20:39:22
 发表了文章
2025-03-31 20:39:05
发表了文章
2025-03-31 20:39:05
 发表了文章
2025-03-31 20:38:09
发表了文章
2025-03-31 20:38:09
 发表了文章
2025-03-31 20:36:33
发表了文章
2025-03-31 20:36:33
 发表了文章
2025-03-31 20:36:11
发表了文章
2025-03-31 20:36:11
 发表了文章
2025-03-29 00:23:46
发表了文章
2025-03-29 00:23:46
 发表了文章
2025-03-29 00:23:27
发表了文章
2025-03-29 00:23:27
 发表了文章
2025-03-29 00:23:07
发表了文章
2025-03-29 00:23:07
 发表了文章
2025-03-29 00:22:44
发表了文章
2025-03-29 00:22:44
 发表了文章
2025-03-29 00:22:20
发表了文章
2025-03-29 00:22:20
 发表了文章
2025-03-29 00:21:58
发表了文章
2025-03-29 00:21:58
 发表了文章
2025-03-28 10:10:49
发表了文章
2025-03-28 10:10:49
 发表了文章
2025-03-28 10:10:30
发表了文章
2025-03-28 10:10:30
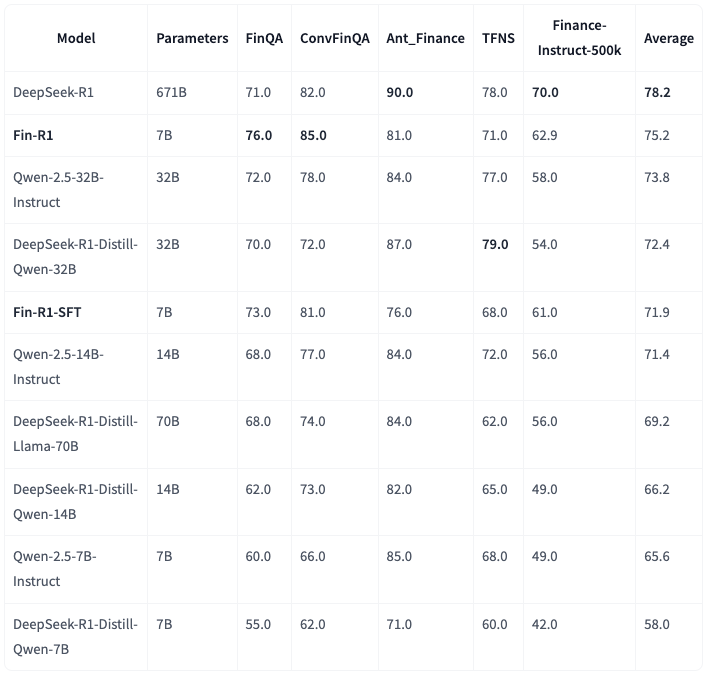 发表了文章
2025-03-28 10:10:06
发表了文章
2025-03-28 10:10:06
 发表了文章
2025-03-28 10:09:47
发表了文章
2025-03-28 10:09:47
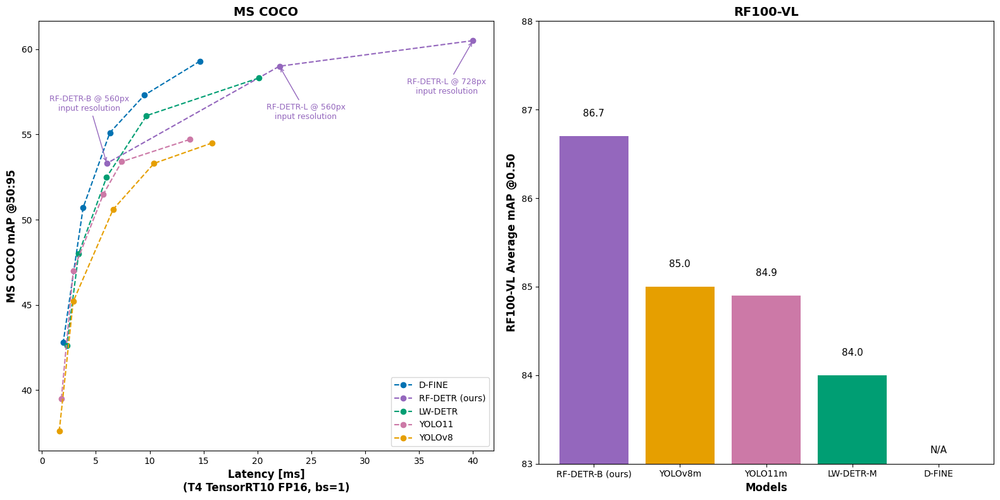 发表了文章
2025-03-28 10:08:53
发表了文章
2025-03-28 10:08:53
 发表了文章
2025-04-30
发表了文章
2025-04-30
发表了文章
2025-04-26
发表了文章
2025-04-26
发表了文章
2025-04-26
发表了文章
2025-04-25
发表了文章
2025-04-24
发表了文章
2025-04-24
发表了文章
2025-04-24
发表了文章
2025-04-24
发表了文章
2025-04-24
发表了文章
2025-04-24
发表了文章
2025-04-24
发表了文章
2025-04-24
发表了文章
2025-04-24
发表了文章
2025-04-22
发表了文章
2025-04-22
发表了文章
2025-04-22
发表了文章
2025-04-20
发表了文章
2025-04-20
发表了文章
2025-04-30
发表了文章
2025-04-30
发表了文章
2025-04-26
发表了文章
2025-04-26
发表了文章
2025-04-26
发表了文章
2025-04-25
发表了文章
2025-04-24
发表了文章
2025-04-24
发表了文章
2025-04-24
发表了文章
2025-04-24
发表了文章
2025-04-24
发表了文章
2025-04-24
发表了文章
2025-04-24
发表了文章
2025-04-24
发表了文章
2025-04-24
发表了文章
2025-04-22
发表了文章
2025-04-22
发表了文章
2025-04-22
发表了文章
2025-04-20
发表了文章
2025-04-20


