






能力说明:
掌握封装、继承和多态设计Java类的方法,能够设计较复杂的Java类结构;能够使用泛型与集合的概念与方法,创建泛型类,使用ArrayList,TreeSet,TreeMap等对象掌握Java I/O原理从控制台读取和写入数据,能够使用BufferedReader,BufferedWriter文件创建输出、输入对象。
暂时未有相关云产品技术能力~
一个大数据开发从业者
2023年02月
 发表了文章
2023-02-26 23:09:10
发表了文章
2023-02-26 23:09:10
 发表了文章
2023-02-26 23:08:17
发表了文章
2023-02-26 23:07:25
发表了文章
2023-02-26 23:08:17
发表了文章
2023-02-26 23:07:25
 发表了文章
2023-02-26 23:06:23
发表了文章
2023-02-26 23:05:30
发表了文章
2023-02-26 23:01:08
发表了文章
2023-02-26 23:00:15
发表了文章
2023-02-26 22:59:30
发表了文章
2023-02-26 22:58:32
发表了文章
2023-02-26 23:06:23
发表了文章
2023-02-26 23:05:30
发表了文章
2023-02-26 23:01:08
发表了文章
2023-02-26 23:00:15
发表了文章
2023-02-26 22:59:30
发表了文章
2023-02-26 22:58:32
 发表了文章
2023-02-26 22:57:07
发表了文章
2023-02-26 22:56:19
发表了文章
2023-02-26 22:57:07
发表了文章
2023-02-26 22:56:19
 发表了文章
2023-02-26 22:54:55
发表了文章
2023-02-26 22:53:44
发表了文章
2023-02-26 22:54:55
发表了文章
2023-02-26 22:53:44
 发表了文章
2023-02-26 22:52:00
发表了文章
2023-02-26 22:52:00
 发表了文章
2023-02-26 22:50:31
发表了文章
2023-02-26 22:48:55
发表了文章
2023-02-26 22:47:56
发表了文章
2023-02-26 22:46:33
发表了文章
2023-02-26 22:45:36
发表了文章
2023-02-26 22:44:46
发表了文章
2023-02-26 22:43:53
发表了文章
2023-02-26 22:35:53
发表了文章
2023-02-26 22:32:33
发表了文章
2023-02-26 22:50:31
发表了文章
2023-02-26 22:48:55
发表了文章
2023-02-26 22:47:56
发表了文章
2023-02-26 22:46:33
发表了文章
2023-02-26 22:45:36
发表了文章
2023-02-26 22:44:46
发表了文章
2023-02-26 22:43:53
发表了文章
2023-02-26 22:35:53
发表了文章
2023-02-26 22:32:33
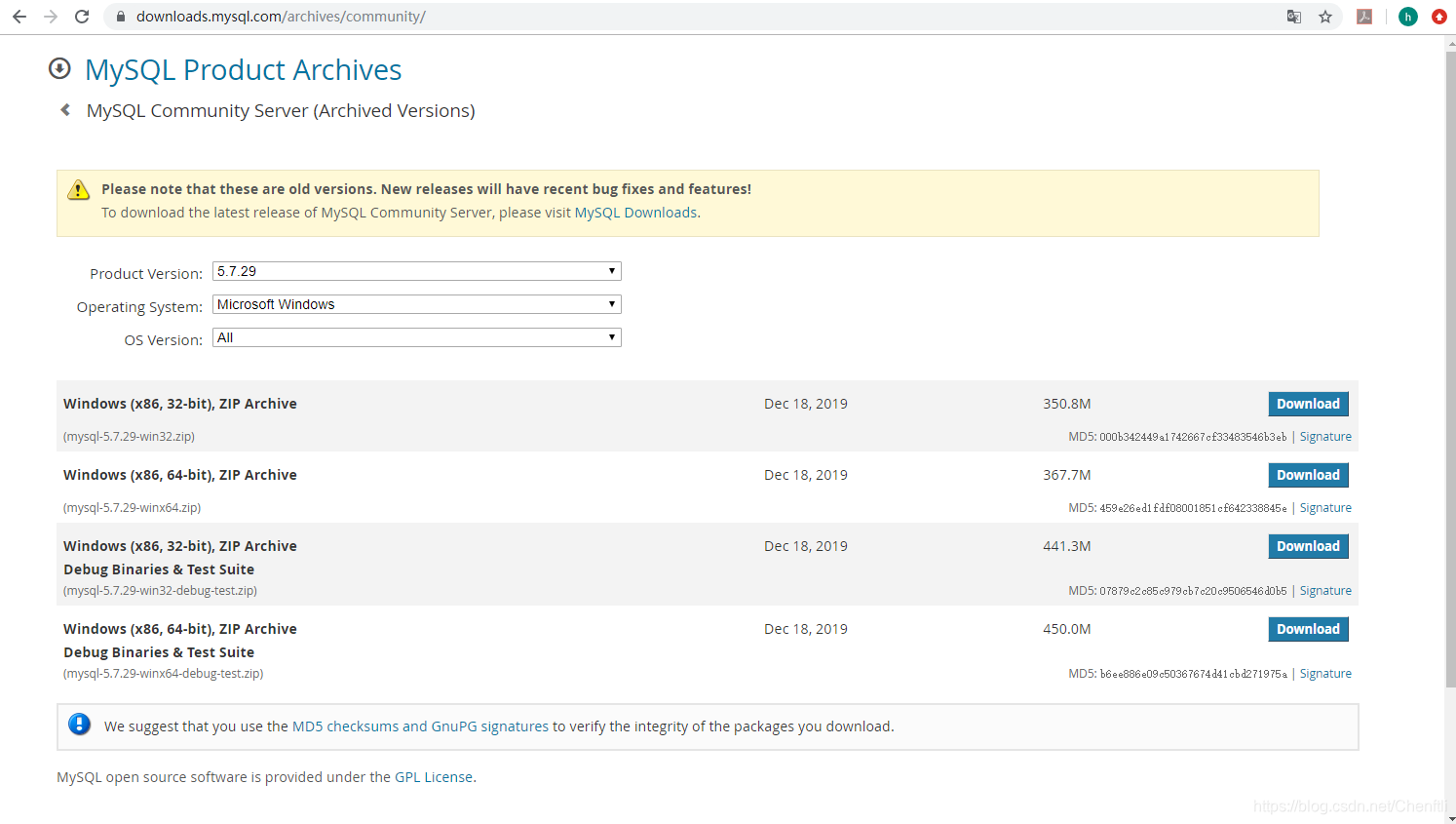 发表了文章
2023-02-26 22:29:57
发表了文章
2023-02-26 22:29:57
 发表了文章
2023-02-26 22:28:49
发表了文章
2023-02-26 22:27:49
发表了文章
2023-02-26 22:28:49
发表了文章
2023-02-26 22:27:49
 发表了文章
2023-02-26 22:26:36
发表了文章
2023-02-26 22:26:36
 发表了文章
2023-02-26 22:24:49
发表了文章
2023-02-26 22:23:36
发表了文章
2023-02-26 22:24:49
发表了文章
2023-02-26 22:23:36
 发表了文章
2023-02-26 22:21:46
发表了文章
2023-02-26 22:21:46
 发表了文章
2023-02-26 22:20:49
发表了文章
2023-02-26 22:20:49
 发表了文章
2023-02-26 22:19:57
发表了文章
2023-02-26 22:19:57
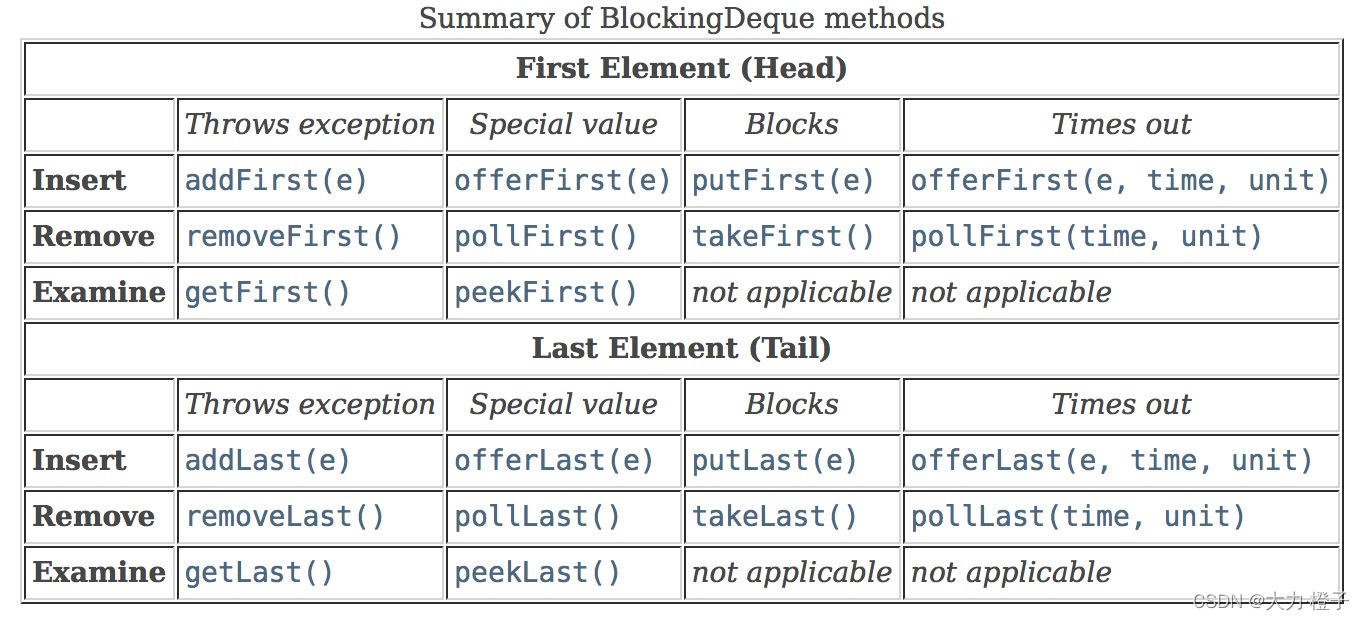 发表了文章
2023-02-26 22:18:45
发表了文章
2023-02-26 22:18:45
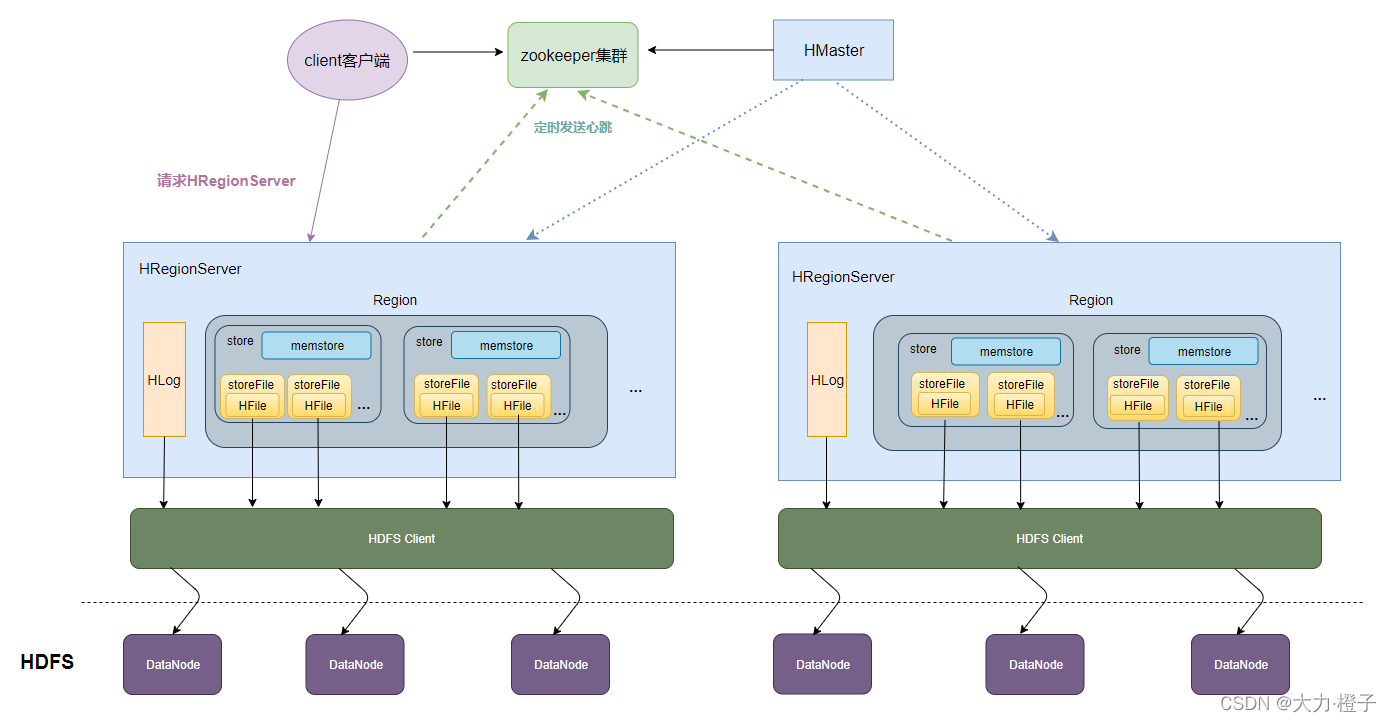 发表了文章
2023-02-26 22:17:55
发表了文章
2023-02-26 22:17:55
 发表了文章
2023-02-26 22:15:37
发表了文章
2023-02-26 22:15:37
 发表了文章
2023-02-26 22:14:21
发表了文章
2023-02-26 22:13:33
发表了文章
2023-02-26 22:14:21
发表了文章
2023-02-26 22:13:33
 发表了文章
2023-02-26 22:12:33
发表了文章
2023-02-26 22:11:35
发表了文章
2023-02-26 22:12:33
发表了文章
2023-02-26 22:11:35
 发表了文章
2023-02-26 22:10:25
发表了文章
2023-02-26 22:10:25
 发表了文章
2023-02-26 22:09:10
发表了文章
2023-02-26 22:09:10
 发表了文章
2023-02-26 22:07:07
发表了文章
2023-02-26 22:07:07
 发表了文章
2023-02-26 22:06:17
发表了文章
2023-02-26 22:05:23
发表了文章
2023-02-26 22:06:17
发表了文章
2023-02-26 22:05:23
 发表了文章
2023-02-26 22:04:34
发表了文章
2023-02-26 22:04:34
 发表了文章
2023-02-26 22:03:02
发表了文章
2023-02-26 22:03:02
 发表了文章
2023-02-26 22:02:10
发表了文章
2023-02-26 22:02:10
 发表了文章
2023-02-26 22:01:05
发表了文章
2023-02-26 22:01:05
 发表了文章
2023-02-26 22:00:12
发表了文章
2023-02-26 22:00:12
 发表了文章
2023-02-26 21:59:05
发表了文章
2023-02-26 21:59:05
 发表了文章
2023-02-26
发表了文章
2023-02-26
发表了文章
2023-02-26
发表了文章
2023-02-26
发表了文章
2023-02-26
发表了文章
2023-02-26
发表了文章
2023-02-26
发表了文章
2023-02-26
发表了文章
2023-02-26
发表了文章
2023-02-26
发表了文章
2023-02-26
发表了文章
2023-02-26
发表了文章
2023-02-26
发表了文章
2023-02-26
发表了文章
2023-02-26
发表了文章
2023-02-26
发表了文章
2023-02-26
发表了文章
2023-02-26
发表了文章
2023-02-26
发表了文章
2023-02-26
发表了文章
2023-02-26
发表了文章
2023-02-26
发表了文章
2023-02-26
发表了文章
2023-02-26
发表了文章
2023-02-26
发表了文章
2023-02-26
发表了文章
2023-02-26
发表了文章
2023-02-26
发表了文章
2023-02-26
发表了文章
2023-02-26
发表了文章
2023-02-26
发表了文章
2023-02-26
发表了文章
2023-02-26
发表了文章
2023-02-26
发表了文章
2023-02-26
发表了文章
2023-02-26
发表了文章
2023-02-26
发表了文章
2023-02-26
发表了文章
2023-02-26
发表了文章
2023-02-26








