





暂时未有相关云产品技术能力~
暂无个人介绍
2023年10月
 发表了文章
2023-10-25 20:50:56
发表了文章
2023-10-25 20:50:56
2022年11月
发表了文章
2022-11-22 12:53:37
 发表了文章
2022-11-22 12:52:53
发表了文章
2022-11-22 12:52:53
 发表了文章
2022-11-22 12:52:03
发表了文章
2022-11-22 12:52:03
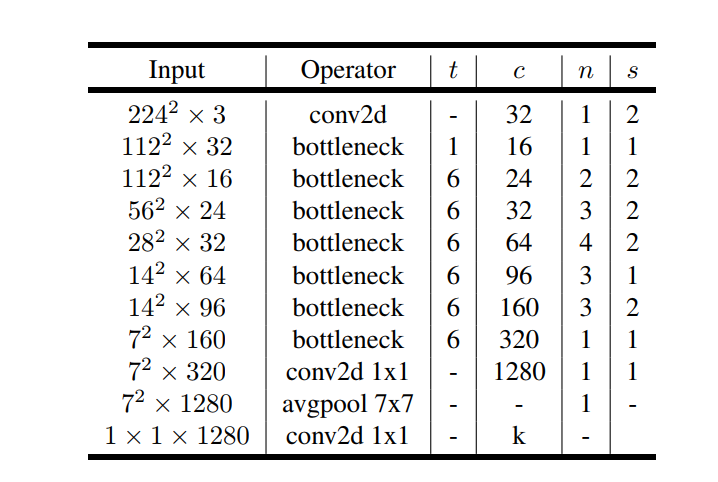 发表了文章
2022-11-18 07:02:33
发表了文章
2022-11-18 07:02:33
 发表了文章
2022-11-18 06:56:54
发表了文章
2022-11-18 06:56:54
 发表了文章
2022-11-18 06:55:40
发表了文章
2022-11-18 06:55:40
2022年04月
发表了文章
2022-04-07 09:21:34
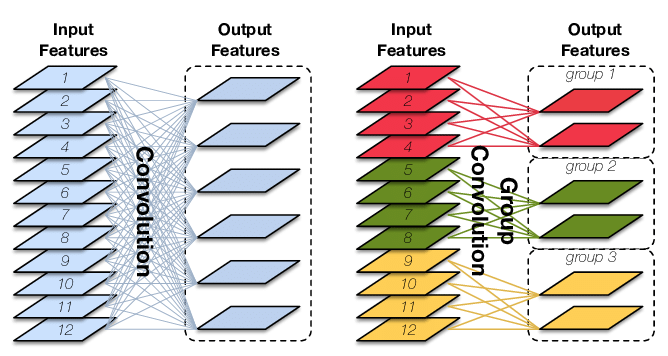 发表了文章
2022-04-07 09:20:56
发表了文章
2022-04-07 09:20:56
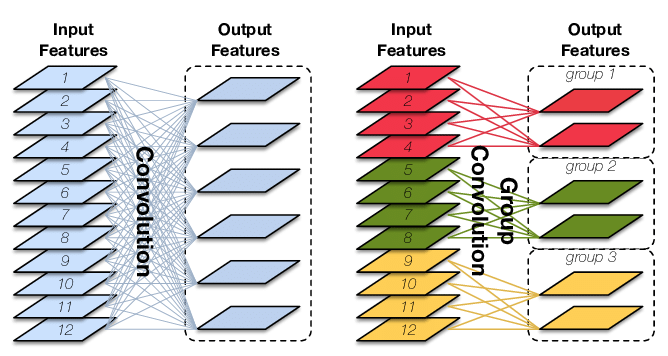 发表了文章
2022-04-07 09:20:11
发表了文章
2022-04-07 09:20:11
2022年01月
发表了文章
2022-01-26 10:08:50
发表了文章
2022-01-26 10:07:36
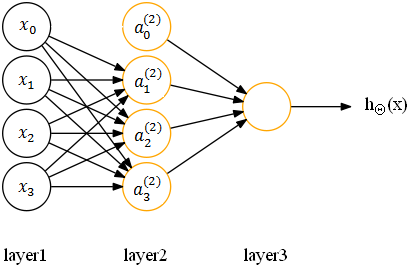 发表了文章
2022-01-25 22:15:54
发表了文章
2022-01-23 10:16:42
发表了文章
2022-01-25 22:15:54
发表了文章
2022-01-23 10:16:42
 发表了文章
2022-01-23 10:15:46
发表了文章
2022-01-23 10:15:46
 发表了文章
2022-01-23 10:14:32
发表了文章
2022-01-21 12:34:06
发表了文章
2022-01-20 18:57:53
发表了文章
2022-01-23 10:14:32
发表了文章
2022-01-21 12:34:06
发表了文章
2022-01-20 18:57:53
 发表了文章
2022-01-20 17:29:50
发表了文章
2022-01-20 17:29:50
 发表了文章
2022-01-19 09:16:09
发表了文章
2022-01-19 09:16:09
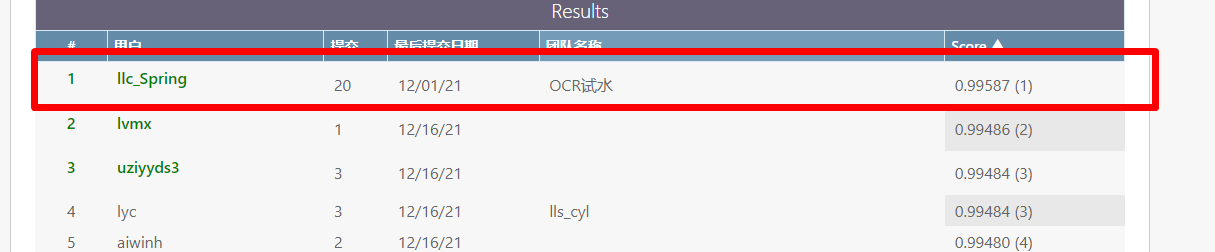 发表了文章
2022-01-18 12:35:54
发表了文章
2022-01-18 12:35:54
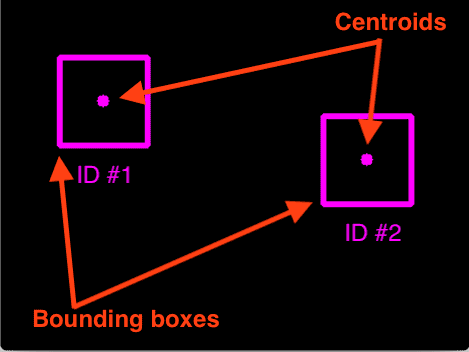 发表了文章
2022-01-17 09:17:15
发表了文章
2022-01-17 09:17:15
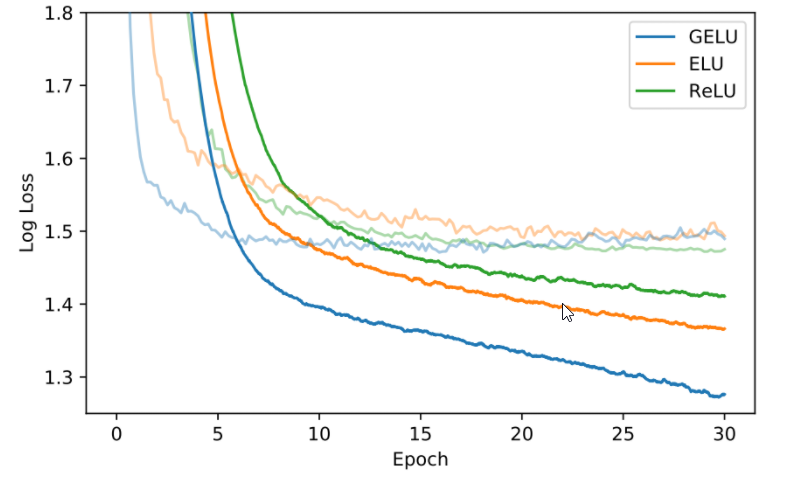 发表了文章
2022-01-15 05:40:31
发表了文章
2022-01-15 05:39:55
发表了文章
2022-01-15 05:40:31
发表了文章
2022-01-15 05:39:55
 发表了文章
2022-01-15 05:38:47
发表了文章
2022-01-15 05:38:47
 发表了文章
2022-01-14 10:26:34
发表了文章
2022-01-14 10:26:34
 发表了文章
2022-01-14 10:22:08
发表了文章
2022-01-14 10:22:08
 发表了文章
2022-01-11 06:29:39
发表了文章
2022-01-11 06:28:58
发表了文章
2022-01-11 06:28:12
发表了文章
2022-01-11 06:29:39
发表了文章
2022-01-11 06:28:58
发表了文章
2022-01-11 06:28:12
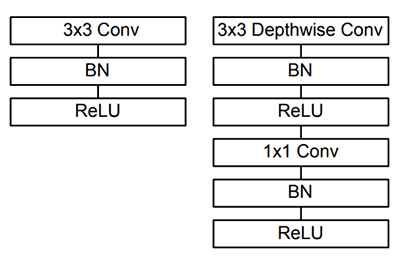 发表了文章
2022-01-10 06:58:52
发表了文章
2022-01-10 06:58:52
 发表了文章
2022-01-10 06:58:05
发表了文章
2022-01-10 06:58:05
 发表了文章
2022-01-10 06:57:23
发表了文章
2022-01-10 06:57:23
 发表了文章
2022-01-08 11:12:03
发表了文章
2022-01-08 11:12:03
 发表了文章
2022-01-08 11:11:09
发表了文章
2022-01-08 11:11:09
 发表了文章
2022-01-08 11:09:57
发表了文章
2022-01-06 07:00:34
发表了文章
2022-01-08 11:09:57
发表了文章
2022-01-06 07:00:34
 发表了文章
2022-01-06 06:59:34
发表了文章
2022-01-06 06:59:34
 发表了文章
2022-01-06 06:58:33
发表了文章
2022-01-06 06:58:33
 发表了文章
2022-01-04 06:51:53
发表了文章
2022-01-04 06:51:53
 发表了文章
2022-01-04 06:50:54
发表了文章
2022-01-04 06:50:54

2021年12月
发表了文章
2021-12-30 17:49:37
 发表了文章
2021-12-30 17:48:49
发表了文章
2021-12-30 17:48:49
 发表了文章
2021-12-30 17:47:50
发表了文章
2021-12-30 17:47:50
 发表了文章
2021-12-30 17:46:45
发表了文章
2021-12-30 17:45:59
发表了文章
2021-12-30 17:46:45
发表了文章
2021-12-30 17:45:59
 发表了文章
2021-12-30 17:44:39
发表了文章
2021-12-30 17:44:39
 发表了文章
2021-12-07 09:41:52
发表了文章
2021-12-07 09:41:52
 发表了文章
2021-12-07 09:40:54
发表了文章
2021-12-07 09:40:54

2021年11月
发表了文章
2021-11-30 16:05:22
 发表了文章
2023-10-25
发表了文章
2022-11-22
发表了文章
2022-11-22
发表了文章
2022-11-22
发表了文章
2022-11-18
发表了文章
2022-11-18
发表了文章
2022-11-18
发表了文章
2022-04-07
发表了文章
2022-04-07
发表了文章
2022-04-07
发表了文章
2022-01-26
发表了文章
2022-01-26
发表了文章
2022-01-25
发表了文章
2022-01-23
发表了文章
2022-01-23
发表了文章
2022-01-23
发表了文章
2022-01-21
发表了文章
2022-01-20
发表了文章
2022-01-20
发表了文章
2022-01-19
发表了文章
2023-10-25
发表了文章
2022-11-22
发表了文章
2022-11-22
发表了文章
2022-11-22
发表了文章
2022-11-18
发表了文章
2022-11-18
发表了文章
2022-11-18
发表了文章
2022-04-07
发表了文章
2022-04-07
发表了文章
2022-04-07
发表了文章
2022-01-26
发表了文章
2022-01-26
发表了文章
2022-01-25
发表了文章
2022-01-23
发表了文章
2022-01-23
发表了文章
2022-01-23
发表了文章
2022-01-21
发表了文章
2022-01-20
发表了文章
2022-01-20
发表了文章
2022-01-19






