能力说明:
了解Python语言的基本特性、编程环境的搭建、语法基础、算法基础等,了解Python的基本数据结构,对Python的网络编程与Web开发技术具备初步的知识,了解常用开发框架的基本特性,以及Python爬虫的基础知识。
能力说明:
基本的计算机知识与操作能力,具备Web基础知识,掌握Web的常见标准、常用浏览器的不同特性,掌握HTML与CSS的入门知识,可进行静态网页的制作与发布。
暂时未有相关云产品技术能力~
web开发、脚本开发、可视化研究
在不使用构建工具的情况下,快速搭建Vue2+ElementUI应用:直接在HTML中引入Vue和Element UI的CDN,创建Vue实例,绑定数据和组件。示例展示了如何使用Element UI的按钮和复选框组创建权限设置界面。通过Vue的响应式系统和组件化实现数据绑定和界面更新。完整代码包括设置权限按钮和三个复选框组,预设了城市权限选项。
这段内容是一个关于使用Python的Tkinter库来展示官方内置颜色的代码示例。代码通过循环遍历一个包含颜色名称和十六进制颜色代码的字符串,然后创建Label组件并将背景色设置为对应的颜色。效果是生成一个网格布局的窗口,每个单元格显示一种颜色及其名称。此外,还提到了如何自定义颜色,通过RGB值转换成十六进制来设定背景色。提供的图片展示了颜色展示窗口的实际效果。
使用Python的uiautomator2库进行多设备自动化测试,涉及环境准备(Python、uiautomator2、adb连接设备)和代码实现。通过`adb devices`获取设备列表,使用多进程并行执行测试脚本,每个脚本通过uiautomator2连接设备并获取屏幕尺寸。注意设备需开启USB调试并授权adb。利用多进程而非多线程,因Python的GIL限制。文章提供了一种提高测试效率的方法,适用于大规模设备测试场景。
使用`ttkbootstrap`构建的GUI学生信息管理系统,展示学生数据的`Treeview`,支持添加、编辑和删除记录。核心功能包括: - `Treeview`展示学生信息。 - 表单窗口添加和编辑信息,利用`open_form_window`处理交互。 - 选择项后,`edit_data`和`delete_data`分别用于编辑和删除。 - 需要Python 3.8+和ttkbootstrap 1.10.1。 - 源码展示了数据结构、事件处理和窗口布局。 要运行,安装依赖并执行代码,测试各项功能以确保正常工作。
`venv`是Python的内置模块,用于创建隔离的虚拟环境。创建虚拟环境如`python3 -m venv myenv`,激活环境在Windows上是`./venv/Scripts/activate`,在Unix-like系统是`source myenv/bin/activate`。退出环境用`deactivate`。`pip list`查看已安装包,`pip install`安装包,`pip freeze > requirements.txt`保存依赖。PyCharm中红色`venv`表示项目使用了虚拟环境。
当使用pip命令安装Python包时,有时候可以通过使用镜像地址来加速下载速度或解决访问限制的问题。以下是一些常用的pip命令和常见的镜像地址:
了解SQLAlchemy中`filter_by`与`filter`对提升Web应用搜索功能至关重要。`filter_by`简化了等值查询,而`filter`则支持复杂的表达式和逻辑组合。通过动态获取用户输入,构建基础查询并根据条件应用过滤,可以创建灵活的搜索系统。结合分页和排序,为用户提供定制化搜索体验。掌握这两者,能增强应用的交互性和实用性。
使用ECharts展示山东会员活跃度,通过散点图和地图结合,颜色对比强烈,背景深蓝(#020933)、点色明亮黄(#F4E925)。核心代码示例展示了散点、地图及特效散点系列配置。[点击下载](https://download.csdn.net/download/No_Name_Cao_Ni_Mei/89493130)代码和数据。
使用ECharts实现杭州困难人数分布地图,结合地区与散点图,动态展示数据变化。支持进入下级区域并返回。预览包含动画效果。关键代码涉及地图初始化、数据加载及事件处理。需`hangzhou-map.json`数据文件。完整代码和资源见链接。
使用CSS创建的圣诞老人动画,通过`@keyframes`实现身体摇摆。关键代码包括定义动画`rock`,以及设置帽子、脸部、眼睛和胡须的样式。完整代码可下载,此效果为网页增添节日气氛,提升用户体验。[点此获取代码](https://download.csdn.net/download/No_Name_Cao_Ni_Mei/89489001)
构建一个动态旋转的ECharts饼图,包括渐变色和动画效果。初始化ECharts实例,设置图表尺寸和背景,配置标题、颜色、系列数据及自定义渲染。利用`renderItem`绘制弧线和圆点,`getCirlPoint`计算坐标。通过`setInterval`和`draw`函数实现旋转动画。完整代码可在链接下载。
**使用ECharts和电影《千与千寻》短评创建的词云案例展示了数据可视化的力量。通过Python处理评论,提取关键词并计算频率,利用jieba和WordCloud生成词云,ECharts进一步增强了视觉效果。词云突出了角色如“千寻”、“无脸男”及关键词“勇气”、“成长”,揭示了观众的情感共鸣。示例代码和资源可在链接中获取。**
在PyCharm中,项目依赖配置更改后未生效。解决步骤包括:1) 查找`C:\Users\username\AppData\Roaming\JetBrains\PyCharm2022.2\options\jdk.table.xml`,2) 删除`<jdk></jdk>`标签内的旧配置内容,然后重启PyCharm以应用新目录。
本文旨在实现豆瓣电影TOP250的可视化,通过确定柱状图、折线图和饼图等图表设计,展示评价人数最多、年份分布及类型占比。模拟数据用于演示,例如评价最多的电影、年份最多的电影数量及每年高分电影趋势。完整代码可下载,包含ECharts实现的四种图表。
软件系统中的标签功能可采用两种数据库设计。方案一,文章和Tag各一表,Tag信息存储在文章表内(`tags`和`tagids`字段),优点是模型简单,但查询效率低且易引发数据冗余和一致性问题。方案二,增加Tagmap表,用于存储标签-文章映射,利于索引查询和数据更新,适用于高效率需求,但结构更复杂。
构建一个动态饼图,采用ECharts,背景为蓝色科技风,有星球转动效果。通过`echarts.init`初始化,设置图表尺寸和背景色,配置`option`对象含标题、颜色等。利用`series`定义渐变色并自定义渲染,通过`renderItem`绘制弧线和圆点。`getCirlPoint`函数计算坐标,`draw`函数更新角度实现动画。代码包括图表初始化、系列配置、动画逻辑等关键部分。完整代码可在链接处下载。
这是一个Python爬虫程序,用于抓取豆瓣电影详情页面如`https://movie.douban.com/subject/1291560/`的数据。它首先发送GET请求,使用PyQuery解析DOM,然后根据`<br>`标签分割HTML内容,提取电影信息如导演、演员、类型等,并将中文键转换为英文键存储在字典中。完整代码包括请求、解析、数据处理和测试部分。当运行时,会打印出电影详情,如导演、演员列表、类型、时长等。
词云是文本数据可视化的工具,显示单词频率,直观、美观,适用于快速展示文本关键信息。 - 用途包括关键词展示、数据探索、报告演示、情感分析和教育。 - 使用`wordcloud`和`matplotlib`库生成词云,`wordcloud`负责生成,`matplotlib`负责显示。 - 示例代码展示了从简单词云到基于蒙版、颜色和关键词权重的复杂词云生成。 - 案例覆盖了中文分词(使用`jieba`库)、自定义颜色和关键词权重的词云。 - 代码示例包括读取文本、分词、设置词云参数、显示和保存图像。
这是一个关于如何用Python爬取2024年豆瓣电影Top250的详细教程。教程涵盖了生成分页URL列表和解析页面以获取电影信息的函数。`getAllPageUrl()` 生成前10页的链接,而`getMoiveListByUrl()` 使用PyQuery解析HTML,提取电影标题、封面、评价数和评分。代码示例展示了测试这些函数的方法,输出包括电影详情的字典列表。
使用ECharts进行一周跑步数据分析,通过雷达图展示多维度指标(如距离、速度、时间),颜色对比体现个人与平均表现。折线图则清晰显示每日里程趋势,代码示例展示了自定义的`radar`和`line`图表配置。图表交互性强,支持点击高亮,动画流畅,提供完整代码资源。#ECharts #跑步数据 #数据可视化
**ECharts 案例展示了诈骗性质的雷达图分析,以创新可视化揭示诈骗模式。定制化雷达图配色鲜明,多维度剖析不同诈骗手段,如网络刷单、冒充公检法。交互式设计允许用户深入探究细节。[点击这里](https://download.csdn.net/download/No_Name_Cao_Ni_Mei/89454384)查看完整案例。#ECharts #数据可视化 #雷达图 #诈骗分析**
使用ECharts展示近七天跑步数据,结合雷达图和折线图揭示运动表现。雷达图多维度呈现全程距离、速度和时间,对比平均指标;折线图清晰展示里程趋势。图表具有交互性和动画效果,通过[代码地址](https://download.csdn.net/download/No_Name_Cao_Ni_Mei/89454698)可获取详情。#ECharts #跑步数据 #数据可视化 #雷达图 #折线图
使用ECharts创建自定义雷达图,通过JavaScript动态更新高亮和交互反馈,增强用户体验。关键步骤包括:开启动画效果,数据更新时保持图表状态,鼠标悬浮时动态高亮指标,优化动画性能。案例展示了ECharts在数据可视化中的灵活性和表现力。[查看完整案例](https://download.csdn.net/download/No_Name_Cao_Ni_Mei/89454380)。
使用ECharts创建词云图,结合蒙版技术提升可视化创意。通过设置`maskImage`属性,将自定义图像作为词云的外形,如用户画像。案例中详细介绍了HTML结构、ECharts配置及蒙版图像加载过程,鼓励探索SVG路径和CSS样式以实现更多个性化效果。代码和依赖可下载,激发更多数据可视化灵感。
探索ECharts词云图进阶,使用蒙版创造个性化2024年阅读关键词云。预览图展示渐变色背景与随机色词汇。蒙版概念引入,通过HTML结构和JavaScript配置实现词云与图像蒙版结合。代码及依赖下载链接提供,展示五种创意蒙版效果,激发数据可视化的创新思维。
ECharts 案例展示了一周内各路线数据的蓝色荧光折线图,揭示流量趋势。预览包括静态图片和动态GIF。使用ECharts 5.2.0配置图表,包含背景、网格、图例及数据。代码示例初始化图表、定义X轴类别和Y轴值,以及系列颜色。完整案例可在链接中下载。案例结合动态效果与个性化设计,增强数据可视化的吸引力。
这段文本是关于如何使用Python基于词频生成词云图的教程。内容包括:1) 中文分词的必要性,因中文无明显单词边界及语言单位特性;2) 文本预处理步骤,如移除特殊符号、网址、日期等;3) 使用`data_process`函数清除无用字符;4) `getText`函数读取并处理文本为句子数组;5) 使用jieba分词库进行分词和词频统计;6) 示例代码展示了从分词到生成词云的完整流程,最后展示生成的词云图。整个过程旨在从中文文本中提取关键词并可视化。
ECharts,百度的JavaScript图表库,支持词云图(自5.0版起),借助`echarts-wordcloud`插件。配置词云图涉及`tooltip`(如显示、颜色、边框等)和`series`(类型、形状、大小范围等)。示例代码展示了如何在HTML中引入依赖并配置词云图,包括数据、形状、大小、颜色等。完整代码和依赖可下载。调整这些配置可创建个性化词云图。参阅官方文档获取不同版本详情。
在Flask中实现模板继承,创建基础模板`base.html`,包含公共导航菜单。子模板`movie-extends.html`继承`base.html`,并定义主要内容。视图函数`movie_extends_view`渲染`movie-extends.html`,显示电影列表。通过`extra_css`和`extra_js`块添加页面特定的样式和脚本,实现在`movie-extends.html`中应用自定义CSS样式。运行应用,访问http://127.0.0.1:1027/movie-extends,页面显示定制的电影列表样式。
使用Python和`requests`、`PyQuery`库,本文教程教你如何编写一个豆瓣电影列表页面的爬虫,抓取电影标题、导演、主演等信息。首先确保安装所需库,然后了解技术栈,包括Python、Requests、PyQuery和正则表达式。爬虫逻辑包括发送HTTP请求、解析HTML、提取数据。代码示例展示了如何实现这一过程,最后运行爬虫并将结果保存为JSON文件。注意遵守网站使用条款和应对反爬策略。
构建高效爬虫系统涉及关键模块如爬虫引擎、链接存储、内容处理器等,以及用户代理池、IP代理池等反反爬策略。评估项目复杂性考虑数据规模、网站结构、反爬虫机制等因素。案例分析展示了电子商务价格比较爬虫的设计,强调了系统模块化、错误处理和合规性的重要性。爬虫技术需要不断进化以应对复杂网络环境的挑战。
对比了Python的几个HTTP请求库,包括`requests`、`http.client`、`aiohttp`、`urllib`、`httpx`、`treq`和`requests-toolbelt`,各有特点和优缺点。选择时应考虑项目需求(如异步支持)、易用性、社区支持、性能和兼容性。示例展示了如何使用`requests`和`aiohttp`库发送豆瓣电影排行榜的GET请求。
使用 Flask 搭建的 RESTful API Demo,包含增、改用户信息和分页查询功能。利用 Flask-SQLAlchemy 处理数据库操作。环境准备:安装 Flask 和 Flask-SQLAlchemy。核心代码展示用户模型、增加用户、分页查询和更新用户信息的路由。注意点包括数据库配置、错误处理、JSON 数据处理、幂等性、安全性和编码问题。提供完整源码下载链接。
该文介绍了如何使用 Flask、SQLAlchemy 和 SQLite 实现数据库操作。首先,通过创建虚拟环境和安装 flask-sqlalchemy(版本2.5.1)及 sqlalchemy(版本1.4.47)来设置环境。接着,配置数据库URI,定义User和Movie模型类表示数据库表,并通过db.create_all()创建表。文章还展示了如何插入、查询、更新和删除记录,强调了db.session.commit()在保存更改中的关键作用。查询涉及filter、order_by等方法,提供了一系列示例。
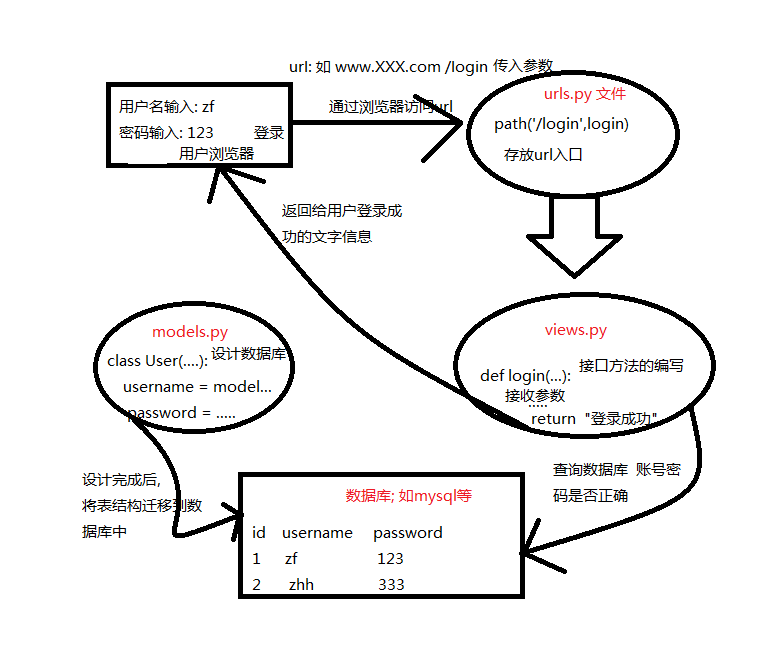
# Flask Web开发基础 Flask是轻量级Web框架,专注于核心功能:请求响应、模板渲染和URL路由。本文档介绍了使用Flask的基础知识,包括命令行和Python两种运行模式,以及如何修改入口文件、端口和地址。此外,还讨论了URL路由的概念和其在Flask中的实现,展示了动态路由和多URL绑定的例子。最后,提到了Jinja2模板引擎,解释了其基本语法,并通过电影列表案例展示了如何结合Flask使用模板。
 发表了文章
2024-07-11
发表了文章
2024-07-10
发表了文章
2024-07-10
发表了文章
2024-07-09
发表了文章
2024-07-08
发表了文章
2024-07-08
发表了文章
2024-07-02
发表了文章
2024-06-28
发表了文章
2024-06-28
发表了文章
2024-06-27
发表了文章
2024-06-27
发表了文章
2024-06-25
发表了文章
2024-06-24
发表了文章
2024-06-24
发表了文章
2024-06-21
发表了文章
2024-06-21
发表了文章
2024-06-21
发表了文章
2024-06-20
发表了文章
2024-06-20
发表了文章
2024-06-20
发表了文章
2024-07-11
发表了文章
2024-07-10
发表了文章
2024-07-10
发表了文章
2024-07-09
发表了文章
2024-07-08
发表了文章
2024-07-08
发表了文章
2024-07-02
发表了文章
2024-06-28
发表了文章
2024-06-28
发表了文章
2024-06-27
发表了文章
2024-06-27
发表了文章
2024-06-25
发表了文章
2024-06-24
发表了文章
2024-06-24
发表了文章
2024-06-21
发表了文章
2024-06-21
发表了文章
2024-06-21
发表了文章
2024-06-20
发表了文章
2024-06-20
发表了文章
2024-06-20