
暂无个人介绍

暂时未有相关通用技术能力~
阿里云技能认证
详细说明

2024年05月
 发表了文章
2024-04-22 16:57:10
发表了文章
2024-04-22 16:57:10
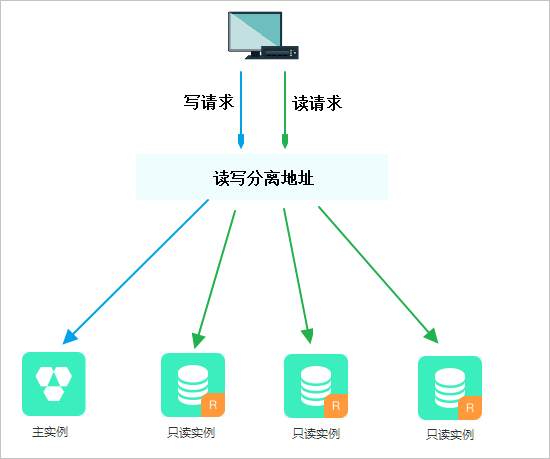 发表了文章
2024-04-22 16:52:19
发表了文章
2024-04-22 16:52:19
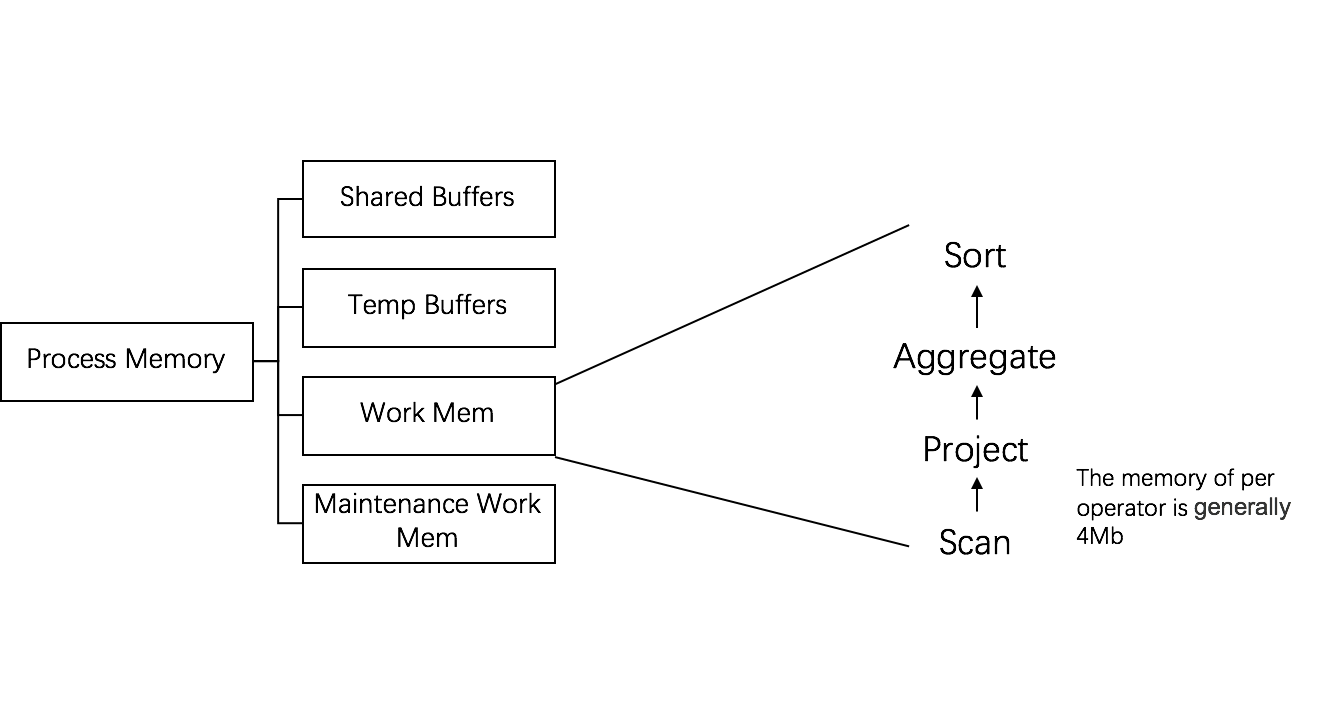 发表了文章
2024-05-15
发表了文章
2024-05-15
发表了文章
2017-06-05
发表了文章
2016-05-25
发表了文章
2024-05-15
发表了文章
2024-05-15
发表了文章
2017-06-05
发表了文章
2016-05-25

 提交了问题
2016-07-07
提交了问题
2016-07-07
提交了问题
2016-07-03
提交了问题
2016-07-01
提交了问题
2016-06-30
提交了问题
2016-06-28
提交了问题
2016-06-27
提交了问题
2016-06-27
提交了问题
2016-06-24
提交了问题
2016-07-07
提交了问题
2016-07-07
提交了问题
2016-07-03
提交了问题
2016-07-01
提交了问题
2016-06-30
提交了问题
2016-06-28
提交了问题
2016-06-27
提交了问题
2016-06-27
提交了问题
2016-06-24
 回答了问题
2016-06-24
回答了问题
2016-06-22
回答了问题
2016-06-12
回答了问题
2016-06-11
回答了问题
2016-06-07
提交了问题
2016-06-06
回答了问题
2016-06-06
回答了问题
2016-06-06
回答了问题
2016-06-06
回答了问题
2016-06-06
回答了问题
2016-06-06
回答了问题
2016-06-24
回答了问题
2016-06-22
回答了问题
2016-06-12
回答了问题
2016-06-11
回答了问题
2016-06-07
提交了问题
2016-06-06
回答了问题
2016-06-06
回答了问题
2016-06-06
回答了问题
2016-06-06
回答了问题
2016-06-06
回答了问题
2016-06-06
