





暂时未有相关云产品技术能力~
博士在读: 山东大学 (985), 本硕: (双一流)(211)高校,第一作者发表中科院SCI一区Top多篇,EI国际会议多篇,总计影响因子60+。
2024年09月
 发表了文章
2024-09-10 19:19:40
发表了文章
2024-09-10 19:17:50
发表了文章
2024-09-10 19:14:50
发表了文章
2024-09-10 19:13:45
发表了文章
2024-09-10 19:07:48
发表了文章
2024-09-10 19:06:01
发表了文章
2024-09-10 19:05:21
发表了文章
2024-09-10 19:04:24
发表了文章
2024-09-10 19:03:44
发表了文章
2024-09-10 19:02:48
发表了文章
2024-09-10 19:01:56
发表了文章
2024-09-10 19:01:21
发表了文章
2024-09-10 18:59:51
发表了文章
2024-09-10 18:57:56
发表了文章
2024-09-09 15:39:20
发表了文章
2024-09-09 15:38:37
发表了文章
2024-09-09 15:35:11
发表了文章
2024-09-09 15:33:43
发表了文章
2024-09-09 15:32:03
发表了文章
2024-09-09 15:22:25
发表了文章
2024-09-09 15:21:13
发表了文章
2024-09-09 15:20:20
发表了文章
2024-09-09 15:19:23
发表了文章
2024-09-09 15:18:05
发表了文章
2024-09-09 15:14:34
发表了文章
2024-09-09 15:13:17
发表了文章
2024-09-09 15:12:08
发表了文章
2024-09-09 15:10:27
发表了文章
2024-09-09 15:09:02
发表了文章
2024-09-09 15:07:30
发表了文章
2024-09-10 19:19:40
发表了文章
2024-09-10 19:17:50
发表了文章
2024-09-10 19:14:50
发表了文章
2024-09-10 19:13:45
发表了文章
2024-09-10 19:07:48
发表了文章
2024-09-10 19:06:01
发表了文章
2024-09-10 19:05:21
发表了文章
2024-09-10 19:04:24
发表了文章
2024-09-10 19:03:44
发表了文章
2024-09-10 19:02:48
发表了文章
2024-09-10 19:01:56
发表了文章
2024-09-10 19:01:21
发表了文章
2024-09-10 18:59:51
发表了文章
2024-09-10 18:57:56
发表了文章
2024-09-09 15:39:20
发表了文章
2024-09-09 15:38:37
发表了文章
2024-09-09 15:35:11
发表了文章
2024-09-09 15:33:43
发表了文章
2024-09-09 15:32:03
发表了文章
2024-09-09 15:22:25
发表了文章
2024-09-09 15:21:13
发表了文章
2024-09-09 15:20:20
发表了文章
2024-09-09 15:19:23
发表了文章
2024-09-09 15:18:05
发表了文章
2024-09-09 15:14:34
发表了文章
2024-09-09 15:13:17
发表了文章
2024-09-09 15:12:08
发表了文章
2024-09-09 15:10:27
发表了文章
2024-09-09 15:09:02
发表了文章
2024-09-09 15:07:30
 发表了文章
2024-09-09 15:05:33
发表了文章
2024-09-09 15:05:33
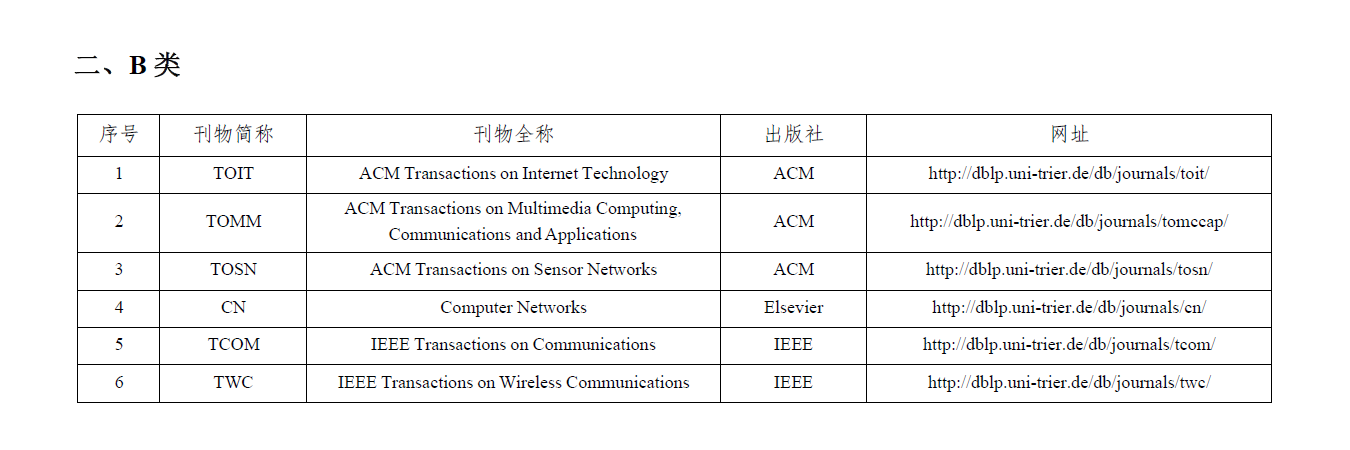 发表了文章
2024-09-09 15:03:40
发表了文章
2024-09-09 15:03:40
 发表了文章
2024-09-09 14:56:59
发表了文章
2024-09-09 14:56:59
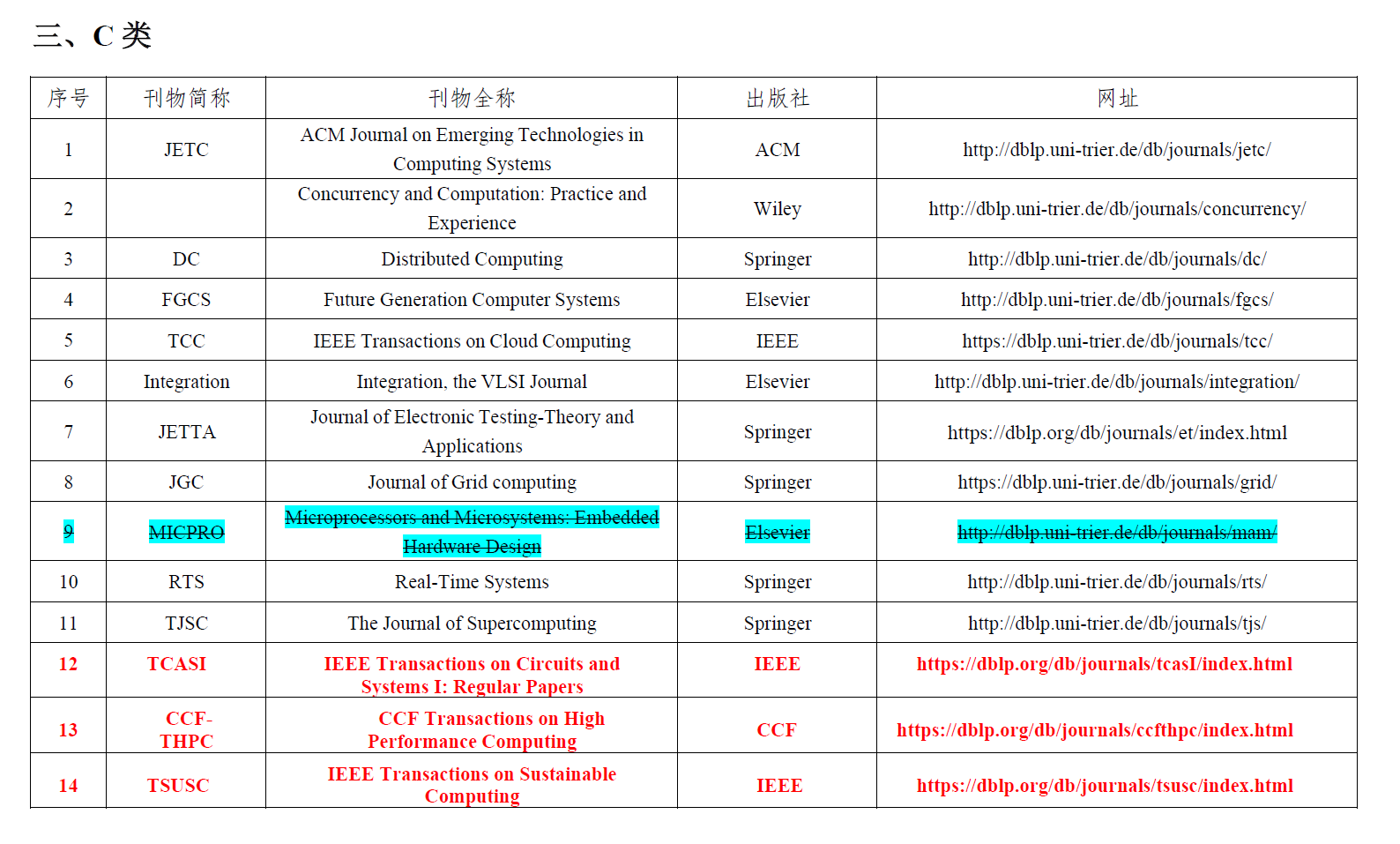 发表了文章
2024-09-09 10:45:13
发表了文章
2024-09-09 10:45:13
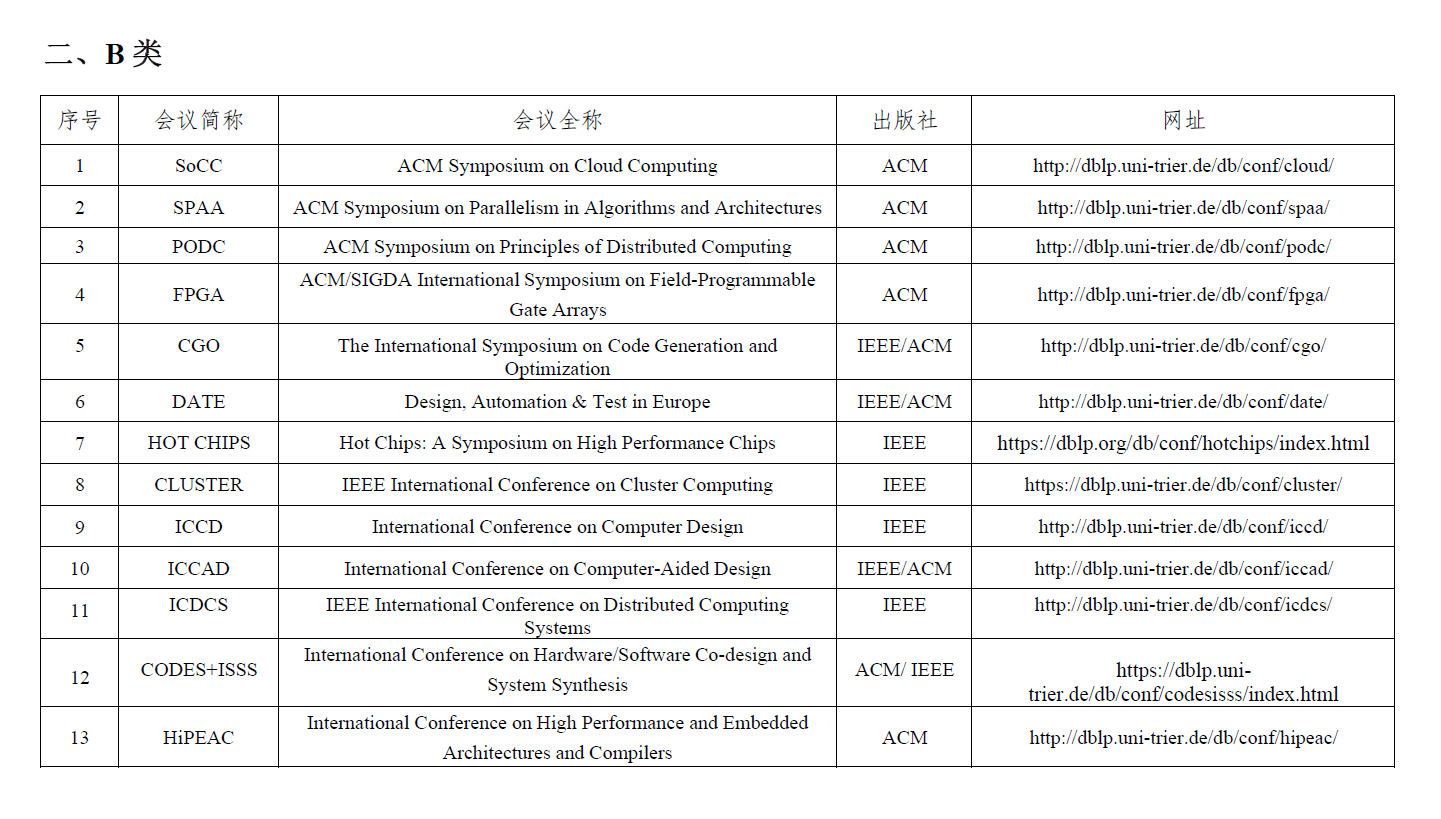 发表了文章
2024-09-09 09:24:27
发表了文章
2024-09-09 09:24:27

2024年05月
发表了文章
2024-04-30 10:44:22
发表了文章
2024-04-30 10:42:19
发表了文章
2024-04-30 10:40:17
发表了文章
2024-04-27 22:37:33
发表了文章
2024-04-27 22:16:14
发表了文章
2024-04-27 20:30:55
发表了文章
2024-04-27 20:18:58
发表了文章
2024-04-27 20:11:36
发表了文章
2024-04-26 22:02:29
发表了文章
2024-04-26 22:00:08
2024年04月
 回答了问题
2024-04-27 21:50:14
回答了问题
2024-04-27 21:46:50
回答了问题
2024-04-27 21:41:55
回答了问题
2024-04-27 21:34:36
回答了问题
2024-04-27 20:40:14
发表了文章
2024-09-10
发表了文章
2024-09-10
发表了文章
2024-09-10
发表了文章
2024-09-10
发表了文章
2024-09-10
发表了文章
2024-09-10
发表了文章
2024-09-10
发表了文章
2024-09-10
发表了文章
2024-09-10
发表了文章
2024-09-10
发表了文章
2024-09-10
发表了文章
2024-09-10
发表了文章
2024-09-10
发表了文章
2024-09-10
发表了文章
2024-09-09
发表了文章
2024-09-09
发表了文章
2024-09-09
发表了文章
2024-09-09
发表了文章
2024-09-09
发表了文章
2024-09-09
回答了问题
2024-04-27 21:50:14
回答了问题
2024-04-27 21:46:50
回答了问题
2024-04-27 21:41:55
回答了问题
2024-04-27 21:34:36
回答了问题
2024-04-27 20:40:14
发表了文章
2024-09-10
发表了文章
2024-09-10
发表了文章
2024-09-10
发表了文章
2024-09-10
发表了文章
2024-09-10
发表了文章
2024-09-10
发表了文章
2024-09-10
发表了文章
2024-09-10
发表了文章
2024-09-10
发表了文章
2024-09-10
发表了文章
2024-09-10
发表了文章
2024-09-10
发表了文章
2024-09-10
发表了文章
2024-09-10
发表了文章
2024-09-09
发表了文章
2024-09-09
发表了文章
2024-09-09
发表了文章
2024-09-09
发表了文章
2024-09-09
发表了文章
2024-09-09
 回答了问题
2024-04-27
回答了问题
2024-04-27
回答了问题
2024-04-27
回答了问题
2024-04-27
回答了问题
2024-04-27
回答了问题
2024-04-27
回答了问题
2024-04-27
回答了问题
2024-04-27
回答了问题
2024-04-27
回答了问题
2024-04-27
 提交了问题
2024-04-24
回答了问题
2024-04-24
回答了问题
2024-04-24
提交了问题
2024-04-24
回答了问题
2024-04-24
回答了问题
2024-04-24






