专注介绍阿里云视觉智能开放平台的各类目视觉AI能力,为企业和开发者提供易用、普惠的视觉API服务。
AI热点日报隆重推出! 我们汇集了最新的AI热点信息、最新论文和观点,为您提供最前沿的AI领域资讯。 (往期链接请在子社区查看官方博文哦~)
8月23日 11:09 AI热点日报隆重推出! 我们汇集了最新的AI热点信息、最新论文和观点,为您提供最前沿的AI领域资讯。 (往期链接请在子社区查看官方博文哦~)
AI热点日报隆重推出! 我们汇集了最新的AI热点信息、最新论文和观点,为您提供最前沿的AI领域资讯。 (往期链接请在子社区查看官方博文哦~)
AI热点日报隆重推出! 我们汇集了最新的AI热点信息、最新论文和观点,为您提供最前沿的AI领域资讯。 (往期链接请在子社区查看官方博文哦~)
AI热点日报隆重推出! 我们汇集了最新的AI热点信息、最新论文和观点,为您提供最前沿的AI领域资讯。 (往期链接请在子社区查看官方博文哦~)
AI热点日报隆重推出! 我们汇集了最新的AI热点信息、最新论文和观点,为您提供最前沿的AI领域资讯。 (往期链接请在子社区查看官方博文哦~)
📣📣📣视觉智能开放平台子社区建立新版块——AI热点日报~
FaceChain团队推出了开源人物写真项目,希望结合开源社区开发者的力量,可以让图片应用更有趣、更好玩、也有更多应用场景。
AI热点日报八月第13期隆重推出! 我们汇集了最新的AI热点信息、最新论文和观点,为您提供最前沿的AI领域资讯。 (往期链接请在子社区查看官方博文哦~)
AI热点日报八月第12期隆重推出! 我们汇集了最新的AI热点信息、最新论文和观点,为您提供最前沿的AI领域资讯。 (往期链接请在子社区查看官方博文哦~)
AI热点日报八月第12期隆重推出! 我们汇集了最新的AI热点信息、最新论文和观点,为您提供最前沿的AI领域资讯。 (往期链接请在子社区查看官方博文哦~)
AI热点日报八月第11期隆重推出! 我们汇集了最新的AI热点信息、最新论文和观点,为您提供最前沿的AI领域资讯。 (往期链接请在子社区查看官方博文哦~)
AI热点日报八月第10期隆重推出! 我们汇集了最新的AI热点信息、最新论文和观点,为您提供最前沿的AI领域资讯。 (往期链接请在子社区查看官方博文哦~)
AI热点日报八月第9期隆重推出! 我们汇集了最新的AI热点信息、最新论文和观点,为您提供最前沿的AI领域资讯。 (往期链接请在子社区查看官方博文哦~)
AI热点日报八月第8期隆重推出! 我们汇集了最新的AI热点信息、最新论文和观点,为您提供最前沿的AI领域资讯。 (往期链接请在子社区查看官方博文哦~)
AI热点日报八月第7期隆重推出! 我们汇集了最新的AI热点信息、最新论文和观点,为您提供最前沿的AI领域资讯。 (往期链接请在子社区查看官方博文哦~)
AI热点日报八月第6期隆重推出! 我们汇集了最新的AI热点信息、最新论文和观点,为您提供最前沿的AI领域资讯。 (往期链接请在子社区查看官方博文哦~)
AI热点日报八月第6期隆重推出! 我们汇集了最新的AI热点信息、最新论文和观点,为您提供最前沿的AI领域资讯。 (往期链接请在子社区查看官方博文哦~)
AI热点日报八月第5期隆重推出! 我们汇集了最新的AI热点信息、最新论文和观点,为您提供最前沿的AI领域资讯。 (往期链接请在子社区查看官方博文哦~)
AI热点日报八月第4期隆重推出! 我们汇集了最新的AI热点信息、最新论文和观点,为您提供最前沿的AI领域资讯。 (往期链接请在子社区查看官方博文哦~)
AI热点日报八月第三期隆重推出! 我们汇集了最新的AI热点信息、最新论文和观点,为您提供最前沿的AI领域资讯。 (往期链接请在子社区查看官方博文哦~)
AI热点日报八月第二期隆重推出! 我们汇集了最新的AI热点信息、最新论文和观点,为您提供最前沿的AI领域资讯。 (往期链接请在子社区查看官方博文哦~)
AI热点日报八月第一期隆重推出! 我们汇集了最新的AI热点信息、最新论文和观点,为您提供最前沿的AI领域资讯。 (往期链接请在子社区查看官方博文哦~)
AI热点日报第三期隆重推出! 我们汇集了最新的AI热点信息、最新论文和观点,为您提供最前沿的AI领域资讯。
AI热点日报第二期隆重推出! 我们汇集了最新的AI热点信息、最新论文和观点,为您提供最前沿的AI领域资讯。
AI热点日报第一期隆重推出! 我们汇集了最新的AI热点信息、最新论文和观点,为您提供最前沿的AI领域资讯。
高保真 3D 头部重建在许多场景中都有广泛的应用,例如 AR/VR、医疗、电影制作等。尽管大量的工作已经使用 LightStage 等专业硬件实现了出色的重建效果,从单一或稀疏视角的单目图像估计高精细的面部模型仍然是一个具有挑战性的任务。 本文中,我们将介绍CVPR2023最新的头部重建论文,该工作在单图头部重建榜单REALY上取得正脸、侧脸双榜第一,并在其他多个数据集中取得了SOTA的效果。
随着AI技术的问世,物流行业迎来了速度、准确率、系统化的全方位提升 。通过使用AI识别车牌与车辆功能,物流企业可以实现对车辆的快速、准确的识别,提高物流车辆的管理效率。此外,AI还可以帮助物流企业实现对车辆功能的识别,如车辆类型、载重等,为物流调度提供更加科学的指导。AI识别车牌与车辆功能的应用正日益普及,为智慧物流行业带来了新的发展机遇。
论文链接:https://arxiv.org/abs/2303.08594
如今我们正逐渐进入一个智能化时代,AI视频互动娱乐在娱乐场景中被广泛应用。它利用先进的人工智能技术和互动性强的视频娱乐形式,为用户带来全新的娱乐体验。无论是与虚拟角色互动竞技,还是参与丰富多样的虚拟现实体验,AI视频互动娱乐都能让用户沉浸其中。现如今我们可以在电子游戏、电影、电视节目等传统娱乐形式中见到视觉AI的影子。 那么,AI和我们的生活娱乐中能撞出什么火花?来看看当下最火爆的视频互娱新玩法吧~
论文链接:Digging into Uncertainty inSelf-supervised Multi-view Stereo 多视图立体视觉作为计算机视觉领域的一项基本的任务,利用同一场景在不同视角下的多张图片来重构3D的信息。自监督多视角立体视觉(MVS)近年来取得了显著的进展。然而,以往的方法缺乏对自监督MVS中pretext任务提供的监督信号进行有效性的全面解释。本文首次提出在自监督MVS中估计认知不确定性(epistemic uncertainty)。
论文链接:Dash: Semi-Supervised Learningwith DynamicThreolding 本文介绍机器学习顶级国际会议 ICML 2021 接收的 long talk (top 3.02%) 论文 “Dash: Semi-Supervised Learning with Dynamic Thresholding”。
随着科技和经济的发展,考勤管理制度无论是对于企业还是学习,都是相对重要的管理制度。在传统考勤制度中,员工的出勤和工时需要依靠人工记录,并需要相应的人力来处理和审批。这种方式在浪费了时间和人力成本的基础上,还极易出现数据记录错误,造成一系列严重的后果。现如今,随着视觉智能AI的发展,智慧考勤可以实现。除了可以解决传统的考勤制度中的劣势之外, 还具备完善的数据传输和保存系统,管理者可以更好地利用考勤数据和实时通知系统,更好地规划资源和调整工作安排。
最近有两个计算机应用发展的方向正在潜移默化的汇拢中:1.)模型即服务 2.)人工智能(AI)。它们的会师正逐渐形成模型即服务AI热潮。 近几年模型即服务一直被人津津乐道,这是提升AI编程效率、加速AI创新应用的大趋势。人工智能领域近几年非常火热,基于AI的行业创新应用层出不穷,尤其今年的AI绘画又大有元年之势,相应介绍可查阅《人工智能内容生成元年—AI绘画原理解析》。如下章节将重点介绍如何通过模型即服务来完成AI功能调用以及相应AI应用搭建。
论文链接:https://arxiv.org/pdf/2210.15511.pdf
本文介绍视频生产(videoenhan)类目下的通用视频人脸融合MergeVideoFace的功能介绍以及代码示例。
● 论文链接:https://arxiv.org/abs/2210.15518
随着全民健身热潮的提升,智慧健身运动随着数字化新技术的进步,以及在运动健身领域的应用逐渐趋于成熟,智能运动健身将为传统运动健身提供更多新的方向和玩法,满足不同项目爱好者的健身需求。随着AI运动健身技术的进一步普及与应用,基于ai的智慧健身运动技术未来可打造的场景化空间会越来越多,体育运动与科技娱乐,智慧健身运动在线上体育行业未来会创新运动场景,丰富运动体验,提升竞技娱乐性,推动全民健身走向新的高度。
MOS(Mean Opinion Score)是一种常用的主观质量评价方法,常用于视频、图像等多媒体领域中的质量评价。MOS视觉评价通常是通过让受试者观看视频/图像,对视频的清晰度、锐度、颜色饱和度、运动模糊、噪声等方面进行评价。然而,MOS视觉评价也存在一些局限,例如需要大量的受试者,评估时间较长等。因此,近年来,研究者们也开始探索使用客观评价方法来替代或补充MOS视觉评价。
本文介绍我们被机器学习顶级国际会议ICLR 2023接收的论文 “DamoFD: Digging into Backbone Design on Face Detection" 论文链接:https://openreview.net/pdf?id=NkJOhtNKX91 开源代码:https://github.com/ly19965/EasyFace/tree/master/face_project/face_detection/DamoFD
近10年来,深度学习技术得到了长足进步,在图像增强领域取得了显著的成果,尤其是以GAN为代表的生成式模型在图像复原、老片修复,图像超分辨率等方面大放异彩。图像超分辨率是视频增强方面,用于提升画质的典型应用。生成对抗网络GAN使得在图像分辨率增加的同时,保持细节特征,补充生成真实的纹理,其中应用广泛的工作是Real-ESRGAN。
图像分类是当前AI最为成功的实际应用技术之一,它已经融入了人们的日常生活。它被广泛的应用到了计算机视觉的大部分任务中,比如图像分类、图像搜索、OCR、内容审核、识别认证等领域。目前已形成一个普遍共识:“当数据集越大ID越多时,只要训练得当,相应分类任务的效果就会越好”。但是面对千万ID甚至上亿ID,当下流行的DL框架下,很难低成本的直接进行如此超大规模的分类训练。
SoftTriple Loss论文是在图像细粒度分类领域提出了新型度量学习方法,该方法可以被广泛应用于各种搜索、识别等领域中,目前谷歌学术引用240+,相对高引。相比原始论文文档,本文将介绍更多研究过程中遇到的问题点以及相应创新方法的演进历史。
随着数字文化产业的蓬勃发展,人工智能技术开始广泛应用于图像编辑和美化领域。其中,人像美肤无疑是应用最广、需求最大的技术之一。传统美颜算法利用基于滤波的图像编辑技术,实现了自动化的磨皮去瑕疵效果,在社交、直播等场景取得了广泛的应用。然而,在门槛较高的专业摄影行业,由于对图像分辨率以及质量标准的较高要求,人工修图师还是作为人像美肤修图的主要生产力,完成包括匀肤、去瑕疵、美白等一系列工作。通常,一位专业修图师对一张高清人像进行美肤操作的平均处理时间为1-2分钟,在精度要求更高的广告、影视等领域,该处理时间则更长。
人脸检测算法是在一幅图片或者视频序列中检测出来人脸的位置,给出人脸的具体坐标,一般是矩形坐标。
高效的时空建模(Spatiotemporal modeling)是视频理解和动作识别的核心问题。相较于图像的Transformer网络,视频由于增加了时间维度,如果将Transformer中的自注意力机制(Self-Attention)简单扩展到时空维度,将会导致时空自注意力高昂的计算复杂度和空间复杂度。
随着自媒体与短视频的兴起,人们有了越来越多的拍摄视频的需求。然而由于手持拍摄、硬件限制等原因,利用手机等普通摄影设备拍摄的视频难免存在视频抖动问题。尤其是开启较高倍数的变焦后,手持拍摄很难拍摄到稳定的视频,极易产生抖动的现象。使用云台、斯坦尼康等外设可以缓解这样的抖动,但是很多时候多带一个外设降低了拍摄视频的便利程度,会使得随时随地的拍摄体验大打折扣。
随着网络电视、手机等新媒体领域的快速发展,用户对于观看视频质量的要求也越来越高。当前市面上所广为传播的视频帧率大多仍然处于20~30fps,已经无法满足用户对于高清、流畅的体验追求。而视频插帧算法,能够有效实现多倍率的帧率提升,有效消除低帧率视频的卡顿感,让视频变得丝滑流畅。配合其它的视频增强算法,更是能够让低质量视频焕然一新,让观众享受到极致的播放和观看体验。
信息检索产品几乎是人们生活中必不可少的工具,经常用的有文本搜文本、图片搜图片等应用。以上任务均为单模态的检索。而多模态检索则处理涵盖原有的单模态检索任务以外,也包含跨模态检索任务,即文搜图、文搜视频等任务。要实现这一任务,则需要底层的表征模型具备图文对齐的能力,换句话说,要实现多模态检索,表征模型应实现将不同模态信息的特征映射到同一个域内,从而实现不同模态之间的相互检索。CLIP的多模态技术出现以来,给多模态检索领域带来了新的技术变革,使得实现基于通用表征大模型的大规模多模态检索系统成为可能。
随着摄影技术的演进,彩色照片在现在已经非常普及,但仍然有大量历史黑白照片遗留。图像上色可以对这些宝贵的旧时代遗产进行修复,令老照片重获新生。
 发表了文章
2024-05-15
发表了文章
2023-11-10
发表了文章
2023-11-09
发表了文章
2023-11-07
发表了文章
2023-11-06
发表了文章
2023-11-03
发表了文章
2023-11-02
发表了文章
2023-11-02
发表了文章
2023-11-01
发表了文章
2023-10-31
发表了文章
2023-10-31
发表了文章
2023-10-30
发表了文章
2023-10-25
发表了文章
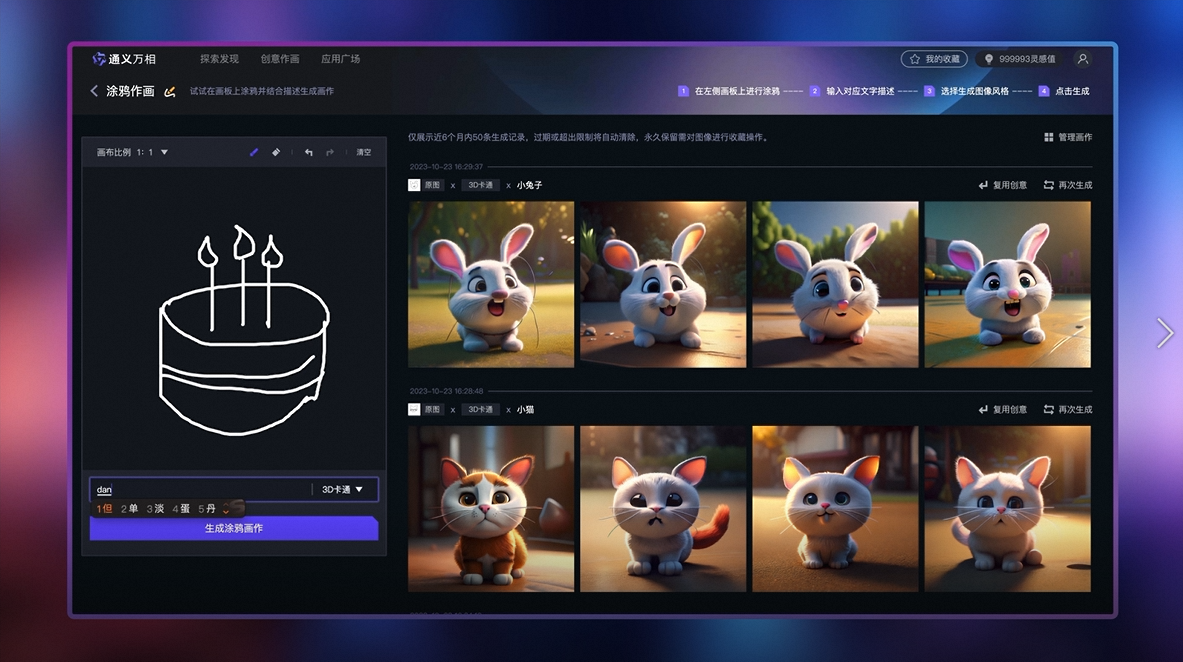
2023-10-23
发表了文章
2023-10-20
发表了文章
2023-10-19
发表了文章
2023-10-18
发表了文章
2023-10-17
发表了文章
2023-10-17
发表了文章
2023-10-16
发表了文章
2024-05-15
发表了文章
2023-11-10
发表了文章
2023-11-09
发表了文章
2023-11-07
发表了文章
2023-11-06
发表了文章
2023-11-03
发表了文章
2023-11-02
发表了文章
2023-11-02
发表了文章
2023-11-01
发表了文章
2023-10-31
发表了文章
2023-10-31
发表了文章
2023-10-30
发表了文章
2023-10-25
发表了文章
2023-10-23
发表了文章
2023-10-20
发表了文章
2023-10-19
发表了文章
2023-10-18
发表了文章
2023-10-17
发表了文章
2023-10-17
发表了文章
2023-10-16

 回答了问题
2023-07-11
回答了问题
2023-07-11