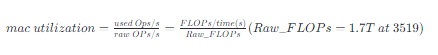? 阿里云社区专家博主,大厂算法开发工程师。 ? 从事视觉算法开发和模型压缩部署工作。 ? 欢迎关注我的公众号-嵌入式视觉。
2023年03月
 回答了问题
2023-03-28 14:39:46
回答了问题
2023-03-25 18:10:58
回答了问题
2023-03-25 18:08:13
回答了问题
2023-03-18 00:50:35
回答了问题
2023-03-18 00:47:55
回答了问题
2023-03-06 19:53:31
回答了问题
2023-03-05 01:28:10
回答了问题
2023-03-28 14:39:46
回答了问题
2023-03-25 18:10:58
回答了问题
2023-03-25 18:08:13
回答了问题
2023-03-18 00:50:35
回答了问题
2023-03-18 00:47:55
回答了问题
2023-03-06 19:53:31
回答了问题
2023-03-05 01:28:10
2023年02月
回答了问题
2023-02-23 16:29:23
回答了问题
2023-02-17 17:47:25
回答了问题
2023-02-17 17:30:40
回答了问题
2023-02-14 19:28:37
回答了问题
2023-02-13 20:43:11
回答了问题
2023-02-11 00:41:34
回答了问题
2023-02-11 00:30:08
回答了问题
2023-02-10 23:14:45
回答了问题
2023-02-10 05:01:56
回答了问题
2023-02-10 04:58:50
回答了问题
2023-02-08 05:11:54
回答了问题
2023-02-08 02:49:31
2023年01月
 发表了文章
2023-01-30 17:57:26
发表了文章
2023-01-30 17:57:26
 发表了文章
2023-01-30 17:56:51
发表了文章
2023-01-30 17:56:51
 发表了文章
2023-01-30 17:56:04
发表了文章
2023-01-30 17:56:04
 发表了文章
2023-01-30 17:53:46
发表了文章
2023-01-30 17:52:55
发表了文章
2023-01-30 17:53:46
发表了文章
2023-01-30 17:52:55
 发表了文章
2023-01-30 17:51:25
发表了文章
2023-01-30 17:51:25
 发表了文章
2023-01-30 17:45:08
发表了文章
2023-01-30 17:45:08
 发表了文章
2023-01-30 17:39:33
发表了文章
2023-01-30 17:39:33
 发表了文章
2023-01-30 17:38:02
发表了文章
2023-01-30 17:38:02
 发表了文章
2023-01-30 17:37:13
发表了文章
2023-01-30 17:37:13
 发表了文章
2023-01-30 17:34:04
发表了文章
2023-01-30 17:30:14
发表了文章
2023-01-30 17:34:04
发表了文章
2023-01-30 17:30:14
 发表了文章
2023-01-30 17:29:32
发表了文章
2023-01-30 17:29:32
 发表了文章
2023-01-30 17:27:52
发表了文章
2023-01-30 17:27:52
 发表了文章
2023-01-14 13:43:43
发表了文章
2023-01-14 13:40:41
发表了文章
2023-01-14 13:38:21
发表了文章
2023-01-14 13:34:10
发表了文章
2023-01-12 15:10:34
发表了文章
2023-01-14 13:43:43
发表了文章
2023-01-14 13:40:41
发表了文章
2023-01-14 13:38:21
发表了文章
2023-01-14 13:34:10
发表了文章
2023-01-12 15:10:34
 回答了问题
2023-01-10 15:04:02
回答了问题
2023-01-10 14:58:12
回答了问题
2023-01-10 14:55:54
回答了问题
2023-01-03 17:28:07
回答了问题
2023-01-10 15:04:02
回答了问题
2023-01-10 14:58:12
回答了问题
2023-01-10 14:55:54
回答了问题
2023-01-03 17:28:07
2022年12月
发表了文章
2022-12-27 22:19:00
发表了文章
2022-12-27 22:18:13
发表了文章
2022-12-27 22:17:35
发表了文章
2023-01-30
发表了文章
2023-01-30
发表了文章
2023-01-30
发表了文章
2023-01-30
发表了文章
2023-01-30
发表了文章
2023-01-30
发表了文章
2023-01-30
发表了文章
2023-01-30
发表了文章
2023-01-30
发表了文章
2023-01-30
发表了文章
2023-01-30
发表了文章
2023-01-30
发表了文章
2023-01-30
发表了文章
2023-01-30
发表了文章
2023-01-14
发表了文章
2023-01-14
发表了文章
2023-01-14
发表了文章
2023-01-14
发表了文章
2023-01-12
发表了文章
2022-12-27
 回答了问题
2023-03-28
回答了问题
2023-03-25
回答了问题
2023-03-25
回答了问题
2023-03-18
回答了问题
2023-03-18
回答了问题
2023-03-06
回答了问题
2023-03-05
回答了问题
2023-02-23
回答了问题
2023-02-17
回答了问题
2023-02-17
回答了问题
2023-02-14
回答了问题
2023-02-13
回答了问题
2023-02-11
回答了问题
2023-02-11
回答了问题
2023-02-10
回答了问题
2023-02-10
回答了问题
2023-02-10
回答了问题
2023-02-08
回答了问题
2023-02-08
回答了问题
2023-01-10
回答了问题
2023-03-28
回答了问题
2023-03-25
回答了问题
2023-03-25
回答了问题
2023-03-18
回答了问题
2023-03-18
回答了问题
2023-03-06
回答了问题
2023-03-05
回答了问题
2023-02-23
回答了问题
2023-02-17
回答了问题
2023-02-17
回答了问题
2023-02-14
回答了问题
2023-02-13
回答了问题
2023-02-11
回答了问题
2023-02-11
回答了问题
2023-02-10
回答了问题
2023-02-10
回答了问题
2023-02-10
回答了问题
2023-02-08
回答了问题
2023-02-08
回答了问题
2023-01-10