





暂时未有相关云产品技术能力~
资深AI全栈工程师 | UCD主SE | CSDN专家 9年经验,擅长AI全栈和AIGC。曾任CTO助理,现为上市公司UCD设计推进与落地技术专家,专注产品创新与用户体验。
2024年07月
 发表了文章
2024-07-08 15:14:39
发表了文章
2024-07-08 15:13:42
发表了文章
2024-07-08 15:14:39
发表了文章
2024-07-08 15:13:42
 发表了文章
2024-07-08 15:12:48
发表了文章
2024-07-08 15:11:58
发表了文章
2024-07-08 15:00:28
发表了文章
2024-07-08 14:59:40
发表了文章
2024-07-08 14:58:38
发表了文章
2024-07-08 14:57:44
发表了文章
2024-07-08 14:56:20
发表了文章
2024-07-08 15:12:48
发表了文章
2024-07-08 15:11:58
发表了文章
2024-07-08 15:00:28
发表了文章
2024-07-08 14:59:40
发表了文章
2024-07-08 14:58:38
发表了文章
2024-07-08 14:57:44
发表了文章
2024-07-08 14:56:20
 发表了文章
2024-07-08 14:54:16
发表了文章
2024-07-08 14:54:16
 发表了文章
2024-07-08 14:52:59
发表了文章
2024-07-08 14:52:59
 发表了文章
2024-07-08 14:50:16
发表了文章
2024-07-08 14:50:16
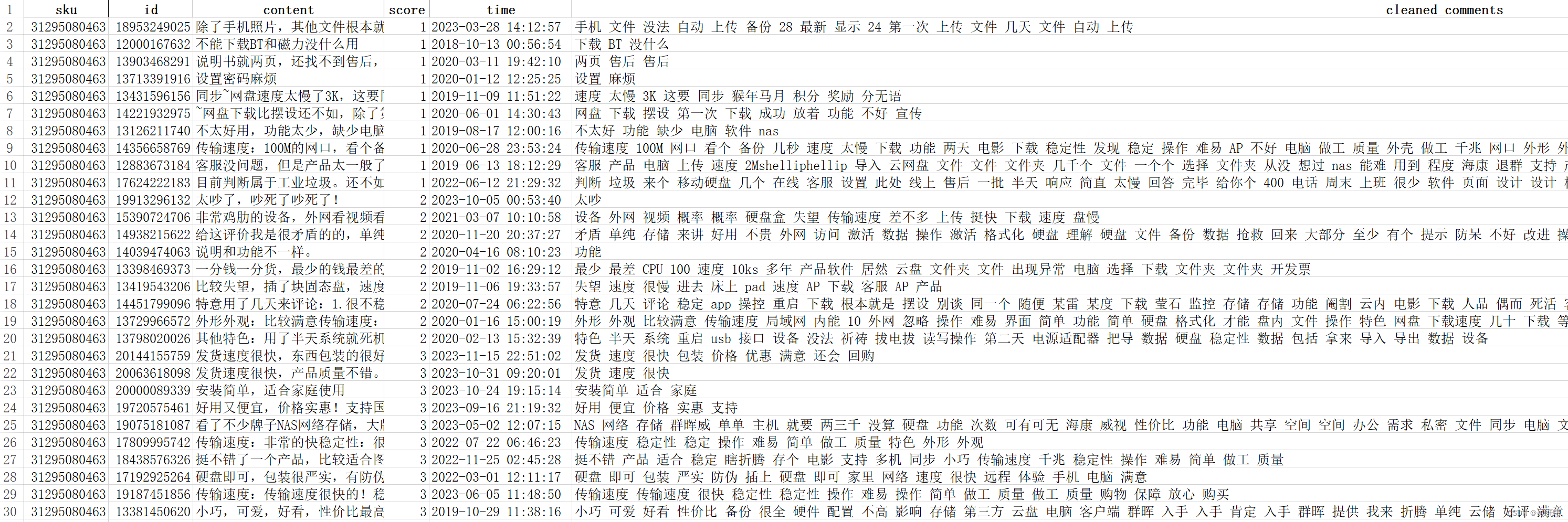 发表了文章
2024-07-08 14:47:41
发表了文章
2024-07-08 14:47:41
 发表了文章
2024-07-08 14:44:02
发表了文章
2024-07-08 14:44:02
 发表了文章
2024-07-08 14:41:26
发表了文章
2024-07-12
发表了文章
2024-07-11
发表了文章
2024-07-10
发表了文章
2024-07-08
发表了文章
2024-07-08
发表了文章
2024-07-08
发表了文章
2024-07-08
发表了文章
2024-07-08
发表了文章
2024-07-08
发表了文章
2024-07-08
发表了文章
2024-07-08
发表了文章
2024-07-08
发表了文章
2024-07-08
发表了文章
2024-07-08
发表了文章
2024-07-08
发表了文章
2024-07-08
发表了文章
2024-07-08
发表了文章
2024-07-08
发表了文章
2024-07-08
发表了文章
2024-07-08
发表了文章
2024-07-08 14:41:26
发表了文章
2024-07-12
发表了文章
2024-07-11
发表了文章
2024-07-10
发表了文章
2024-07-08
发表了文章
2024-07-08
发表了文章
2024-07-08
发表了文章
2024-07-08
发表了文章
2024-07-08
发表了文章
2024-07-08
发表了文章
2024-07-08
发表了文章
2024-07-08
发表了文章
2024-07-08
发表了文章
2024-07-08
发表了文章
2024-07-08
发表了文章
2024-07-08
发表了文章
2024-07-08
发表了文章
2024-07-08
发表了文章
2024-07-08
发表了文章
2024-07-08
发表了文章
2024-07-08

 回答了问题
2024-07-09
回答了问题
2024-07-09
回答了问题
2024-07-09
回答了问题
2024-07-09










