





暂时未有相关云产品技术能力~
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、最新论文解读、各种技术教程、CV招聘信息发布等。关注公众号可邀请加入免费版的知识星球和技术交流群。
2022年04月
 发表了文章
2022-04-24 10:56:19
发表了文章
2022-04-24 10:56:19
 发表了文章
2022-04-24 10:52:21
发表了文章
2022-04-24 10:52:21
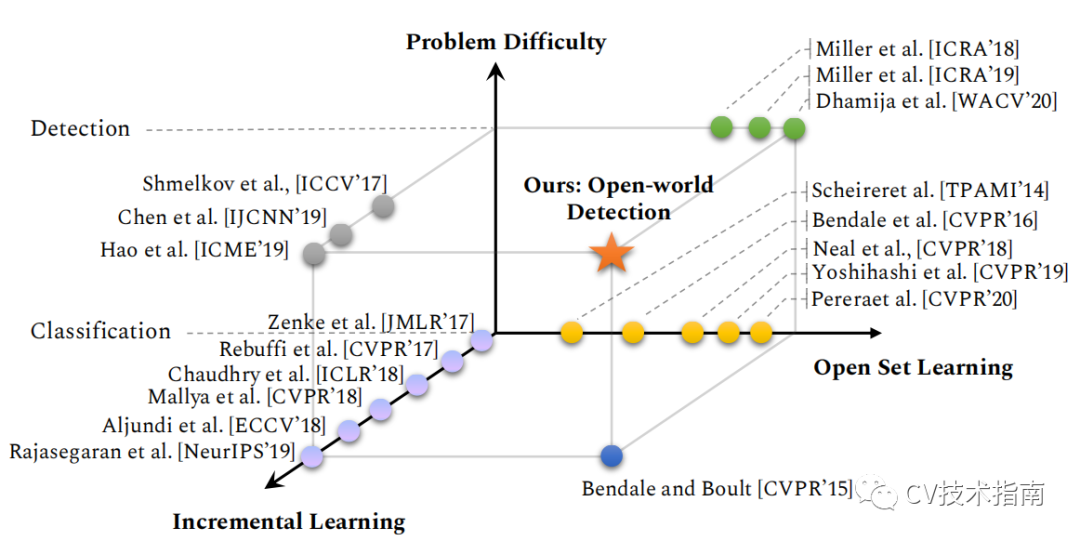 发表了文章
2022-04-24 10:46:47
发表了文章
2022-04-24 10:46:47
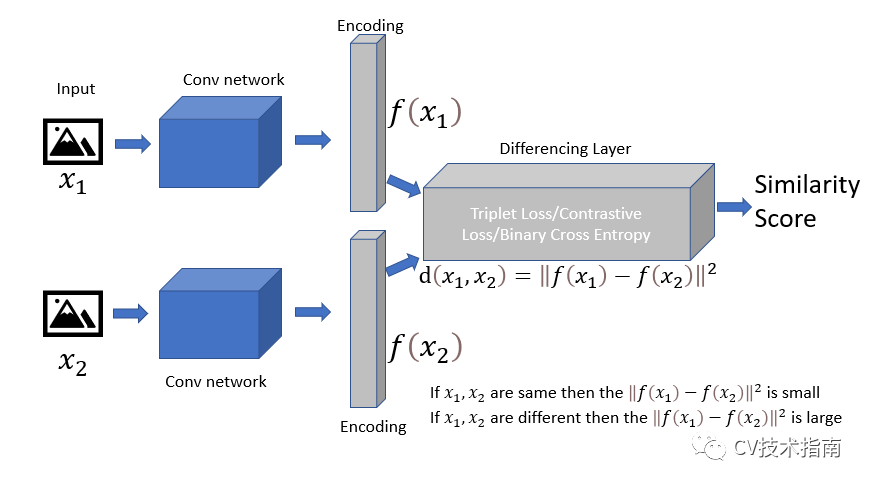 发表了文章
2022-04-24 10:43:23
发表了文章
2022-04-24 10:43:23
 发表了文章
2022-04-24 10:40:07
发表了文章
2022-04-24 10:40:07
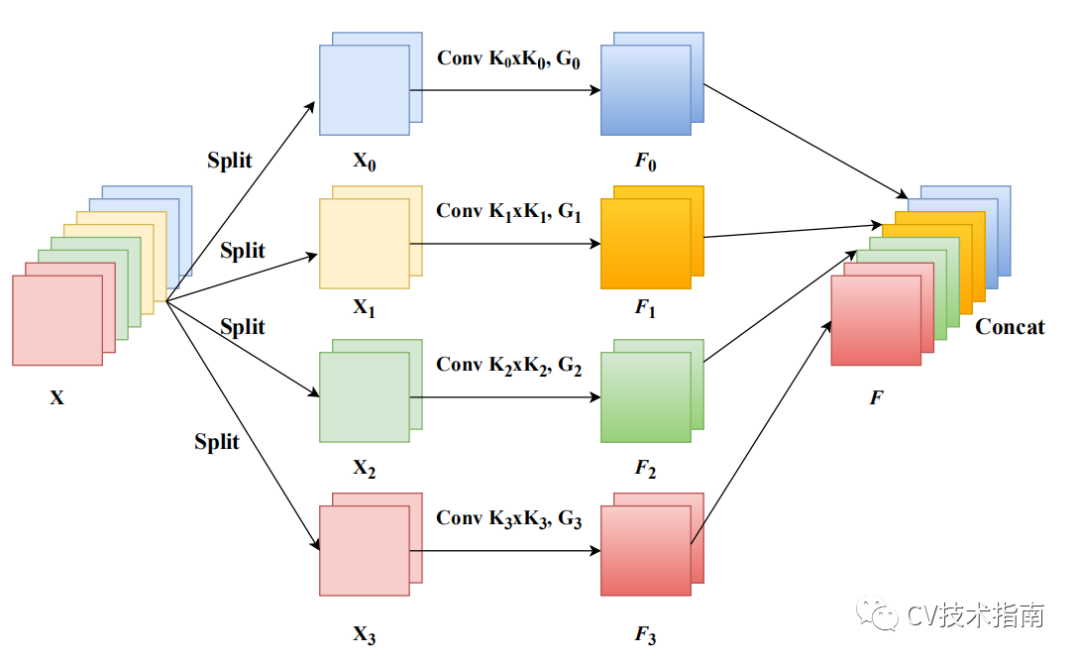 发表了文章
2022-04-24 10:36:53
发表了文章
2022-04-24 10:36:53
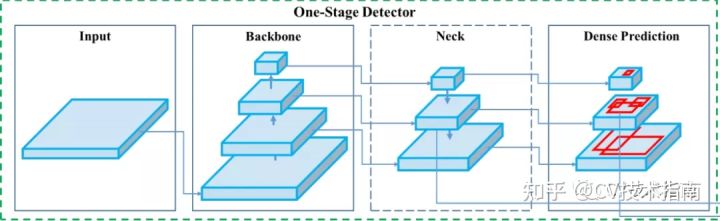 发表了文章
2022-04-24 10:33:39
发表了文章
2022-04-24 10:33:39
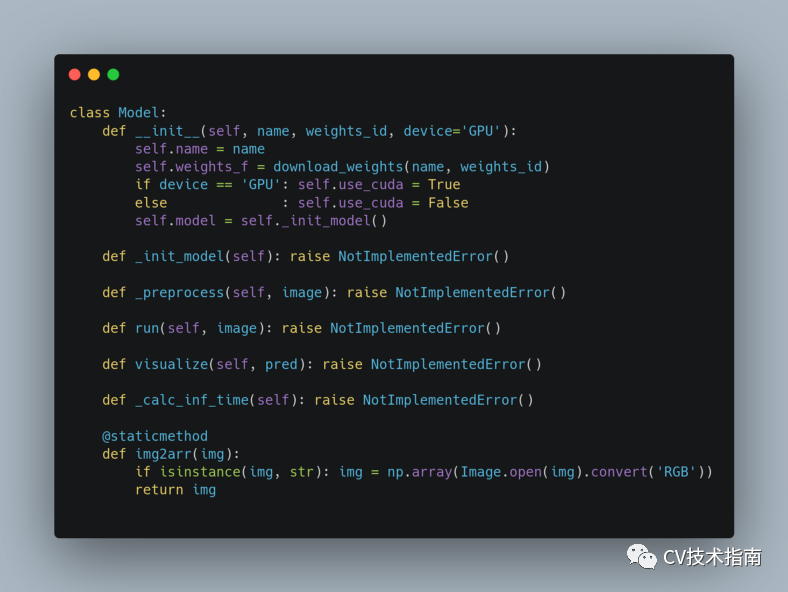 发表了文章
2022-04-24 10:30:42
发表了文章
2022-04-24 10:30:42
 发表了文章
2022-04-24 10:24:48
发表了文章
2022-04-24 10:24:48
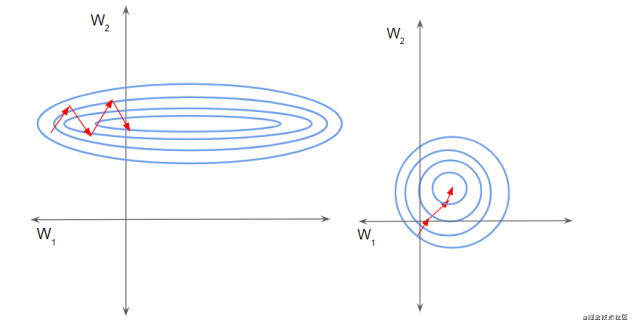 发表了文章
2022-04-24 10:12:49
发表了文章
2022-04-24 10:12:49
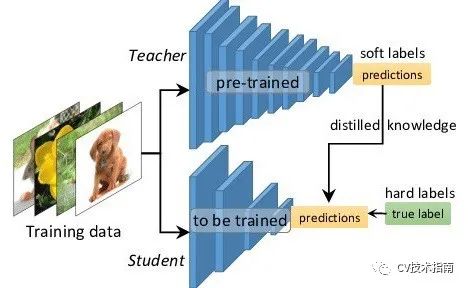 发表了文章
2022-04-24 10:08:11
发表了文章
2022-04-24 10:08:11
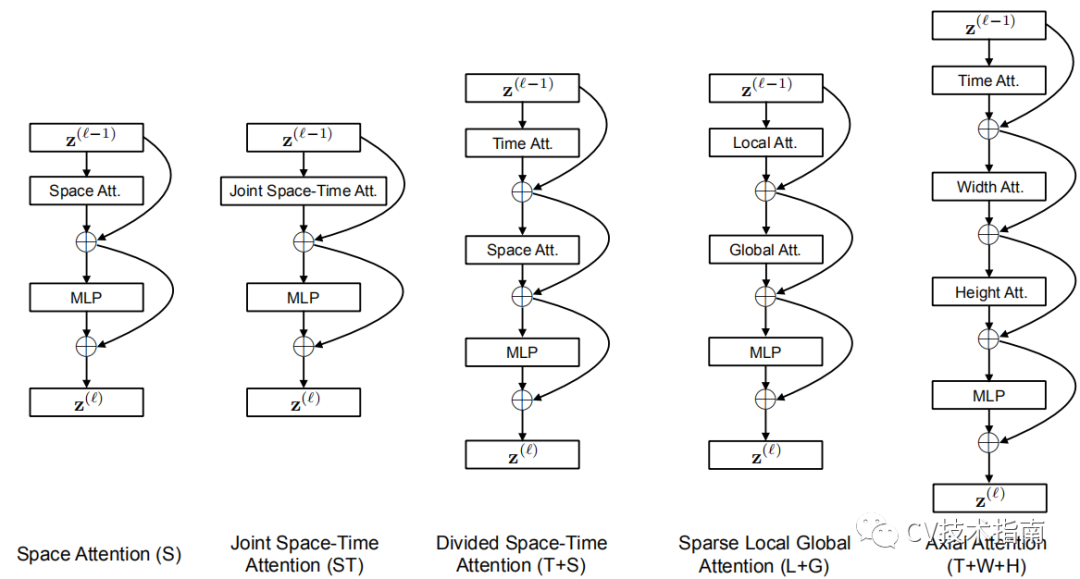 发表了文章
2022-04-24 10:05:14
发表了文章
2022-04-24 10:05:14
 发表了文章
2022-04-24 09:59:29
发表了文章
2022-04-24 09:59:29
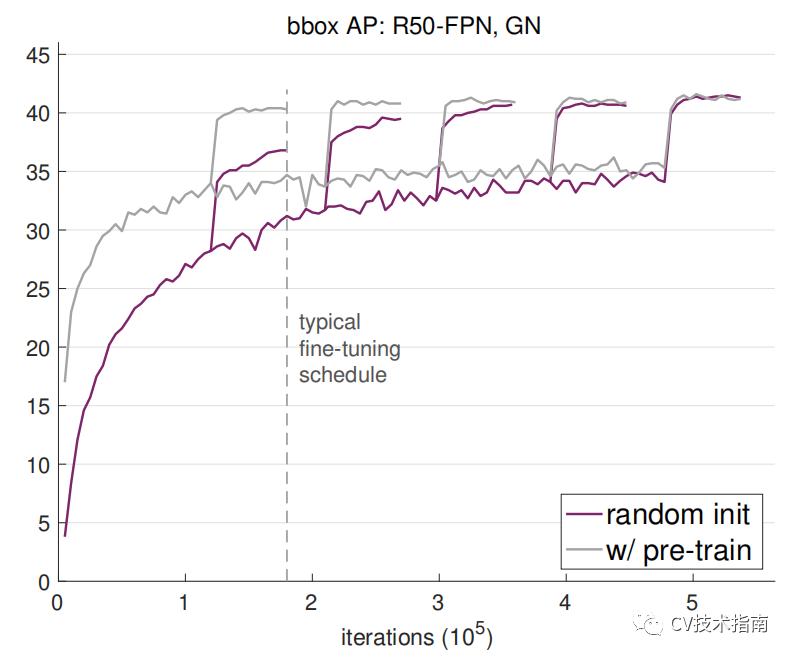 发表了文章
2022-04-24 09:56:45
发表了文章
2022-04-24 09:56:45
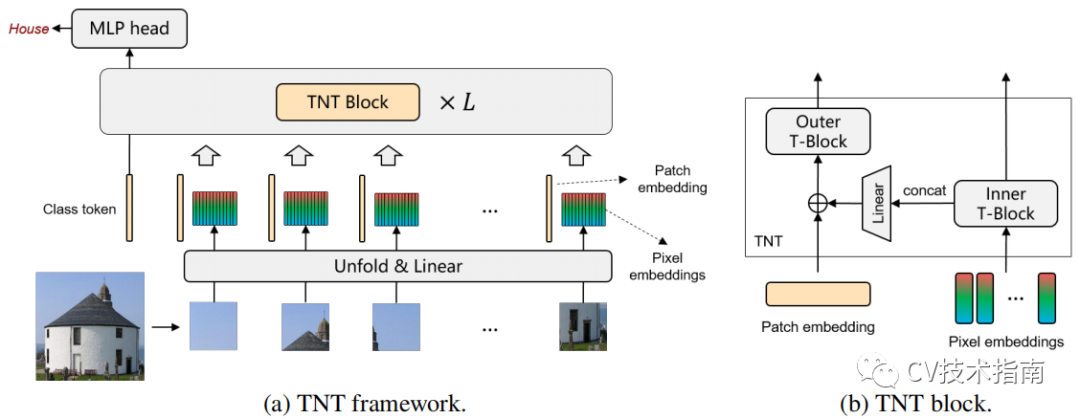 发表了文章
2022-04-24 09:53:09
发表了文章
2022-04-24 09:53:09
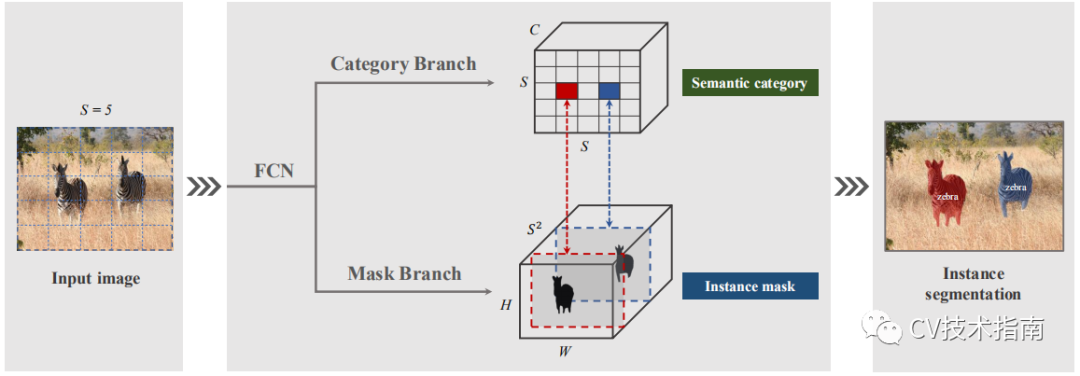 发表了文章
2022-04-24 09:49:49
发表了文章
2022-04-24 09:49:49
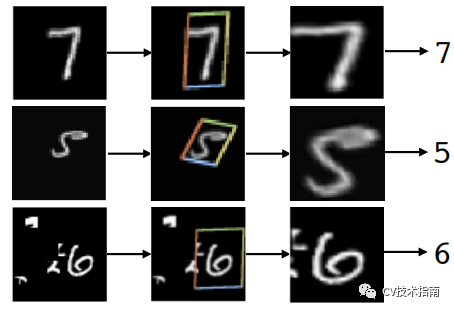 发表了文章
2022-04-24 09:40:23
发表了文章
2022-04-24 09:40:23
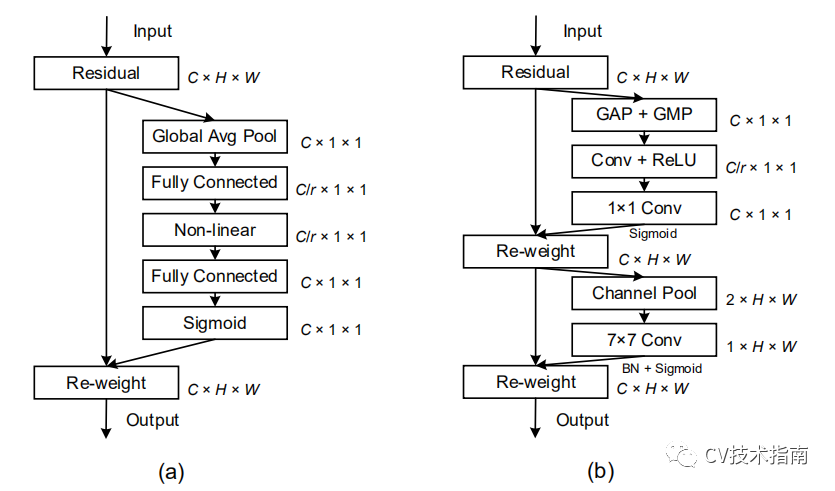 发表了文章
2022-04-24 09:37:01
发表了文章
2022-04-24 09:37:01
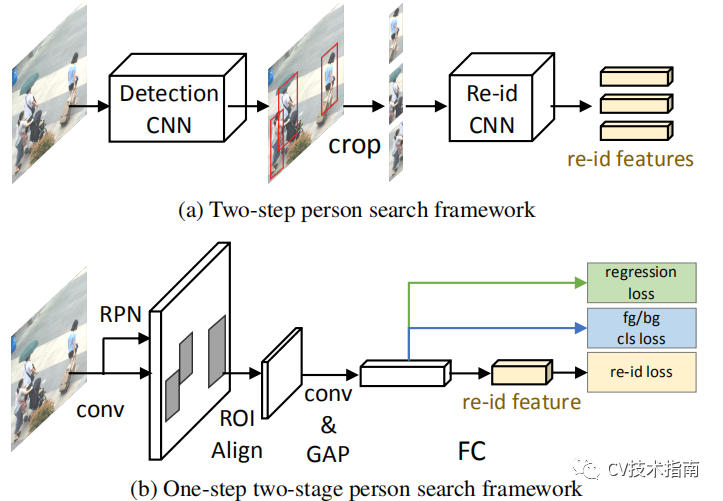 发表了文章
2022-04-24 09:32:59
发表了文章
2022-04-24 09:32:59
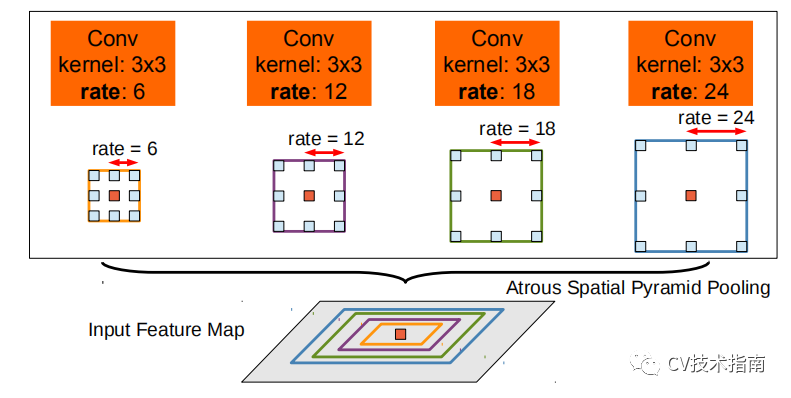 发表了文章
2022-04-24 09:26:53
发表了文章
2022-04-24 09:26:53
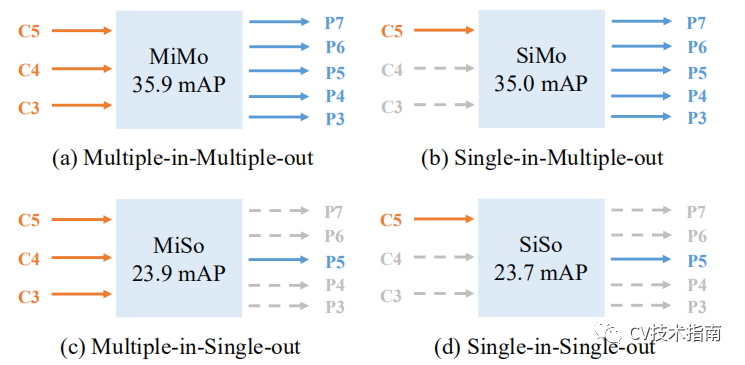 发表了文章
2022-04-24 09:23:13
发表了文章
2022-04-24 09:23:13
 发表了文章
2022-04-24 09:17:58
发表了文章
2022-04-24 09:17:58
 发表了文章
2022-04-24 09:10:12
发表了文章
2022-04-24 09:10:12
 发表了文章
2022-04-23 18:04:22
发表了文章
2022-04-23 18:04:22
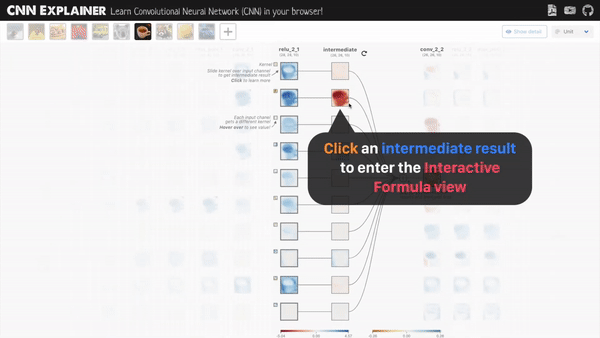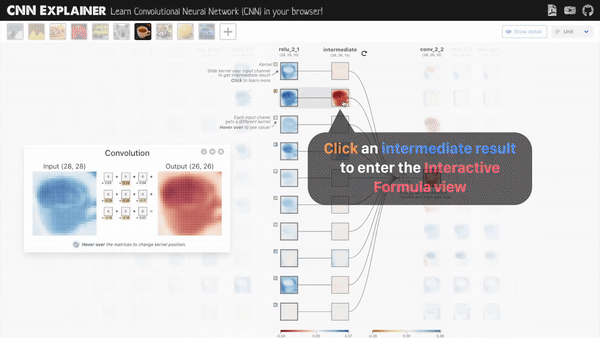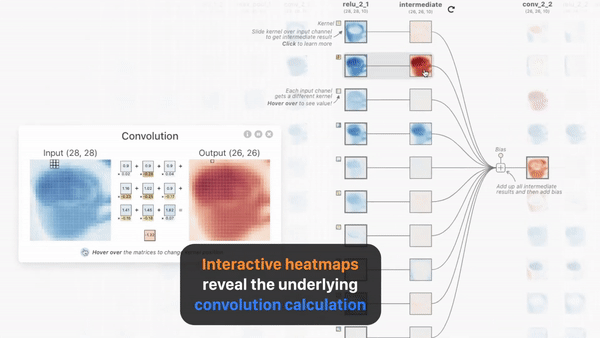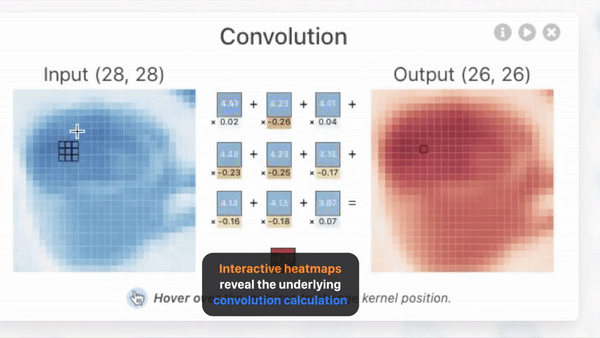 发表了文章
2022-04-23 17:59:10
发表了文章
2022-04-23 17:59:10
 发表了文章
2022-04-23 17:54:01
发表了文章
2022-04-23 17:54:01
 发表了文章
2022-04-23 17:48:40
发表了文章
2022-04-23 17:48:40
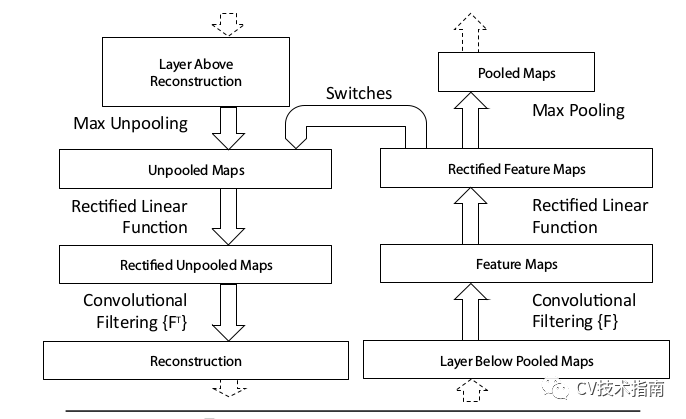 发表了文章
2022-04-23 17:43:05
发表了文章
2022-04-23 17:43:05
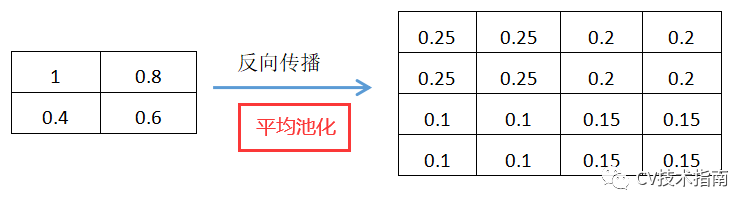 发表了文章
2022-04-23 17:34:59
发表了文章
2022-04-23 17:34:59
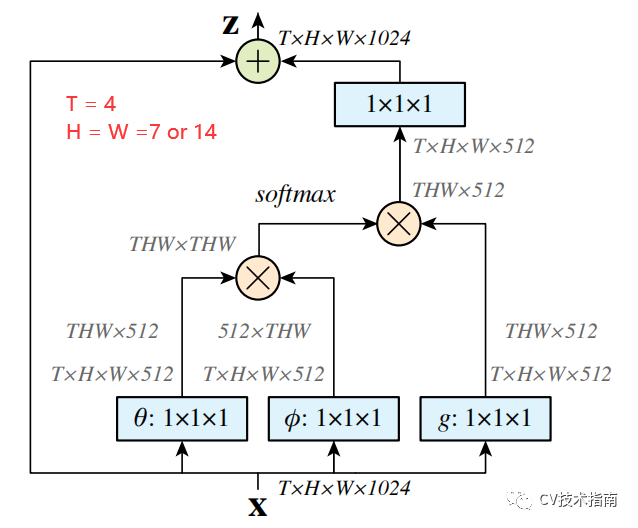 发表了文章
2022-04-23 17:31:16
发表了文章
2022-04-23 17:31:16
 发表了文章
2022-04-23 17:24:41
发表了文章
2022-04-23 17:24:41
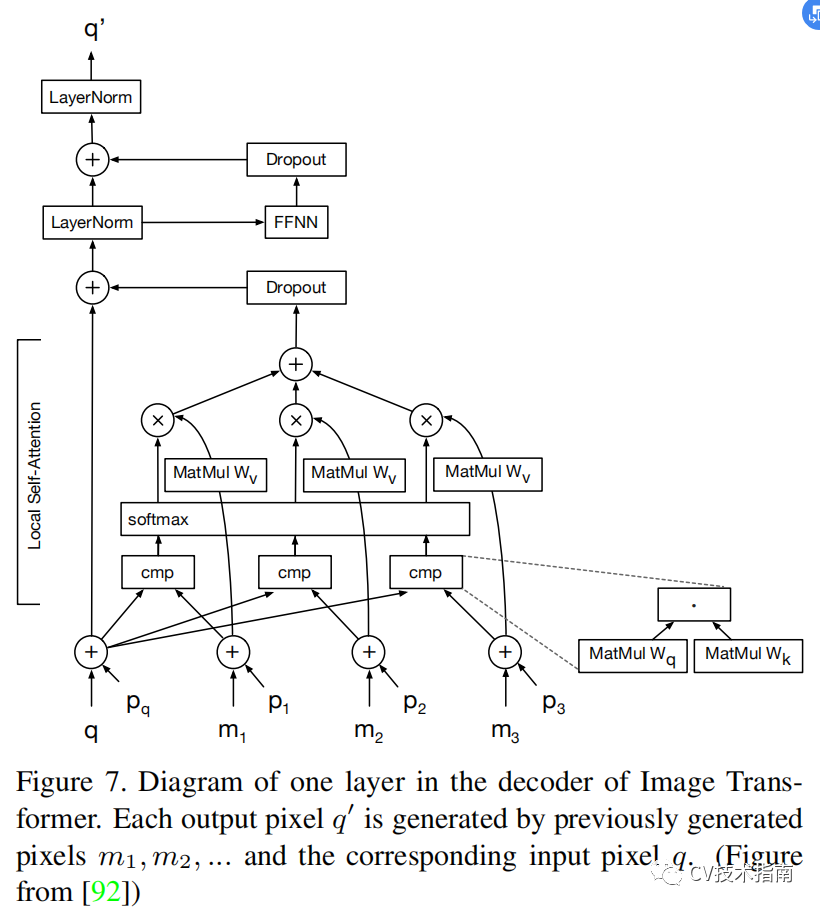 发表了文章
2022-04-23 17:16:35
发表了文章
2022-04-23 17:16:35
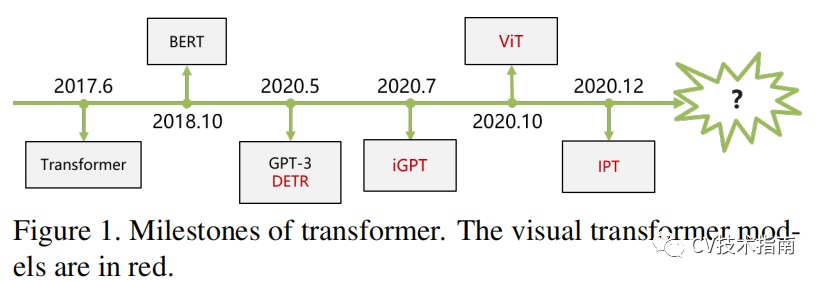 发表了文章
2022-04-23 16:59:59
发表了文章
2022-04-23 16:59:59
 发表了文章
2022-04-23 16:53:53
发表了文章
2022-04-23 16:53:53
 发表了文章
2022-04-23 16:50:39
发表了文章
2022-04-23 16:50:39
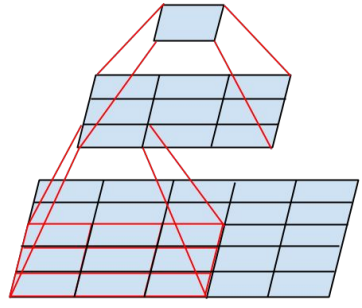 发表了文章
2022-04-23 16:44:29
发表了文章
2022-04-23 16:44:29
 发表了文章
2022-04-23 16:37:39
发表了文章
2022-04-23 16:37:39
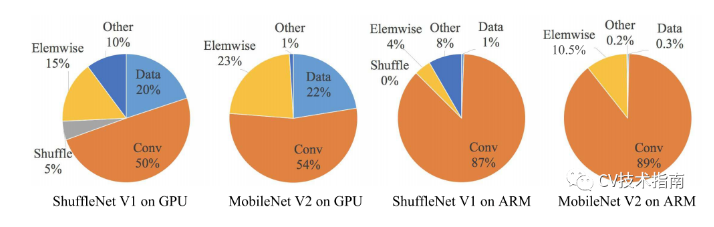 发表了文章
2022-04-23 16:29:55
发表了文章
2022-04-23 16:29:55
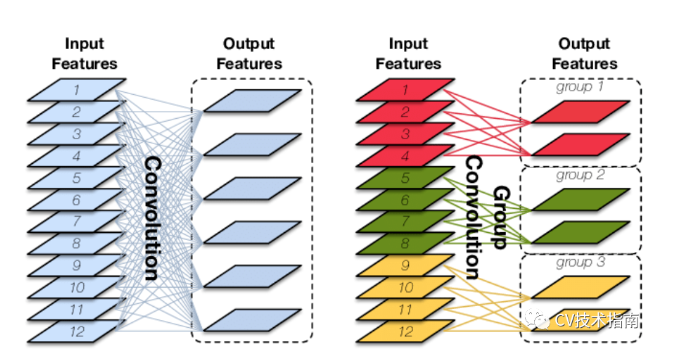 发表了文章
2022-04-23 16:24:29
发表了文章
2022-04-23 16:24:29
 发表了文章
2022-04-23 16:17:59
发表了文章
2022-04-23 16:17:59
 发表了文章
2022-04-23 16:08:05
发表了文章
2022-04-23 16:08:05
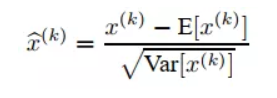 发表了文章
2022-04-23 16:03:11
发表了文章
2022-04-23 16:03:11
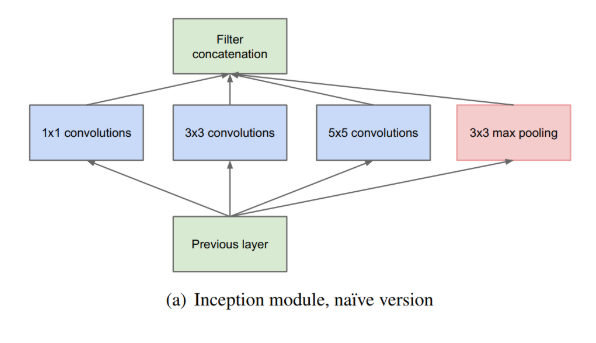 发表了文章
2022-04-23 15:55:00
发表了文章
2022-04-23 15:55:00
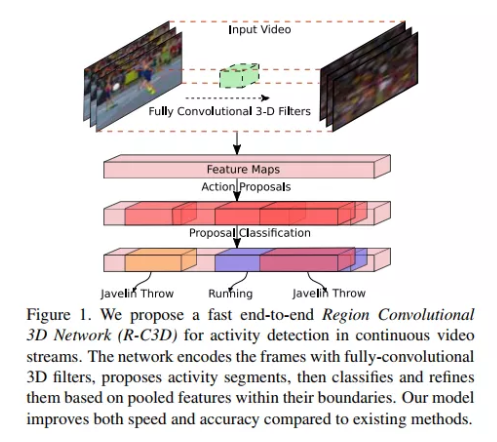 发表了文章
2022-04-23 15:47:24
发表了文章
2022-04-23 15:47:24
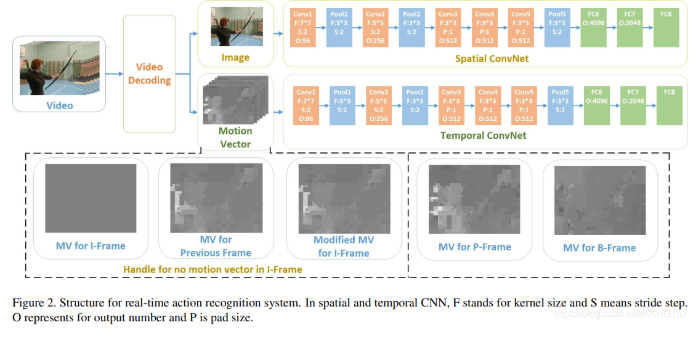 发表了文章
2022-04-23 15:39:33
发表了文章
2022-04-23 15:39:33
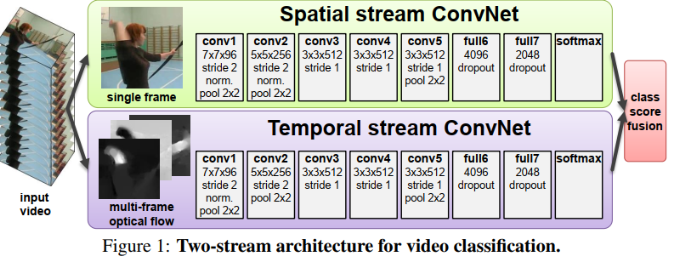 发表了文章
2022-04-23 15:31:08
发表了文章
2022-04-23 15:29:49
发表了文章
2022-04-23 15:21:58
发表了文章
2022-04-23 15:15:30
发表了文章
2022-04-23 15:13:11
发表了文章
2022-04-25
发表了文章
2022-04-25
发表了文章
2022-04-25
发表了文章
2022-04-25
发表了文章
2022-04-25
发表了文章
2022-04-25
发表了文章
2022-04-25
发表了文章
2022-04-25
发表了文章
2022-04-25
发表了文章
2022-04-25
发表了文章
2022-04-25
发表了文章
2022-04-25
发表了文章
2022-04-25
发表了文章
2022-04-25
发表了文章
2022-04-25
发表了文章
2022-04-25
发表了文章
2022-04-25
发表了文章
2022-04-25
发表了文章
2022-04-25
发表了文章
2022-04-25
发表了文章
2022-04-23 15:31:08
发表了文章
2022-04-23 15:29:49
发表了文章
2022-04-23 15:21:58
发表了文章
2022-04-23 15:15:30
发表了文章
2022-04-23 15:13:11
发表了文章
2022-04-25
发表了文章
2022-04-25
发表了文章
2022-04-25
发表了文章
2022-04-25
发表了文章
2022-04-25
发表了文章
2022-04-25
发表了文章
2022-04-25
发表了文章
2022-04-25
发表了文章
2022-04-25
发表了文章
2022-04-25
发表了文章
2022-04-25
发表了文章
2022-04-25
发表了文章
2022-04-25
发表了文章
2022-04-25
发表了文章
2022-04-25
发表了文章
2022-04-25
发表了文章
2022-04-25
发表了文章
2022-04-25
发表了文章
2022-04-25
发表了文章
2022-04-25





