

勋章







我关注的人
粉丝



技术能力
-
Python
初级
能力说明:
了解Python语言的基本特性、编程环境的搭建、语法基础、算法基础等,了解Python的基本数据结构,对Python的网络编程与Web开发技术具备初步的知识,了解常用开发框架的基本特性,以及Python爬虫的基础知识。
-
-
 Apsara Clouder云计算专项技能认证:云服务器ECS入门
获得于2023-02-01 22:02:41
Apsara Clouder云计算专项技能认证:云服务器ECS入门
获得于2023-02-01 22:02:41
-
将不定期更新关于机器学习、强化学习、数据挖掘以及NLP等领域相关知识
-
发表了文章 2023-02-22
推荐系统[二]:召回算法超详细讲解[召回模型演化过程、召回模型主流常见算法(DeepMF_TDM_Airbnb Embedding_Item2vec等)、召回路径简介、多路召回融合]
推荐系统[二]:召回算法超详细讲解[召回模型演化过程、召回模型主流常见算法(DeepMF_TDM_Airbnb Embedding_Item2vec等)、召回路径简介、多路召回融合]
-
发表了文章 2023-02-21
推荐系统[一]:超详细知识介绍,一份完整的入门指南,解答推荐系统相关算法流程、衡量指标和应用,以及如何使用jieba分词库进行相似推荐
推荐系统[一]:超详细知识介绍,一份完整的入门指南,解答推荐系统相关算法流程、衡量指标和应用,以及如何使用jieba分词库进行相似推荐
-
发表了文章 2023-02-15
基于文心大模型套件ERNIEKit实现文本匹配算法,模块化方便应用落地
文心大模型开发套件ERNIEKit,面向NLP工程师,提供全流程大模型开发与部署工具集,端到端、全方位发挥大模型效能。
-
发表了文章 2023-02-15
特定领域知识图谱融合方案:学以致用-问题匹配鲁棒性评测比赛验证【四】
文本匹配任务在自然语言处理中是非常重要的基础任务之一,一般研究两段文本之间的关系。有很多应用场景;如信息检索、问答系统、智能对话、文本鉴别、智能推荐、文本数据去重、文本相似度计算、自然语言推理、问答系统、信息检索等,但文本匹配或者说自然语言处理仍然存在很多难点。这些自然语言处理任务在很大程度上都可以抽象成文本匹配问题,比如信息检索可以归结为搜索词和文档资源的匹配,问答系统可以归结为问题和候选答案的匹配,复述问题可以归结为两个同义句的匹配。
-
发表了文章 2023-02-15
特定领域知识图谱融合方案:文本匹配算法之预训练Simbert、ERNIE-Gram单塔模型等诸多模型【三】
文本匹配任务在自然语言处理中是非常重要的基础任务之一,一般研究两段文本之间的关系。有很多应用场景;如信息检索、问答系统、智能对话、文本鉴别、智能推荐、文本数据去重、文本相似度计算、自然语言推理、问答系统、信息检索等,但文本匹配或者说自然语言处理仍然存在很多难点。这些自然语言处理任务在很大程度上都可以抽象成文本匹配问题,比如信息检索可以归结为搜索词和文档资源的匹配,问答系统可以归结为问题和候选答案的匹配,复述问题可以归结为两个同义句的匹配。
-
发表了文章 2023-02-06
2023计算机领域顶会(A类)以及ACL 2023自然语言处理(NLP)研究子方向领域汇总
2023年的计算语言学协会年会(ACL 2023)共包含26个领域,代表着当前前计算语言学和自然语言处理研究的不同方面。每个领域都有一组相关联的关键字来描述其潜在的子领域, 这些子领域并非排他性的,它们只描述了最受关注的子领域,并希望能够对该领域包含的相关类型的工作提供一些更好的想法。
-
发表了文章 2023-02-01
特定领域知识图谱融合方案:文本匹配算法(Simnet、Simcse、Diffcse)
文本匹配任务在自然语言处理中是非常重要的基础任务之一,一般研究两段文本之间的关系。有很多应用场景;如信息检索、问答系统、智能对话、文本鉴别、智能推荐、文本数据去重、文本相似度计算、自然语言推理、问答系统、信息检索等,但文本匹配或者说自然语言处理仍然存在很多难点。这些自然语言处理任务在很大程度上都可以抽象成文本匹配问题,比如信息检索可以归结为搜索词和文档资源的匹配,问答系统可以归结为问题和候选答案的匹配,复述问题可以归结为两个同义句的匹配。
-
发表了文章 2023-01-30
NLP知识图谱项目合集(信息抽取、文本分类、图神经网络、性能优化等)
NLP知识图谱项目合集(信息抽取、文本分类、图神经网络、性能优化等)
-
发表了文章 2023-01-18
特定领域知识图谱(Domain-specific KnowledgeGraph:DKG)融合方案:技术知识前置【一】-文本匹配算法、知识融合学术界方案、知识融合业界落地方案、算法测评KG生产质量保障
本项目主要围绕着特定领域知识图谱(Domain-specific KnowledgeGraph:DKG)融合方案:技术知识前置【一】-文本匹配算法、知识融合学术界方案、知识融合业界落地方案、算法测评KG生产质量保障讲解了文本匹配算法的综述,从经典的传统模型到孪生神经网络“双塔模型”再到预训练模型以及有监督无监督联合模型,期间也涉及了近几年前沿的对比学习模型,之后提出了文本匹配技巧提升方案,最终给出了DKG的落地方案。这边主要以原理讲解和技术方案阐述为主,之后会慢慢把项目开源出来,一起共建KG,从知识抽取到知识融合、知识推理、质量评估等争取走通完整的流程。
-
发表了文章 2023-01-05
基于ERNIELayout&pdfplumber-UIE的多方案学术论文信息抽取
基于ERNIELayout&pdfplumber-UIE的多方案学术论文信息抽取,小样本能力强悍,OCR、版面分析、信息抽取一应俱全。
-
发表了文章 2022-12-12
卡塔尔世界杯出现了半自动越位识别技术、动作轨迹捕捉等黑科技。
卡塔尔世界杯出现了半自动越位识别技术、动作轨迹捕捉等黑科技。
-
发表了文章 2022-12-03
[信息抽取]基于ERNIE3.0的多对多信息抽取算法:属性关系抽取
本项目讲解了基于ERNIE信息抽取技术,对属性和关系的抽取涉及多对多抽取,主要是使用可ERNIEKIT组件,整体效果非常不错,当然追求小样本学习的可以参考之前UIE项目或者去官网看看paddlenlp最新的更新,对训练和部署进行了提速。
-
发表了文章 2022-12-02
PGL图学习项目合集&数据集分享&技术归纳业务落地技巧[系列十]
本项目对PGL图学习系列项目进行整合方便大家后续学习,同时对图学习相关技术和业务落地侧进行归纳总结,以及对图网络开放数据集很多学者和机构发布了许多与图相关的任务。
-
发表了文章 2022-11-30
PGL图学习之基于UniMP算法的论文引用网络节点分类任务[系列九]
PGL图学习之基于UniMP算法的论文引用网络节点分类任务[系列九]
-
发表了文章 2022-11-29
PGL图学习之基于GNN模型新冠疫苗任务[系列九]
13.PGL图学习之基于GNN模型新冠疫苗任务[系列九]
-
发表了文章 2022-11-28
PGL图学习之项目实践(UniMP算法实现论文节点分类、新冠疫苗项目实战,助力疫情)[系列九]
本项目讲了论文节点分类任务和新冠疫苗任务,并在论文节点分类任务中对代码进行详细讲解。PGL八九系列的项目耦合性比较大,也花了挺久时间研究希望对大家有帮助。
-
发表了文章 2022-11-27
图神经网络之预训练大模型结合:ERNIESage在链接预测任务应用
通过以上两个版本的模型代码简单的讲解,我们可以知道他们的不同点,其实主要就是在消息传递机制的部分有所不同。ERNIESageV1版本只作用在text graph的节点上,在传递消息(Send阶段)时只考虑了邻居本身的文本信息;而ERNIESageV2版本则作用在了边上,在Send阶段同时考虑了当前节点和其邻居节点的文本信息,达到更好的交互效果。
-
发表了文章 2022-11-26
PGL图学习之图神经网络ERNIESage、UniMP进阶模型[系列八]
通过以上两个版本的模型代码简单的讲解,可以知道他们的不同点,其实主要就是在消息传递机制的部分有所不同。ERNIESageV1版本只作用在text graph的节点上,在传递消息(Send阶段)时只考虑了邻居本身的文本信息;而ERNIESageV2版本则作用在了边上,在Send阶段同时考虑了当前节点和其邻居节点的文本信息,达到更好的交互效果。
-
发表了文章 2022-11-25
PGL图学习之图神经网络GraphSAGE、GIN图采样算法[系列七]
PGL图学习之图神经网络GraphSAGE、GIN图采样算法[系列七]
-
发表了文章 2022-11-24
PGL图学习之图神经网络GNN模型GCN、GAT[系列六]
本次项目讲解了图神经网络的原理并对GCN、GAT实现方式进行讲解,最后基于PGL实现了两个算法在数据集Cora、Pubmed、Citeseer的表现,在引文网络基准测试中达到了与论文同等水平的指标。 目前的数据集样本节点和边都不是很大,下个项目将会讲解面对亿级别图应该如何去做。
-
发表了文章 2022-11-23
PGL图学习之图游走类metapath2vec模型[系列五]
介绍了异质图,利用pgl对metapath2vec、metapath2vec 进行了实现,并给出了多个框架版本的demo满足个性化需求 metapath2vec是一种用于异构网络中表示学习的算法框架,其中包含多种类型的节点和链接。给定异构图,metapath2vec 算法首先生成基于元路径的随机游走,然后使用 skipgram 模型训练语言模型。基于 PGL重现了 metapath2vec 算法,用于可扩展的表示学习。
-
发表了文章 2022-11-22
Paddle Graph Learning (PGL)图学习之图游走类模型[系列四]
6.Paddle Graph Learning (PGL)图学习之图游走类模型[系列四]
-
发表了文章 2022-11-21
图学习【参考资料2】-知识补充与node2vec代码注解
1. 回顾并总结了图的基本概念。 2. 学习思考算法实现的代码思路--Node2Vec的实现以及RandomWalk的实现。 3. 对源码阅读能力的提升。
-
发表了文章 2022-11-20
图学习初探Paddle Graph Learning 构建属于自己的图【系列三】
4.图学习初探Paddle Graph Learning 构建属于自己的图【系列三】
-
发表了文章 2022-11-20
词向量word2vec(图学习参考资料1)
词向量word2vec(图学习参考资料1)
-
发表了文章 2022-11-19
图机器学习(GML)&图神经网络(GNN)原理和代码实现(前置学习系列二)
现在已经覆盖了图的介绍,图的主要类型,不同的图算法,在Python中使用Networkx来实现它们,以及用于节点标记,链接预测和图嵌入的图学习技术,最后讲了GNN分类应用以及未来发展方向!
-
发表了文章 2022-11-18
关于图计算&图学习的基础知识概览:前置知识点学习(Paddle Graph L)系列【一】
1.关于图计算&图学习的基础知识概览:前置知识点学习(Paddle Graph L)系列【一】
-
发表了文章 2022-11-17
基线提升至96.45%:2022 司法杯犯罪事实实体识别+数据蒸馏+主动学习
5.基线提升至96.45%:2022 司法杯犯罪事实实体识别+数据蒸馏+主动学习
-
发表了文章 2022-11-16
NLP领域任务如何选择合适预训练模型以及选择合适的方案【规范建议】
4.NLP领域任务如何选择合适预训练模型以及选择合适的方案【规范建议】
-
发表了文章 2022-11-15
主动学习(Active Learning)简介综述汇总以及主流技术方案
3.主动学习(Active Learning)简介综述汇总以及主流技术方案
-
发表了文章 2022-11-14
知识蒸馏相关技术【模型蒸馏、数据蒸馏】以ERNIE-Tiny为例
2.知识蒸馏相关技术【模型蒸馏、数据蒸馏】以ERNIE-Tiny为例
-
发表了文章 2022-11-13
Paddle模型性能分析工具Profiler:定位瓶颈点、优化程序、提升性能
1.Paddle模型性能分析工具Profiler:定位瓶颈点、优化程序、提升性能
-
发表了文章 2022-11-12
在数据增强、蒸馏剪枝下ERNIE3.0分类模型性能提升
在数据增强、蒸馏剪枝下ERNIE3.0分类模型性能提升
-
发表了文章 2022-11-11
应用实践:Paddle分类模型大集成者[PaddleHub、Finetune、prompt]
应用实践:Paddle分类模型大集成者[PaddleHub、Finetune、prompt]
-
发表了文章 2022-11-11
应用实践:Paddle分类模型大集成者[PaddleHub、Finetune、prompt]
应用实践:Paddle分类模型大集成者[PaddleHub、Finetune、prompt]
-
发表了文章 2022-11-11
小样本学习在文心ERNIE3.0多分类任务应用--提示学习
小样本学习在文心ERNIE3.0多分类任务应用--提示学习
-
发表了文章 2022-11-10
推广TrustAI可信分析:通过提升数据质量来增强在ERNIE模型下性能
推广TrustAI可信分析:通过提升数据质量来增强在ERNIE模型下性能
-
发表了文章 2022-11-09
快递单中抽取关键信息【一】----基于BiGRU+CR+预训练的词向量优化
快递单中抽取关键信息【一】----基于BiGRU+CR+预训练的词向量优化
-
发表了文章 2022-11-09
快递单信息抽取【三】--五条标注数据提高准确率,仅需五条标注样本,快速完成快递单信息任务
快递单信息抽取【三】--五条标注数据提高准确率,仅需五条标注样本,快速完成快递单信息任务
-
发表了文章 2022-11-08
快递单信息抽取【二】基于ERNIE1.0至ErnieGram + CRF预训练模型
快递单信息抽取【二】基于ERNIE1.0至ErnieGram + CRF预训练模型
-
发表了文章 2022-11-08
基于Ernie-3.0 CAIL2019法研杯要素识别多标签分类任务
基于Ernie-3.0 CAIL2019法研杯要素识别多标签分类任务
-
发表了文章 2022-11-07
UIE_Slim满足工业应用场景,解决推理部署耗时问题,提升效能。
UIE_Slim满足工业应用场景,解决推理部署耗时问题,提升效能。
-
发表了文章 2022-11-04
Paddlenlp之UIE模型实战实体抽取任务【打车数据、快递单】
Paddlenlp之UIE模型实战实体抽取任务【打车数据、快递单】
-
发表了文章 2022-11-04
PaddleNLP通用信息抽取技术UIE【一】产业应用实例:信息抽取{实体关系抽取、中文分词、精准实体标。情感分析等}、文本纠错、问答系统、闲聊机器人、定制训练
PaddleNLP通用信息抽取技术UIE【一】产业应用实例:信息抽取{实体关系抽取、中文分词、精准实体标。情感分析等}、文本纠错、问答系统、闲聊机器人、定制训练
-
发表了文章 2022-11-03
PaddleNLP基于ERNIR3.0文本分类以中医疗搜索检索词意图分类(KUAKE-QIC)为例【多分类(单标签)】
文本分类任务是自然语言处理中最常见的任务,文本分类任务简单来说就是对给定的一个句子或一段文本使用文本分类器进行分类。文本分类任务广泛应用于长短文本分类、情感分析、新闻分类、事件类别分类、政务数据分类、商品信息分类、商品类目预测、文章分类、论文类别分类、专利分类、案件描述分类、罪名分类、意图分类、论文专利分类、邮件自动标签、评论正负识别、药物反应分类、对话分类、税种识别、来电信息自动分类、投诉分类、广告检测、敏感违法内容检测、内容安全检测、舆情分析、话题标记等各类日常或专业领域中。 文本分类任务可以根据标签类型分为**多分类(multi class)、多标签(multi label)、层次分类
-
发表了文章 2022-11-03
PaddleNLP基于ERNIR3.0文本分类以CAIL2018-SMALL数据集罪名预测任务为例【多标签】
文本分类任务是自然语言处理中最常见的任务,文本分类任务简单来说就是对给定的一个句子或一段文本使用文本分类器进行分类。文本分类任务广泛应用于长短文本分类、情感分析、新闻分类、事件类别分类、政务数据分类、商品信息分类、商品类目预测、文章分类、论文类别分类、专利分类、案件描述分类、罪名分类、意图分类、论文专利分类、邮件自动标签、评论正负识别、药物反应分类、对话分类、税种识别、来电信息自动分类、投诉分类、广告检测、敏感违法内容检测、内容安全检测、舆情分析、话题标记等各类日常或专业领域中。 文本分类任务可以根据标签类型分为**多分类(multi class)、多标签(multi label)、层次分类
-
发表了文章 2022-11-02
PaddleNLP基于ERNIR3.0文本分类:WOS数据集为例(层次分类)
文本分类任务是自然语言处理中最常见的任务,文本分类任务简单来说就是对给定的一个句子或一段文本使用文本分类器进行分类。文本分类任务广泛应用于长短文本分类、情感分析、新闻分类、事件类别分类、政务数据分类、商品信息分类、商品类目预测、文章分类、论文类别分类、专利分类、案件描述分类、罪名分类、意图分类、论文专利分类、邮件自动标签、评论正负识别、药物反应分类、对话分类、税种识别、来电信息自动分类、投诉分类、广告检测、敏感违法内容检测、内容安全检测、舆情分析、话题标记等各类日常或专业领域中。 文本分类任务可以根据标签类型分为**多分类(multi class)、多标签(multi label)、层次分类
-
发表了文章 2022-11-02
PaddleNLP--UIE--小样本快速提升性能(含doccona标注
需求跨领域跨任务:领域之间知识迁移难度高,如通用领域知识很难迁移到垂类领域,垂类领域之间的知识很难相互迁移;存在实体、关系、事件等不同的信息抽取任务需求。 - 定制化程度高:针对实体、关系、事件等不同的信息抽取任务,需要开发不同的模型,开发成本和机器资源消耗都很大。 - 训练数据无或很少:部分领域数据稀缺,难以获取,且领域专业性使得数据标注门槛高。
-
发表了文章 2022-11-01
信息抽取UIE(二)--小样本快速提升性能(含doccona标注
需求跨领域跨任务:领域之间知识迁移难度高,如通用领域知识很难迁移到垂类领域,垂类领域之间的知识很难相互迁移;存在实体、关系、事件等不同的信息抽取任务需求。 - 定制化程度高:针对实体、关系、事件等不同的信息抽取任务,需要开发不同的模型,开发成本和机器资源消耗都很大。 - 训练数据无或很少:部分领域数据稀缺,难以获取,且领域专业性使得数据标注门槛高。
-
发表了文章 2022-11-01
AiTrust下预训练和小样本学习在中文医疗信息处理挑战榜CBLUE表现
可以看出在样本量还算大的情况下,预训练方式更有优势(准确率略高一点且训练更快一些),通过AITrust可信分析:稀疏数据筛选、脏数据清洗、数据增强等方案看到模型性能都有提升; 这里提升不显著的原因是,这边没有对筛选出来数据集进行标注:因为没有特定背景知识就不花时间操作了,会导致仍会有噪声存在。相信标注完后能提升3-5%点 1. 对于大多数任务,我们使用预训练模型微调作为首选的文本分类方案:准确率较高,训练较快 2. 提示学习(Prompt Learning)适用于标注成本高、标注样本较少的文本分类场景。在小样本场景中,相比于预训练模型微调学习,提示学习能取得更好的效果。对于标注样本充足、标
-
 发表了文章
2025-10-22
发表了文章
2025-10-22
AI Compass前沿速览:ChatGPT Atlas、Claude Code、Haiku 4.5、Veo 3.1、nanochat、DeepSeek-OCR
-
发表了文章
2025-09-26
AI Compass前沿速览:Qwen3-Max、Mixboard、Qwen3-VL、Audio2Face、Vidu Q2 AI视频生成模型、Qwen3-LiveTranslate-全模态同传大模型
-
发表了文章
2025-09-23
前沿速览:TrafficVLM、DeepSeek-Terminus、Qwen3-Omni、蚂蚁百灵、Wan2.2-Animate、Qianfan-VL
-
发表了文章
2025-09-18
AI Compass前沿速览:Nano Bananary、MCP Registry、通义DeepResearch 、VoxCPM、InternVLA·M1具身机器人
-
发表了文章
2025-09-17
AI Compass前沿速览:IndexTTS2–B站、HuMo、Stand-In视觉生成框架、Youtu-GraphRAG、MobileLLM-R1–Meta、PP-OCRv5
-
发表了文章
2025-09-08
AI Compass前沿速览:字节Seedream4.0、Qwen3-Max、EmbeddingGemma、OneCAT多模态、rStar2-Agent
-
发表了文章
2025-09-02
AI Compass前沿速览:PixVerse V5、gpt-realtime、Grok Code Fast、HunyuanVideo、OmniHuman-1.5、字节WaverAI视频、MiniCPM 4.5等
-
发表了文章
2025-08-28
AI Compass前沿速览:Jetson Thor英伟达AI计算、Gemini 2.5 Flash Image、Youtu腾讯智能体框架、Wan2.2-S2V多模态视频生成、SpatialGen 3D场景生成模型
-
发表了文章
2025-08-22
AI Compass前沿速览:Qoder Agentic编程、vivo Vision头显、AIRI桌面伴侣、RM-Gallery奖励模型平台
-
发表了文章
2025-08-07
AI Compass前沿速览:Claude Opus 4.1、MiniMax-Speech 2.5、Qwen-Flash
-
发表了文章
2025-08-06
文生绘动 Agent:从词语到动态影像,言出即成,你的AI动画创作伙伴
-
发表了文章
2025-07-25
AI Compass前沿速览:Qwen3模型升级、字节GR-3机器人、TRAE SOLO、JoyAgent OxyGent京东智能体框架、智谱Z.ai炫酷PPT制作
-
发表了文章
2025-07-20
AI-Compass 强化学习模块:理论到实战完整RL技术生态,涵盖10+主流框架、多智能体算法、游戏AI与金融量化应用
-
发表了文章
2025-07-20
AI-Compass LLM合集-多模态模块:30+前沿大模型技术生态,涵盖GPT-4V、Gemini Vision等国际领先与通义千问VL等国产优秀模型
-
发表了文章
2025-07-20
AI-Compass DeepSearch深度搜索生态:集成阿里ZeroSearch、字节DeerFlow、MindSearch等前沿平台,实现超越传统关键词匹配的智能信息检索革命
-
发表了文章
2025-07-20
AI-Compass GraphRAG技术生态:集成微软GraphRAG、蚂蚁KAG等主流框架,融合知识图谱与大语言模型实现智能检索生成
-
发表了文章
2025-07-20
AI-Compass LLM推理框架+部署生态:整合vLLM、SGLang、LMDeploy等顶级加速框架,涵盖本地到云端全场景部署
-
发表了文章
2025-07-20
AI-Compass LLM评估框架:CLiB中文大模型榜单、OpenCompass司南、RAGas、微软Presidio等构建多维度全覆盖评估生态系统
-
发表了文章
2025-07-20
AI-Compass RLHF人类反馈强化学习技术栈:集成TRL、OpenRLHF、veRL等框架,涵盖PPO、DPO算法实现大模型人类价值对齐
-
发表了文章
2025-07-20
AI-Compass LLM训练框架生态:整合ms-swift、Unsloth、Megatron-LM等核心框架,涵盖全参数/PEFT训练与分布式优化

-
 回答了问题
2023-03-03
回答了问题
2023-03-03
全栈工程师对于开发者而言是更好的出路吗?
全栈工程师的优点与价值 其实在我们了解了全栈工程师的概念后,就很容易联想到其优点: 减少了沟通时间,降低了沟通成本,提高了开发效率。 由于前后端,甚至产品的业务,都有一个人来负责完成,不需要沟通,各个端的配合是100%的默契配合,这从很大程度上提高了开发效率。 虽然全栈工程师的知识面较广,能够完成一些前端及后端的开发工作,但全栈开发师的厉害之处并不是他掌握很多知识,可以一个人干多份工作。 而他真正的价值在于处理问题的时候拥有全局性思维。 现在科技日新月异,web前端不再是从前切个图用个jQuery上个AJAX兼容各种浏览器那么简单。现代的Web前端,你需要用到模块化开发、多屏兼容、MVC,各种复杂的交互与优化,甚至你需要用到Node.js来协助前端的开发。一个现代化的项目,是一个非常复杂的构成,我们需要一个人来掌控全局,他不需要是各种技术的资深专家,但他需要熟悉到各种技术。对于一个团队特别是互联网企业来说,有一个全局性思维的人显得尤其重要,这个时候也就彰显了全栈开发工程师的价值。赞0 踩0 评论0 -
回答了问题
2023-03-03
开源社区该如何建立“可控开源”体系?
1.可控开源体系 开源软件相比于闭源软件,能够获得更多的开发者和关注,社区可以向开源项目提交代码,从而针对所遇见的问题提供相应的解决方案。相比于商业公司,这样能够找到的 Bug 更多,更好。这样的认知,我将其称之为「开源的机制安全」,也就是说,这个机制是可以让整个软件更加的安全。 但是,机制安全并不能够保证软件足够的安全。机制安全能够成立的前提有很多,比如: 开源项目的团队会接受来自社区的贡献:虽然不少项目都开源了,但是很少合并来自社区的贡献,这使得该软件虽然开源了,但是实际上并没有享受到开源软件所带来的机制安全。 开源项目的团队获取到足够多的社区贡献:相比于一些知名的开源项目,你所使用、贡献的项目可能并没有足够多的开发者来为其贡献代码,在发现 Bug 的方面,因为没有足够多的人,也就导致了相对来说,不够安全。 此外,开源这件事在安全层面来看,就是一把双刃剑。固然你通过开源获取到了更多的贡献,但同时因为你将测试从黑盒测试转为了白盒测试。开发者只需要阅读已经开源的代码,就可以从中发现漏洞并使用漏洞。 那么: 开源社区需要为开源软件的安全负责吗? 为了开源生态能更好的发展,应该如何保证“开源可控”? 举个简单例子: 这段代码单独来看是没有任何问题的,因为它在清理完磁盘队列后会设置pf->disk->queue=null,如果作为一个静态代码审核者,从中肯定看不出任何问题。作为OS内核核心代码,做完整的动态测试是不可能的,因此这段代码是否有问题只能是在开源软件使用者报错的时候才能被发现。但是pf_detect()和另外一个函数pf_uexit()这两个函数,在queue指针为空后的时候被调用,它们将在不检查指针状态的情况下对pf->disk->queue进行操作,从而导致空指针取消引用,导致系统中的相关核心进程崩溃,甚至引起CORE PANIC。原本只有pf_uexit中会做清理,因此不会存在空指针操作的问题。当引入这个补丁后,出现了多次调用清理的可能,因此就可能触发空指针问题。 根据上面的例子,只要提交一个可以触发在该指针为空的时候调用这两个函数的补丁,就很容易会激活这个原本不会造成太大影响的代码缺陷,导致大的故障。别有用心的伪代码贡献者就可以利用这个以前并不会对系统造成多大影响的隐患,通过自己添加的看似无害的代码去主动激活这个隐患,从而造成很大的安全事故。此类的恶意代码攻击手段还有很多。 另外一个开源社区难以防范此类恶意代码攻击的原因是开源社区无法很好的对代码贡献者进行管控,因为理论上任何一个人都可以成为代码贡献者。而在开源社区里,实名制是十分困难的,建立代码贡献者溯源也十分困难。上面是论文中对于伪代码贡献者通过linux开源社区对于代码管理方面的漏洞进行的恶意攻击的示意图。其实我们讨论开源代码的不安全问题并不是为了因噎废食,而是需要找到解决这些问题的方法。中国的基础软件产业需要快速发展,依靠开源社区是一条必须走的捷径,这一点是毋庸置疑的。购买成熟的商业软件公司和直接使用开源代码进行二次开发,从本质上并无优劣之分,都是快速构建信创软件生态的好办法。 一方面是选择开源协议的问题,一方面是代码本身的安全问题。从代码安全方面我们有几条路可走,一条路是基于某个开源代码进行魔改,最终放弃开源代码,完全走向自主的闭源代码。这条路国内的一些大型企业在走。包括腾讯QQ的前身OICQ当年也是使用了大量的ICQ的代码的。华为的OPENGAUSS是基于PostgreSQL 9.2.4的,不过OPENGAUSS已经对代码进行了魔改,连PG的多进程架构都被改成了多线程架构。这种脱离社区代码的完全自主改造,是有成本和代价的,只有具有极强研发能力的企业才能在这条路上走的比较成功。目前我无法说华为的做法是正确的还是错误的,也许等OPENGAUSS 3.0出来后和PG 14比较一下,才能看出来这条路走的是否正确。当然这个正确也是基于时间的,如果华为能坚持走上数年,我想OPENGAUSS全面超过社区版的PG并非不可能。 除了魔改外,还有一条路就像红帽一样,依靠上游的开源社区来发展自己的软件。如果是这样,那么我们就要加强对开源代码的管控,通过自动化工具与人工核查的方法,对代码进行静态与动态分析,从而构建强大的开源代码安全管控能力。成为一家像红帽一样伟大的基于开源生态的软件公司。 可能有朋友要说了,我们既不是华为阿里这样的大厂,又没有强大的代码安全管控能力,我们只是一个开源软件产品的使用者。我们该怎么办呢?难道我们就不能使用开源软件了吗?答案当然是否定的,如果我们的羊圈不够牢固,那么我们就把羊圈修在城里吧,把自己的网络环境的安全搞搞好,增加通用安全防护的投入,启用更为严格的安全防护规章制度等,都是有效提升企业信息系统安全的好方法。作为最终用户,守住安全底线总还是需要的。一个连勒索病毒都会中的企业,其安全管控恐怕基本上等于空白了。 文章最后:上云能从一定程度上解决开源带来的安全性问题吗?,是可以一定程度缓解上述问题,这也是阿里做的好的地方,也是值得大家关注的点。赞1 踩0 评论0 -
回答了问题
2023-03-03
问答最高荣誉,乘风问答官招募中!每周积分活动、每月排位赛等权益专享!
积极参与赞0 踩0 评论0 -
回答了问题
2023-02-28
你使用过哪些云产品组合进行开发?
目前国内的云服务商中,阿里云、腾讯云、华为云是受关注最高的服务商,也是大量的中小型企业由原来的物理服务器转向了云服务器的首选云服务商。和传统的物理物理服务器相比,云服务器具有更安全、业务配置更快、选择更灵活、使用成本更低等优点。不管是用来建网站还搭建电子商务\游戏平台、各类APP\办公系统应用以及测试技术代码等都是非常方便的。 阿里云 一、阿里云服务器 阿里云服务器ECS(Elastic Compute Service)是阿里云提供的性能卓越、稳定可靠、弹性扩展的IaaS(Infrastructure as a Service)级别云计算服务。 二:阿里云服务器可以用来 1、企业官网或轻量的Web应用 网站初始阶段访问量小,只需要一台低配置的云服务器ECS实例即可运行Apache或Nginx等Web应用程序、数据库、存储文件等。随着网站发展,您可以随时升级ECS实例的配置,或者增加ECS实例数量,无需担心低配计算单元在业务突增时带来的资源不足。 2、多媒体以及高并发应用或网站 云服务器ECS与对象存储OSS搭配,对象存储OSS承载静态图片、视频或者下载包,进而降低存储费用。同时配合内容分发网络CDN和负载均衡SLB,可大幅减少用户访问等待时间、降低网络带宽费用以及提高可用性。 3、高I/O要求数据库 支持承载高I/O要求的数据库,如OLTP类型数据库以及NoSQL类型数据库。您可以使用较高配置的I/O优化型云服务器ECS,同时采用ESSD云盘,可实现高I/O并发响应和更高的数据可靠性。您也可以使用多台中等偏下配置的I/O优化型ECS实例,搭配负载均衡SLB,建设高可用底层架构。 4、访问量波动剧烈的应用或网站 某些应用,如抢红包应用、优惠券发放应用、电商网站和票务网站,访问量可能会在短时间内产生巨大的波动。您可以配合使用弹性伸缩,自动化实现在请求高峰来临前增加ECS实例,并在进入请求低谷时减少ECS实例。满足访问量达到峰值时对资源的要求,同时降低了成本。如果搭配负载均衡SLB,您还可以实现高可用应用架构。 5、大数据及实时在线或离线分析 云服务器ECS提供了大数据类型实例规格族,支持Hadoop分布式计算、日志处理和大型数据仓库等业务场景。由于大数据类型实例规格采用了本地存储的架构,云服务器ECS在保证海量存储空间、高存储性能的前提下,可以为云端的Hadoop集群、Spark集群提供更高的网络性能。 6、机器学习和深度学习等AI应用 通过采用GPU计算型实例,您可以搭建基于TensorFlow框架等的AI应用。此外,GPU计算型还可以降低客户端的计算能力要求,适用于图形处理、云游戏云端实时渲染、AR/VR的云端实时渲染等瘦终端场景。 二、腾讯云服务器 腾讯云服务器(Cloud Virtual Machine,CVM)为您提供安全可靠的弹性计算服务。 只需几分钟,您就可以在云端获取和启用 CVM,用于实现您的计算需求。随着业务需求的变化,您可以实时扩展或缩减计算资源。 参考链接:https://zhuanlan.zhihu.com/p/536187643 三、华为云 华为云服务器 弹性云服务器(Elastic Cloud Server,ECS)是由CPU、内存、操作系统、云硬盘组成的基础的计算组件。弹性云服务器创建成功后,您就可以像使用自己的本地PC或物理服务器一样,在云上使用弹性云服务器。 华为云服务器使用场景 1、网站应用 对CPU、内存、硬盘空间和带宽无特殊要求,对安全性、可靠性要求高,服务一般只需要部署在一台或少量的服务器上,一次投入成本少,后期维护成本低的场景。例如网站开发测试环境、小型数据库应用。 推荐使用通用型弹性云服务器,主要提供均衡的计算、内存和网络资源,适用于业务负载压力适中的应用场景,满足企业或个人普通业务搬迁上云需求。 2、企业电商 对内存要求高、数据量大并且数据访问量大、要求快速的数据交换和处理的场景。例如广告精准营销、电商、移动APP。 推荐使用内存优化型弹性云服务器,主要提供高内存实例,同时可以配置超高IO的云硬盘和合适的带宽。 3、图形渲染 对图像视频质量要求高、大内存,大量数据处理,I/O并发能力。可以完成快速的数据处理交换以及大量的GPU计算能力的场景。例如图形渲染、工程制图。 推荐使用GPU图形加速型弹性云服务器,G1型弹性云服务器基于NVIDIA Tesla M60硬件虚拟化技术,提供较为经济的图形加速能力。能够支持DirectX、OpenGL,可以提供最大显存1GiB、分辩率为4096×2160的图形图像处理能力。 4、数据分析 处理大容量数据,需要高I/O能力和快速的数据交换处理能力的场景。例如MapReduce 、Hadoop计算密集型。 推荐使用磁盘增强型弹性云服务器,主要适用于需要对本地存储上的极大型数据集进行高性能顺序读写访问的工作负载,例如:Hadoop分布式计算,大规模的并行数据处理和日志处理应用。主要的数据存储是基于HDD的存储实例,默认配置最高10GE网络能力,提供较高的PPS性能和网络低延迟。最大可支持24个本地磁盘、48个vCPU和384GiB内存。 5、高性能计算 高计算能力、高吞吐量的场景。例如科学计算、基因工程、游戏动画、生物制药计算和存储系统。 推荐使用高性能计算型弹性云服务器,主要使用在受计算限制的高性能处理器的应用程序上,适合要求提供海量并行计算资源、高性能的基础设施服务,需要达到高性能计算和海量存储,对渲染的效率有一定保障的场景。赞1 踩0 评论0 -
回答了问题
2023-02-28
Serverless在推进过程中会遇到什么样的挑战?该如何破局?
serverless最大的优势在于资源得到了更合理的利用: 1.快速迭代与部署 2.高并发、高弹性 3.稳定、可靠、安全 4.运维与成本控制 下面进行简单分析: 传统的购买服务器部署应用的方式,在没有使用的时候,服务器就被浪费掉了,对于我这种需要部署一些个人用的小规模应用的情况,买服务器非常的不合算,每天可能实际使用就几分钟,大部分时间都在空置。但是 serverless 是按照实际使用次数/时长来计费的,也就是说,不用的时候真正不花一分钱。所以我越来越多的使用 serverless 部署这些小规模应用,每天实际上使用的 CPU 时间加起来可能还不到一秒,这可以把我的使用成本压缩到几乎忽略不计的程度上。 1.更多人像我这样部署到 serverless 之后,总的服务器消耗就大幅度下降了,原本可能每个人都需要一台独立的服务器,现在上百个人可能实际上就只共享了一台服务器,但每个人都能有良好的用户体验。2.serverless 先天是高并发的,可以无限制的并发请求。当我自己购买服务器部署时,我需要自己在开发应用时解决并发问题,要么就是单线程同时只处理一个请求。3.serverless 开发的时候就不用管并发,我的代码只要能处理一个请求,那么就一定能同时创建无限的运行时来处理更多的请求。4. serverless 的高并发不需要在同一台物理服务器上运行,事实上可以跑在任意位置任意数量的物理服务器上,当我一份代码部署完成之后,用户访问时可以就近选择最近的节点,从而降低延迟,而对于单一物理服务器的传统部署,地球对面的用户访问起来就会非常痛苦。 因为每个请求都是在独立运行时里处理的,错误处理也可以变得很简单,很多不处理就会崩溃的地方真的可以不处理,崩就崩呗,反正就崩单一请求对应的运行时,对其他用户没影响。不像开发传统服务器应用,得尽可能不崩溃否则崩了还得远程上去重启进程。从这个角度来看 serverless 是轻量化应用的最优解决方案,成本更低,复杂度更低,用户体验更好。当然,方便的前提一定是更低的自由度,所以对于复杂的企业项目, serverless 仍然不能成为首选赞8 踩0 评论0 -
回答了问题
2023-02-28
2023,社区讨论聊什么?话题由你定!
我想要聊知识图谱应用落地,信息抽取、知识融合、关系推理在各个领域的落地应用,直至图数据库存储,构建基于知识图谱的搜索推荐应用。赞0 踩0 评论0 -
回答了问题
2023-02-28
ModelScope社区上线,怎么看待它在AIGC发展中起到的作用?
2022至今,从DALL-E2、 StableDiffusion等人工智能技术,到 ChatGPT等人工智能技术, AIGC领域在互联网上掀起了轩然大波,它那惊人的创作速度,让所有人都为之惊叹。业界曾经也有一个普遍的看法: AIGC绝不会是一种短暂的热点,它的基础技术和工业生态都在不断地迭代进步着。 首先是基本的算法建模,持续地进行突破和革新。例如 GAN、 Transformer、扩散模型等,其性能、稳定性和生成内容质量都在逐步提高。由于生成算法的不断发展, AIGC可以生成不同种类的内容和资料,如文字,代码,图像,语音,视频,三维物体等。 然后是预习模型,即基础模型,大模型,使 AIGC的技术实力发生了质的变化。以往各种生成模式都有,但由于使用门槛高、训练成本高、内容生成简单、质量差等原因,很难适应现实内容的要求。而该系统的前培训模式可以满足多任务、多场景和多功能需求,可以有效地克服上述问题。该技术还使 AIGC的应用和产业化程度得到了明显的提高, AIGC模式能够实现高品质的内容产出,从而使 AIGC模式既是“工厂”,又是“流水线”。因此,诸如谷歌,微软, OpenAI等公司都在积极地推进 AI技术的发展,将其推向了预先培训的模式。 另外多模态技术促进了 AIGC的内容多元化,使 AIGC的通用性能得到了提高。多模式技术实现了语言文字、图像、音视频等不同的信息之间的转换和产生。例如 CLIP,可以将文本与图片进行联系,例如把“狗”与“狗狗”相联系,同时具有大量的相关特性。这为文生图、文生视频等 AIGC技术的发展打下了良好的基础。 AIGC在消费互联网,工业互联网和社交价值等方面的不断升级迭代。当前 AIGC领域的内容类型不断丰富,内容质量不断提高,技术通用化和产业化程度不断提高, AIGC逐渐成为消费者网络领域的主流,出现了写作助手、 AI绘画、对话机器人、数字人等爆款级应用,支撑着传媒、电商、娱乐、影视等领域的内容需求。现在 AIGC也将其扩展到工业互联网,社会价值领域。 未来已经来临,让我们一起迎接 AIGC,迎接下一个新世纪的人工智能,未来一段时间,国产AIGC的产品更多的涌现出来,为中国的人工智能产业创造辉煌。赞2 踩0 评论0 -
回答了问题
2023-02-16
ChatGPT给国内外科技公司带来了怎样的机遇和威胁?
简单说一下,从NLP中的ChatGPT,以及AI绘画,在这个过程中AI绘画也得到了升级,从原来的二次元绘画到达了真人照片绘画。 在ChatGPT的光芒掩盖一切的这段时间,图像生成AI已经从从画画悄悄进化到了“画照片”。 回归上题“ChatGPT给国内外科技公司带来了怎样的机遇和威胁?” 我认为威胁便是国外先遣者“谷歌微软”的冲击,第一个吃螃蟹;机遇便是新兴技术发展和耦合,,就像有网友表示:AI聊天+AI照片,快进到AI网恋诈骗。应该图+文结合发挥新的商业模式别单独停留在一个点上,乃至后面的视频生成,可发展领域很多。或者说是革新原有很多领域!赞1 踩0 评论0
-
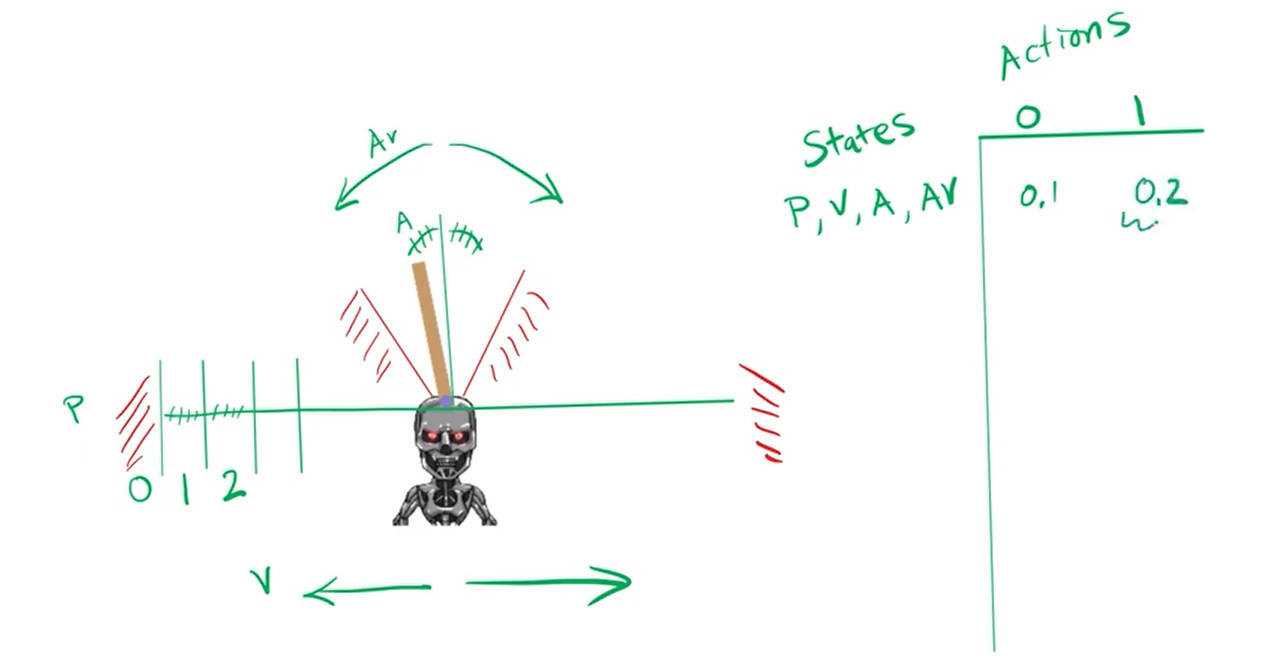 玩转平衡杆:Python强化学习教程训练你的终结者发布时间:2023-08-12 12:15:39 视频时长:9分17秒 播放量:840玩转平衡杆:Python强化学习教程训练你的终结者
玩转平衡杆:Python强化学习教程训练你的终结者发布时间:2023-08-12 12:15:39 视频时长:9分17秒 播放量:840玩转平衡杆:Python强化学习教程训练你的终结者 -
 创造无限美丽:探索AI美术生成器的惊人创作力量!发布时间:2023-08-12 11:33:31 视频时长:2分49秒 播放量:450创造无限美丽:探索AI美术生成器的惊人创作力量!
创造无限美丽:探索AI美术生成器的惊人创作力量!发布时间:2023-08-12 11:33:31 视频时长:2分49秒 播放量:450创造无限美丽:探索AI美术生成器的惊人创作力量! -
 如何通过AI绘画《Midjourney》赚取不菲佣金发布时间:2023-08-05 20:59:09 视频时长:8分24秒 播放量:4097如何通过AI绘画《Midjourney》赚取不菲佣金
如何通过AI绘画《Midjourney》赚取不菲佣金发布时间:2023-08-05 20:59:09 视频时长:8分24秒 播放量:4097如何通过AI绘画《Midjourney》赚取不菲佣金 -
 从零教学带你实现:人工智能AI玩转跳跳王JUMP KING发布时间:2023-07-27 22:41:29 视频时长:27分12秒 播放量:585从零教学带你实现:人工智能AI玩转跳跳王JUMP KING
从零教学带你实现:人工智能AI玩转跳跳王JUMP KING发布时间:2023-07-27 22:41:29 视频时长:27分12秒 播放量:585从零教学带你实现:人工智能AI玩转跳跳王JUMP KING -
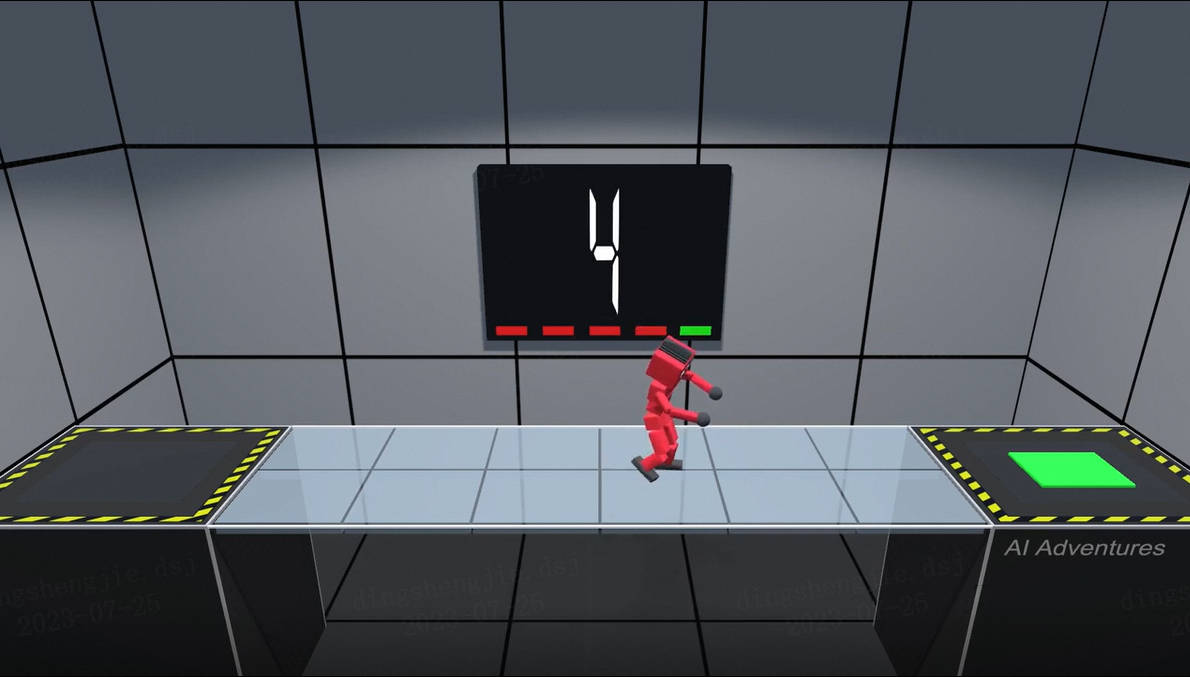 鱿鱼游戏:AI挑战爆破玻璃桥,看我的发布时间:2023-07-26 15:20:37 视频时长:3分26秒 播放量:783鱿鱼游戏:AI挑战爆破玻璃桥,看我的
鱿鱼游戏:AI挑战爆破玻璃桥,看我的发布时间:2023-07-26 15:20:37 视频时长:3分26秒 播放量:783鱿鱼游戏:AI挑战爆破玻璃桥,看我的 -
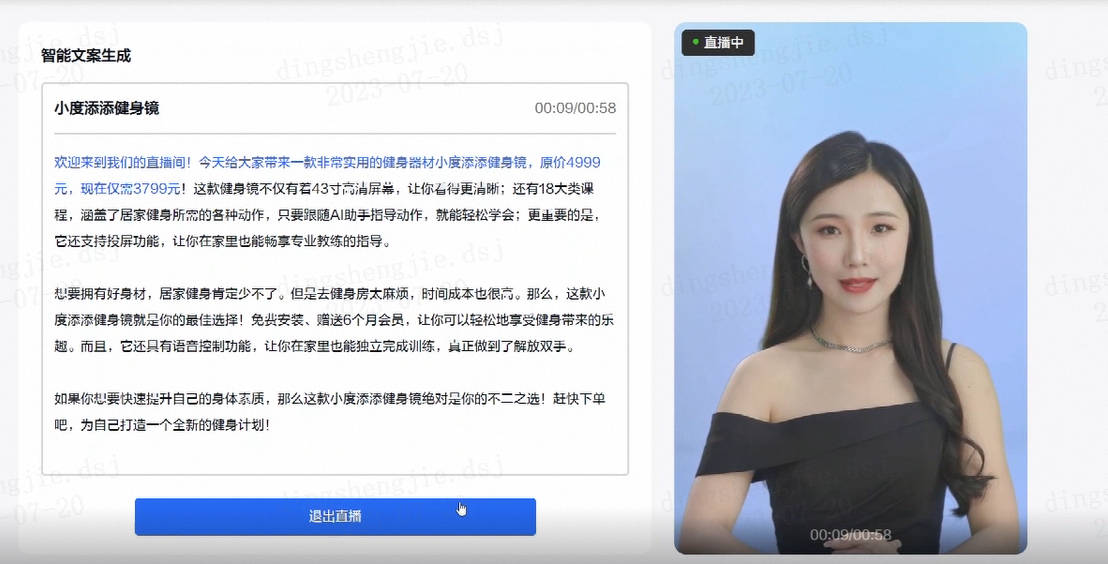 文心千帆:PPT 制作、数字人主播一键开播等数十种应用场景惊艳到我了,下面给出简介和使用指南,快去使用起来吧发布时间:2023-07-21 20:18:31 视频时长:4分5秒 播放量:389文心千帆:PPT 制作、数字人主播一键开播等数十种应用场景惊艳到我了,下面给出简介和使用指南,快去使用起来吧
文心千帆:PPT 制作、数字人主播一键开播等数十种应用场景惊艳到我了,下面给出简介和使用指南,快去使用起来吧发布时间:2023-07-21 20:18:31 视频时长:4分5秒 播放量:389文心千帆:PPT 制作、数字人主播一键开播等数十种应用场景惊艳到我了,下面给出简介和使用指南,快去使用起来吧 -
 基于Unity开发生存游戏发布时间:2023-07-20 19:25:00 视频时长:3分8秒 播放量:479基于Unity开发生存游戏
基于Unity开发生存游戏发布时间:2023-07-20 19:25:00 视频时长:3分8秒 播放量:479基于Unity开发生存游戏 -
 人工智能:基于深度强化学习的生存游戏终于大功告成,一起来拾荒探险吧发布时间:2023-07-19 12:45:10 视频时长:6分11秒 播放量:485人工智能:基于深度强化学习的生存游戏终于大功告成,一起来拾荒探险吧
人工智能:基于深度强化学习的生存游戏终于大功告成,一起来拾荒探险吧发布时间:2023-07-19 12:45:10 视频时长:6分11秒 播放量:485人工智能:基于深度强化学习的生存游戏终于大功告成,一起来拾荒探险吧 -
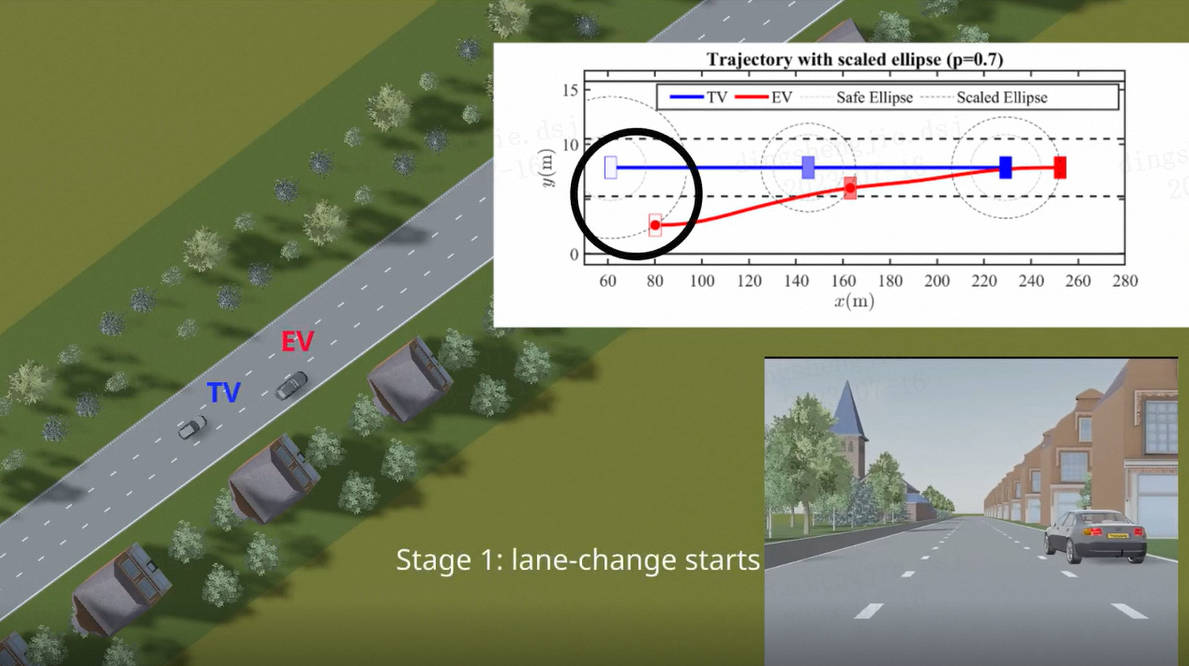 人工智能:利用逆强化学习训练AI自动驾驶发布时间:2023-07-16 23:18:55 视频时长:0分37秒 播放量:376人工智能:利用逆强化学习训练AI自动驾驶
人工智能:利用逆强化学习训练AI自动驾驶发布时间:2023-07-16 23:18:55 视频时长:0分37秒 播放量:376人工智能:利用逆强化学习训练AI自动驾驶 -
 深度强化学习:花费100个小时训练AI去挑战电子游戏boss,伤害不够技巧来凑,看我蛇皮走位发布时间:2023-07-14 23:34:34 视频时长:7分5秒 播放量:541深度强化学习:花费100个小时训练AI去挑战电子游戏boss,伤害不够技巧来凑,看我蛇皮走位
深度强化学习:花费100个小时训练AI去挑战电子游戏boss,伤害不够技巧来凑,看我蛇皮走位发布时间:2023-07-14 23:34:34 视频时长:7分5秒 播放量:541深度强化学习:花费100个小时训练AI去挑战电子游戏boss,伤害不够技巧来凑,看我蛇皮走位 -
 人工智能:恶搞游戏Flappy Bird-笨鸟先飞发布时间:2023-07-13 23:50:32 视频时长:3分22秒 播放量:398人工智能:恶搞游戏Flappy Bird-笨鸟先飞
人工智能:恶搞游戏Flappy Bird-笨鸟先飞发布时间:2023-07-13 23:50:32 视频时长:3分22秒 播放量:398人工智能:恶搞游戏Flappy Bird-笨鸟先飞 -
 深度强化学习:训练2.5w回合AI挑战夏日大闯关发布时间:2023-07-10 19:35:45 视频时长:4分37秒 播放量:501深度强化学习:训练2.5w回合AI挑战夏日大闯关
深度强化学习:训练2.5w回合AI挑战夏日大闯关发布时间:2023-07-10 19:35:45 视频时长:4分37秒 播放量:501深度强化学习:训练2.5w回合AI挑战夏日大闯关 -
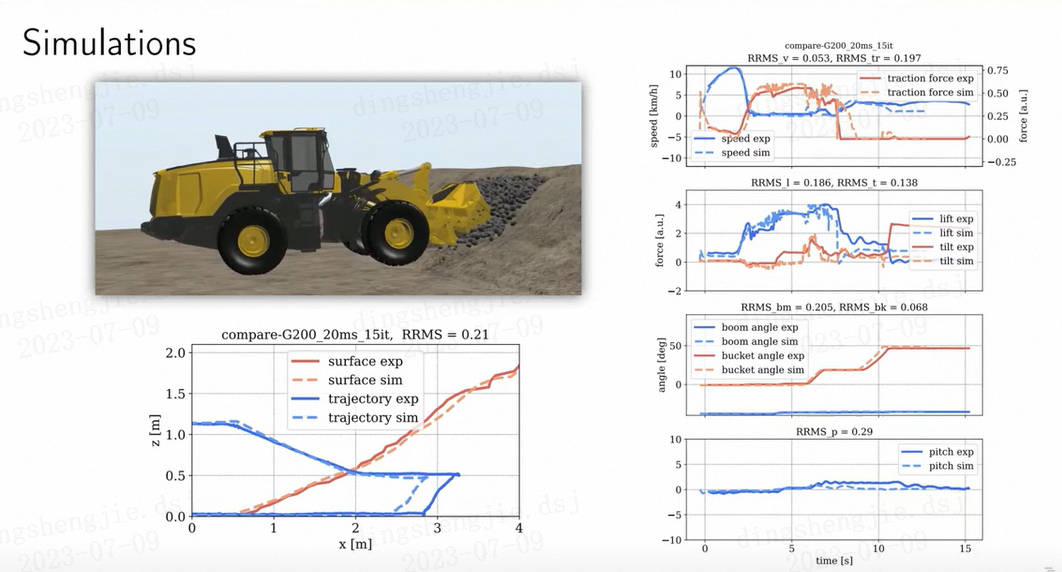 轮式装载机与可变形地形交互的仿真与现实差距研究对比发布时间:2023-07-10 19:24:17 视频时长:2分1秒 播放量:305轮式装载机与可变形地形交互的仿真与现实差距研究对比
轮式装载机与可变形地形交互的仿真与现实差距研究对比发布时间:2023-07-10 19:24:17 视频时长:2分1秒 播放量:305轮式装载机与可变形地形交互的仿真与现实差距研究对比 -
 基于深度强化学习训练人工智能完成射箭,看我百步穿杨发布时间:2023-07-08 15:56:13 视频时长:3分57秒 播放量:400基于深度强化学习训练人工智能完成射箭,看我百步穿杨
基于深度强化学习训练人工智能完成射箭,看我百步穿杨发布时间:2023-07-08 15:56:13 视频时长:3分57秒 播放量:400基于深度强化学习训练人工智能完成射箭,看我百步穿杨 -
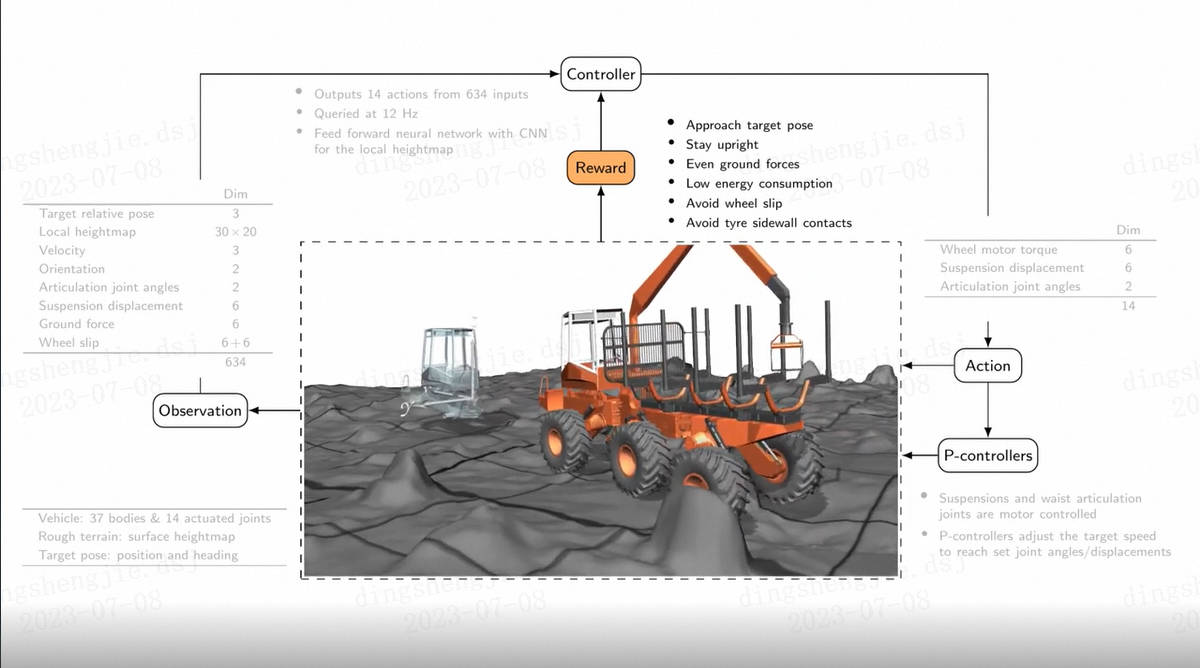 基于深度强化学习的挖掘机车辆控制,原理详解以及仿真展示发布时间:2023-07-08 15:31:21 视频时长:3分33秒 播放量:424基于深度强化学习的挖掘机车辆控制,原理详解以及仿真展示
基于深度强化学习的挖掘机车辆控制,原理详解以及仿真展示发布时间:2023-07-08 15:31:21 视频时长:3分33秒 播放量:424基于深度强化学习的挖掘机车辆控制,原理详解以及仿真展示 -
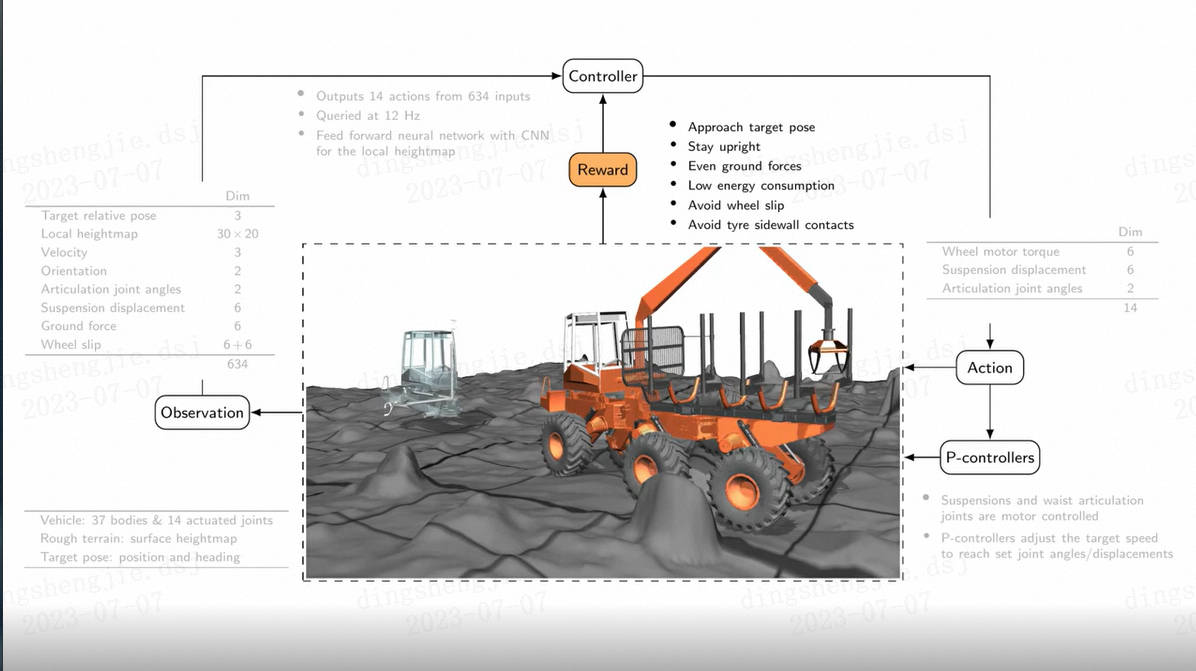 基于深度强化学习的挖掘机车辆控制,挑战在崎岖山地中工作任务发布时间:2023-07-07 12:52:02 视频时长:4分11秒 播放量:397基于深度强化学习的挖掘机车辆控制,挑战在崎岖山地中工作任务
基于深度强化学习的挖掘机车辆控制,挑战在崎岖山地中工作任务发布时间:2023-07-07 12:52:02 视频时长:4分11秒 播放量:397基于深度强化学习的挖掘机车辆控制,挑战在崎岖山地中工作任务 -
 基于深度强化学习的崎岖地形车辆控制,实现自动运行完成货物对接发布时间:2023-07-07 12:36:28 视频时长:2分39秒 播放量:288基于深度强化学习的崎岖地形车辆控制,实现自动运行完成货物对接
基于深度强化学习的崎岖地形车辆控制,实现自动运行完成货物对接发布时间:2023-07-07 12:36:28 视频时长:2分39秒 播放量:288基于深度强化学习的崎岖地形车辆控制,实现自动运行完成货物对接 -
 人工智能学会在南极洲生存(深度强化学习挑战拾荒游戏)发布时间:2023-07-04 23:18:19 视频时长:3分45秒 播放量:334人工智能学会在南极洲生存(深度强化学习挑战拾荒游戏)
人工智能学会在南极洲生存(深度强化学习挑战拾荒游戏)发布时间:2023-07-04 23:18:19 视频时长:3分45秒 播放量:334人工智能学会在南极洲生存(深度强化学习挑战拾荒游戏) -
 人工智能:基于深度强化学习AI掌握瓶子翻转挑战发布时间:2023-07-04 23:09:16 视频时长:4分59秒 播放量:404人工智能:基于深度强化学习AI掌握瓶子翻转挑战
人工智能:基于深度强化学习AI掌握瓶子翻转挑战发布时间:2023-07-04 23:09:16 视频时长:4分59秒 播放量:404人工智能:基于深度强化学习AI掌握瓶子翻转挑战 -
 人工智能基于强化学习训练AI逃脱陷阱脱离迷宫发布时间:2023-07-03 20:53:54 视频时长:3分24秒 播放量:394人工智能基于强化学习训练AI逃脱陷阱脱离迷宫
人工智能基于强化学习训练AI逃脱陷阱脱离迷宫发布时间:2023-07-03 20:53:54 视频时长:3分24秒 播放量:394人工智能基于强化学习训练AI逃脱陷阱脱离迷宫